
Grok祭出首款生图模型Aurora!两位95后华人立大功,耗时6月自研MoE
Grok祭出首款生图模型Aurora!两位95后华人立大功,耗时6月自研MoE消失一天后的Aurora,正式上线了。一大早,马斯克官宣了Grok集成了自研图像新模型Aurora,MoE架构自回归模型,直接将生成编辑能力一统。在人物肖像生成上,已经逼真到肉眼无法辨别。
来自主题: AI技术研报
7237 点击 2024-12-10 16:22
 搜索
搜索
消失一天后的Aurora,正式上线了。一大早,马斯克官宣了Grok集成了自研图像新模型Aurora,MoE架构自回归模型,直接将生成编辑能力一统。在人物肖像生成上,已经逼真到肉眼无法辨别。
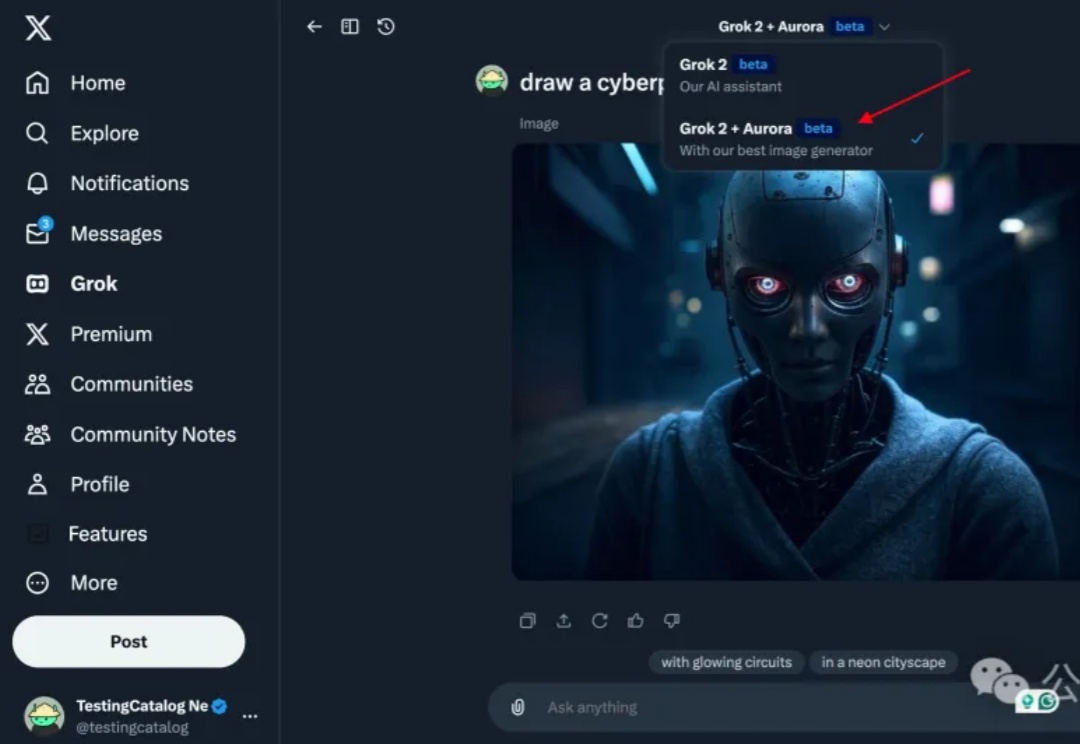
马斯克xAI的一个新动作,着实是引发了不少网友们的猎奇心理。

近日,根据彭博社报道,Flux背后公司黑森林工作室(Black Forest Labs)即将在新一轮融资中获得由a16z领投的2亿美元,预计公司估值突破10亿美元大关。2亿美元,是文生图领域迄今为止规模最大的融资。此次融资完成后,黑森林也是文生图领域为数不多的独角兽公司。

半小时内,两大巨头前后脚放出两大重磅更新,AI视频真是卷疯了!Runway放出生图模型Frames,一键让你拥有特定风格的世界。Luma则把文字、图像、视频全融合,只用自然交互就让脑海中画面成真。

