编码器-解码器架构的复兴?谷歌一口气发布32个T5Gemma模型
编码器-解码器架构的复兴?谷歌一口气发布32个T5Gemma模型今天是 xAI 的大日子,伊隆・马斯克早早就宣布了会在今天发布 Grok 4 大模型,AI 社区的眼球也已经向其聚拢,就等着看他的直播(等了挺久)。当然,考虑到 Grok 这些天的「失控」表现,自然也有不少人是在等着看笑话。
来自主题: AI技术研报
8728 点击 2025-07-11 17:19
 搜索
搜索
今天是 xAI 的大日子,伊隆・马斯克早早就宣布了会在今天发布 Grok 4 大模型,AI 社区的眼球也已经向其聚拢,就等着看他的直播(等了挺久)。当然,考虑到 Grok 这些天的「失控」表现,自然也有不少人是在等着看笑话。

MoCa框架把单向视觉语言模型转化为双向多模态嵌入模型,通过持续预训练和异构对比微调,提升模型性能和泛化能力,在多模态基准测试中表现优异,尤其小规模模型性能突出。
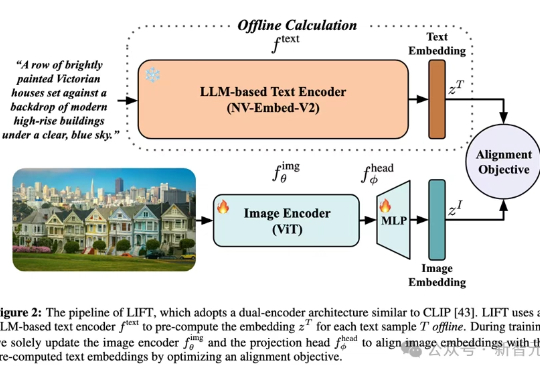
多模态对齐模型借助对比学习在检索与生成任务中大放异彩。最新趋势是用冻结的大语言模型替换自训文本编码器,从而在长文本与大数据场景中降低算力成本。LIFT首次系统性地剖析了此范式的优势来源、数据适配性、以及关键设计选择,在组合语义理解与长文本任务上观察到大幅提升。

推理模型与普通大语言模型有何本质不同?它们为何会「胡言乱语」甚至「故意撒谎」?Goodfire最新发布的开源稀疏自编码器(SAEs),基于DeepSeek-R1模型,为我们提供了一把「AI显微镜」,窥探推理模型的内心世界。
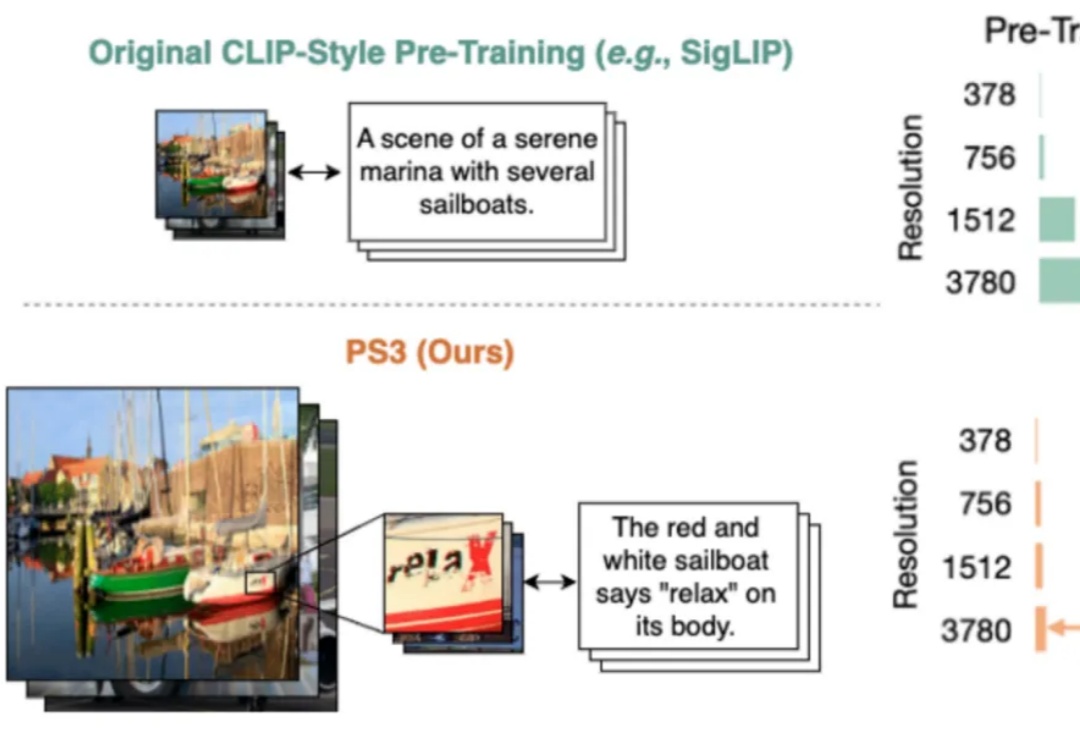
当前,所有主流的视觉基础模型(如 SigLIP、DINOv2 等)都仍然在低分辨率(如 384 * 384 分辨率)下进行预训练。对比人类视觉系统可以轻松达到 10K 等效分辨率,这种低分辨率预训练极大地限制了视觉模型对于高清细节的理解能力。
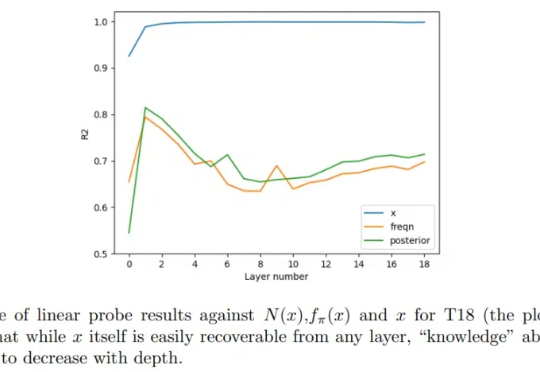
Transformer 很成功,更一般而言,我们甚至可以将(仅编码器)Transformer 视为学习可交换数据的通用引擎。由于大多数经典的统计学任务都是基于独立同分布(iid)采用假设构建的,因此很自然可以尝试将 Transformer 用于它们。

