最新Agentic Search综述,RL让Agent自主检索,RAG逐渐成为过去式
最新Agentic Search综述,RL让Agent自主检索,RAG逐渐成为过去式大型语言模型(LLM)本身很强大,但知识是静态的,有时会“胡说八道”。为了解决这个问题,我们可以让它去外部知识库(比如维基百科、搜索引擎)里“检索”信息,这就是所谓的“检索增强生成”(RAG)。
来自主题: AI资讯
8354 点击 2025-10-25 14:09
 搜索
搜索
大型语言模型(LLM)本身很强大,但知识是静态的,有时会“胡说八道”。为了解决这个问题,我们可以让它去外部知识库(比如维基百科、搜索引擎)里“检索”信息,这就是所谓的“检索增强生成”(RAG)。

鹅厂就给旗下AI原生产品知识库工作台ima过了一周岁生日。还趁热打铁放出了ima 2.0版本,主打任务模式。于是,这个能把微信文件、公众号文章等资源一键变成可提问式知识库的鹅厂版NotebookLM,从只会问答升级到了能生成报告和播客的进阶版。

最近 flowith 推出了全新画布,交互形态全新升级,现在 AI 生成的任意内容,都可以被很方便的右键点击节点,存入任意知识库,后续工作都可以调用。说实话,flowith 是一款上手门槛比较高的产品,它不像一般对话式的 ChatBot 那样简单,

以腾讯元器平台上的「公众号智能体」为例,它提供了一种可能的解决方案。它最大的特点,是经过公众号创作者授权后,可自动读取该公众号发布的文章,并实时更新为知识库。对于我们前面提到的困惑,这个功能简直是打瞌睡送来了枕头。

Dify 又偷偷更新了!本次更新不仅支持了期待已久的“图文混答”,几乎是 重构了“知识库”,可以用工作流的方式创建“知识库”,并且支持调试,具备“工作流”的完整功能,是一个正经的”工作流“。提升了知识库开发的灵活性,与智能体的交互体验。
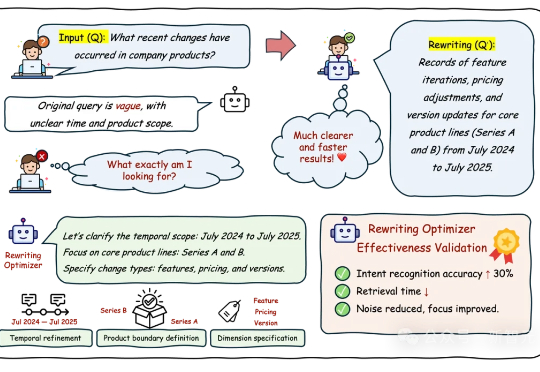
AI加速走向落地,企业「超级大脑」却在关键时刻断片?行业亟需一套能够持续进化、越用越聪明的系统框架,实现多智能体协同作战,通过自优化、自反馈瞬间激活知识库。清华系黑马已将其塞进AI原生引擎,率先在能源、军工等硬核场景中规模化落地,为产业智能升级提供了可靠路径。
团队在自研知识库底座的过程中,想对比参考下RAGFlow,发现其切片方法缺乏详细说明和清晰案例,如果你也遇到以下问题,本文能帮你节省大量试错时间

使用Google Gemini CLI构建个人知识库是高效的知识管理新方式。该工具通过命令行实现自然语言交互,能自动化整理文件、转换格式、生成结构化内容(如知识图谱)。相比云端笔记软件,其本地优先特性保障隐私且支持多模态处理,结合高质量输入可实现个性化自适应学习,本质是人与AI协同进化的工作范式升级。
斯克憋了快半年,终于把 Grok 4 端上了台面。这一次,他的口气依旧不小。早在发布会前就放出狠话,声称 Grok 4 要「重写人类知识库」。等到了发布会上,马斯克再次强调 Grok 4 是目前世界上最聪明的 AI。
AI浏览器正成为AI时代竞争的关键入口,其角色从信息窗口转变为融合搜索、决策与执行的智能伙伴。浏览器形态成为AI助手(如豆包)、AI搜索(如夸克)、AI知识库(如ima)及Agent工具(如扣子空间)的共同选择。