一个是开源,一个是MoE (混合专家模型)。 开源好理解,在大模型火热之后,加入战局的腾讯已经按照它自己的节奏开源了一系列模型,包括混元文生图模型等。

前几天在对战平台Artificial Analysis出现了一个神秘的文生图模型"red_panda",而且排行位列第一,超过之前火爆的Flux 1.1 [pro]模型。
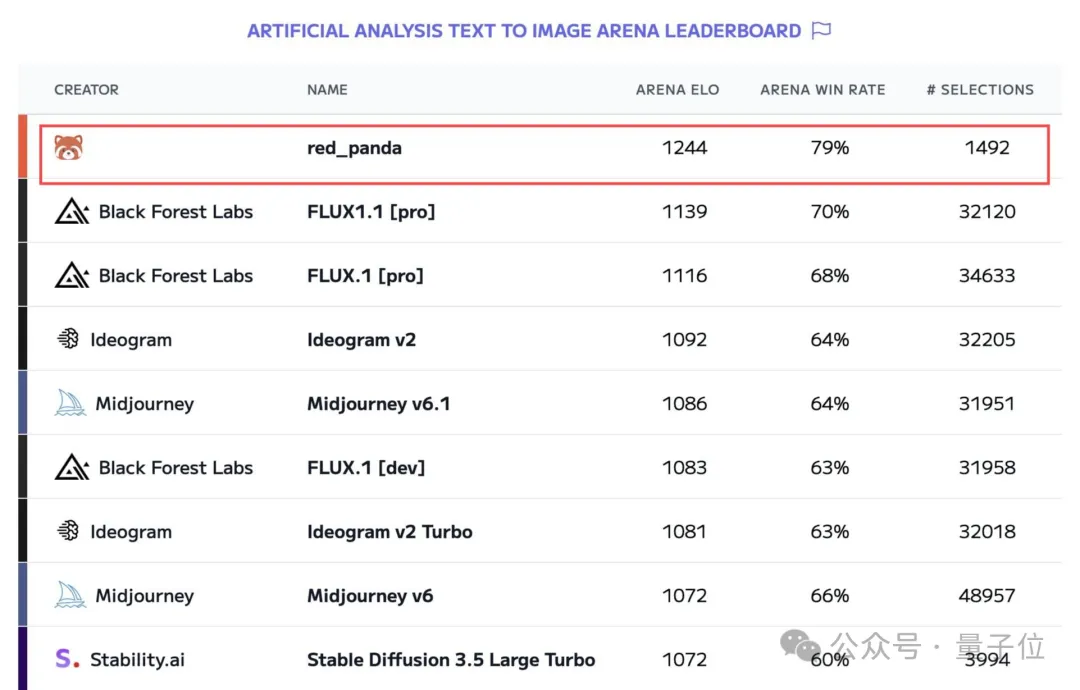
一夜之间,名为“red_panda” (小熊猫)的神秘文生图模型狠狠火了!!

最近,在全球人工智能模型竞技场(Artificial Analysis)文生图模型排行榜中,一个名叫Red_panda的新模型突然杀出重围,以9%的胜率超越了原榜一大哥Flux1.1Pro成为新王!

打造更强大文生图模型新思路有—— 面对Flux、stable diffusion、Omost等爆火模型,有人开始主打“集各家所长”。
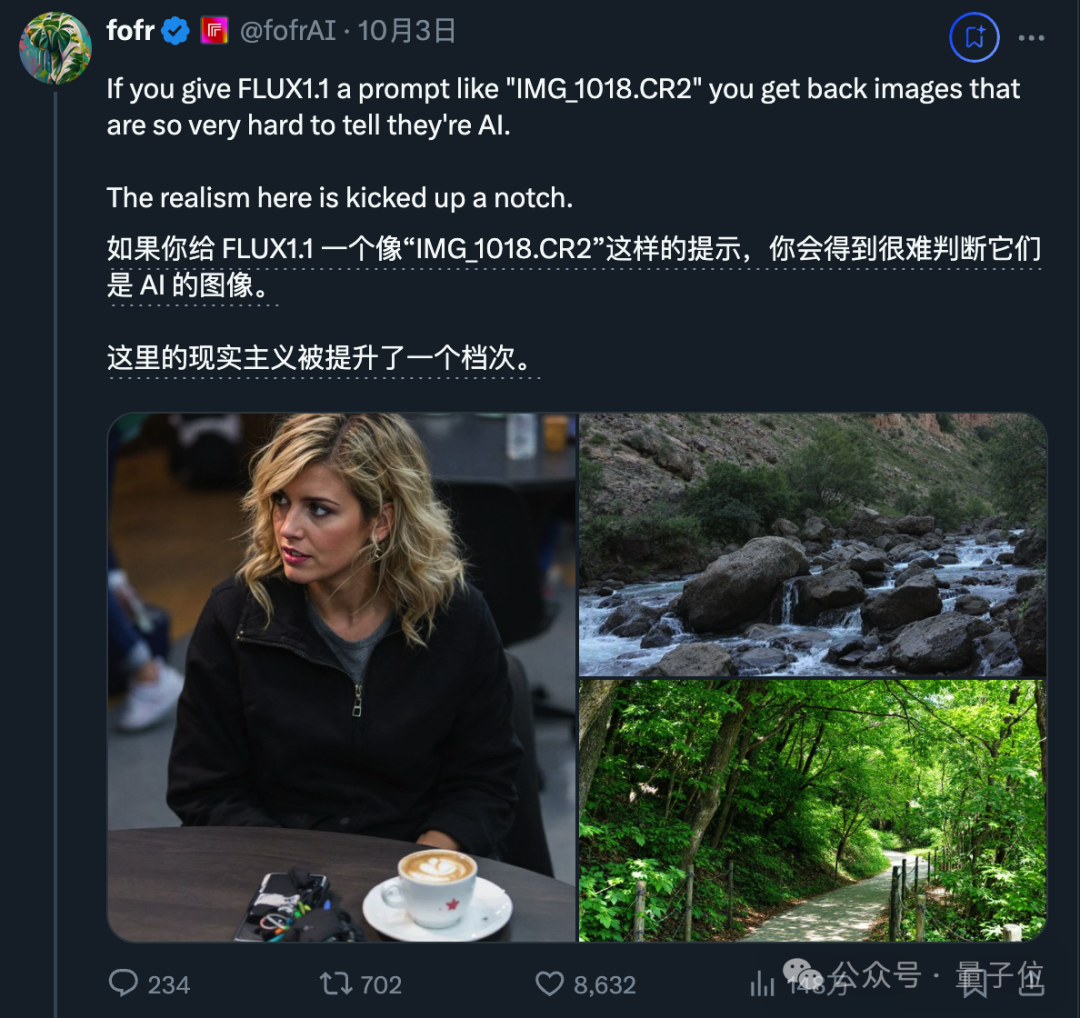
最新AI文生图模型Flux1.1,一夜刷屏。