新一代 Kaldi 团队是由 Kaldi 之父、IEEE fellow、小米集团首席语音科学家 Daniel Povey 领衔的团队,专注于开源语音基础引擎研发,从神经网络声学编码器、损失函数、优化器和解码器等各方面重构语音技术链路,旨在提高智能语音任务的准确率和效率。
Cusor,一个AI编码器,如果仅仅是一个编码器,在chatGPT,百度,阿里,腾讯,字节等众多同类AI编辑器中不是最早的AI编辑器,也不是最先AI赋能的插件或者程序,但是一个支持自然语言,更适合程序员体质的Cusor凭什么脱颖而出?

港科大团队重磅开源 VideoVAE+,提出了一种强大的跨模态的视频变分自编码器(Video VAE),通过提出新的时空分离的压缩机制和创新性引入文本指导,实现了对大幅运动视频的高效压缩与精准重建,同时保持很好的时间一致性和运动恢复。
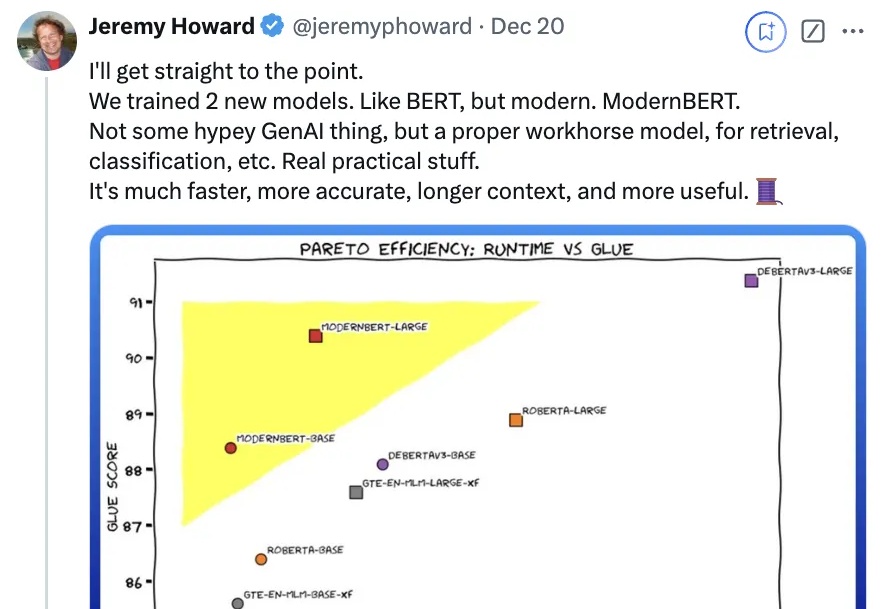
时隔6年,一度被认为濒死的“BERT”杀回来了——