
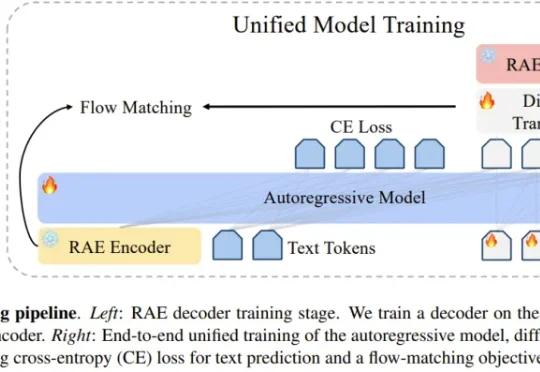
LeCun、谢赛宁团队重磅论文:RAE能大规模文生图了,且比VAE更好
LeCun、谢赛宁团队重磅论文:RAE能大规模文生图了,且比VAE更好编辑|Panda 在文生图模型的技术版图中,VAE 几乎已经成为共识。从 Stable Diffusion 到 FLUX,再到一系列扩散 Transformer,主流路线高度一致:先用 VAE 压缩视
来自主题: AI技术研报
6505 点击 2026-01-24 10:52
编辑|Panda 在文生图模型的技术版图中,VAE 几乎已经成为共识。从 Stable Diffusion 到 FLUX,再到一系列扩散 Transformer,主流路线高度一致:先用 VAE 压缩视

北邮最新综述探讨了文生图扩散模型的可控生成技术,总结了在文本条件之外引入新条件信号的方法,从任务和方法两个层面梳理了可控生成技术。

香港大学(The University of Hong Kong)与 Adobe Research 联合发布 Self-E(Self-Evaluating Model):一种无需预训练教师蒸馏、从零开始训练的任意步数文生图框架。其目标非常直接:让同一个模型在极少步数也能生成语义清晰、结构稳定的图像,同时在 50 步等常规设置下保持顶级质量,并且随着步数增加呈现单调提升。

一套 WPS 的 AIPPT 工作流长什么样?

Content in,Design out。

回顾 2025 年,如果问普通人对 AI 行业最深刻的印象是什么?答案依然是激烈的“参数战争”:有 DeepSeek、Gemini 3 等大模型的集体爆发,也有文生图、文生视频能力的持续惊艳。

抽奖式的生图体验,确实让很多设计师在尝鲜之后又默默打开了 Photoshop。于是乎,阿里千问团队再次出手,开源了一个叫 Qwen-Image-Layered 的模型,试图从底层逻辑上解决这个问题。
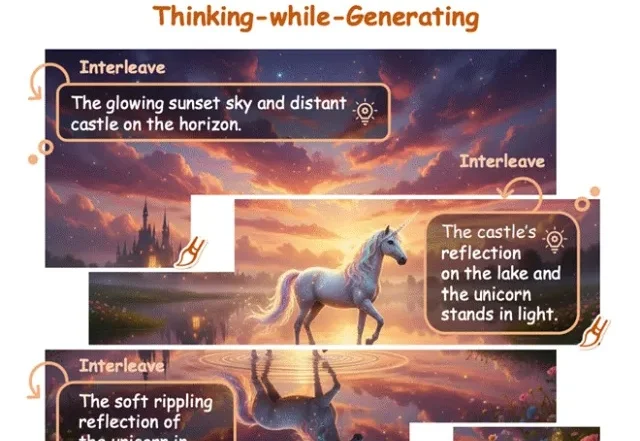
在文生图(Text-to-Image)和视频生成领域,以FLUX.1、Emu3为代表的扩散模型与自回归模型已经能生成极其逼真的画面。
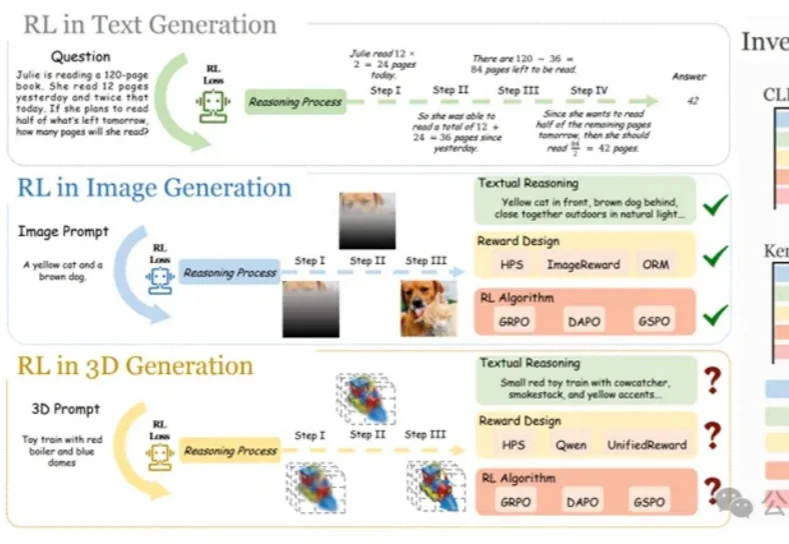
在大语言模型和文生图领域,强化学习(RL)已成为提升模型思维链与生成质量的关键方法。

AI一键成片神器来临!今天,Vidu Agent开启全球内测,一句话复刻爆款,从广告到创意短片,分镜级可控一键短片。