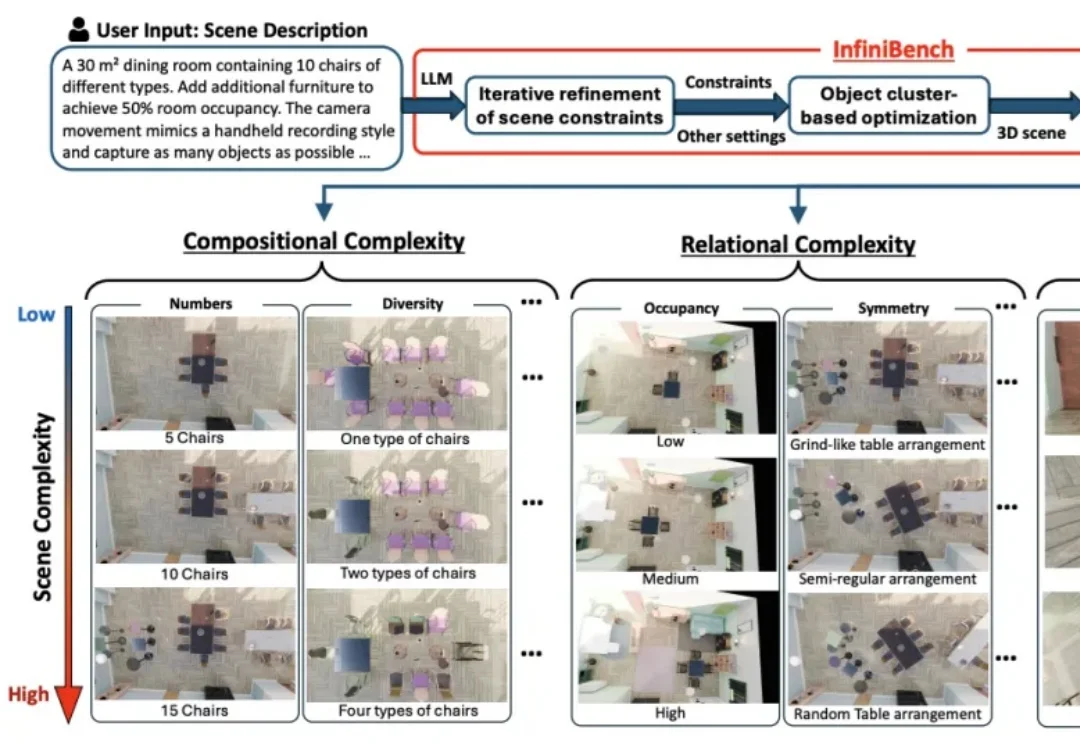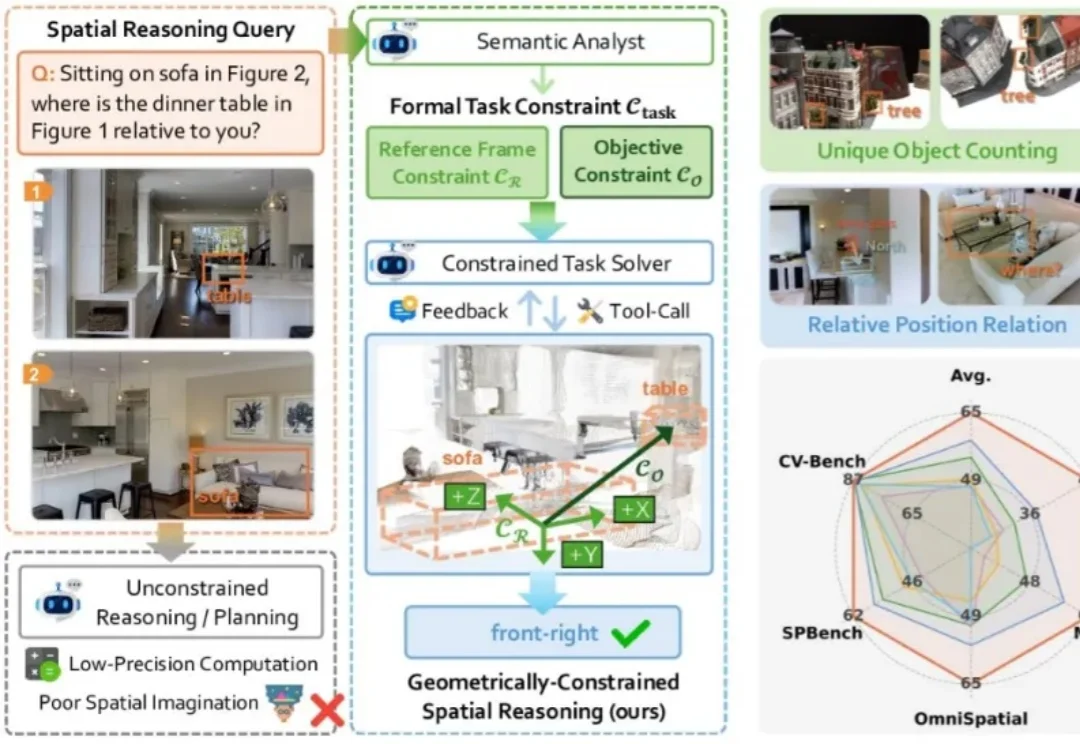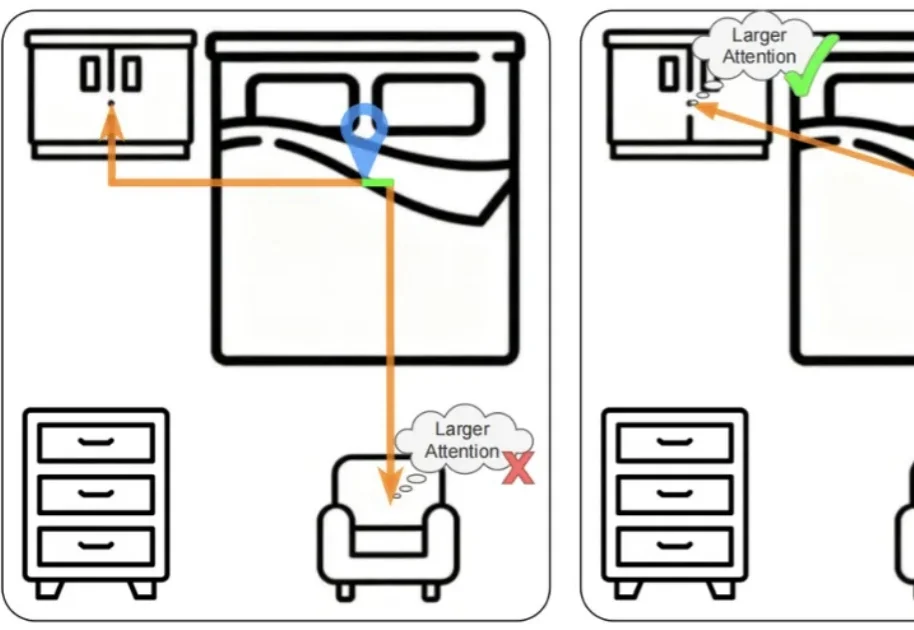
CVPR 2026|突破3D空间推理瓶颈:北大联合南科大提出QuatRoPE,让大模型精准理解三维物体关系
CVPR 2026|突破3D空间推理瓶颈:北大联合南科大提出QuatRoPE,让大模型精准理解三维物体关系本文主要介绍来自该团队的最新论文:Scalable Object Relation Encoding for Better 3D Spatial Reasoning in Large Language Models。
来自主题: AI技术研报
5864 点击 2026-04-20 14:04