
起猛了,腾讯元宝接入DeepSeek了。
起猛了,腾讯元宝接入DeepSeek了。这应该是我知道的第一家有自己大模型的大厂,第一次在面向C端的AI助手应用中,第一次接入DeepSeek R1。这个意义影响还是非常深远的,腾讯在AI这一步上,好像走的格外的开放,从之前的批量开源MoE、混元绘图模型、混元视频模型、混元3D模型,还有今天这神之一手接入DeepSeek R1。
来自主题: AI资讯
10776 点击 2025-02-13 13:31
 搜索
搜索
这应该是我知道的第一家有自己大模型的大厂,第一次在面向C端的AI助手应用中,第一次接入DeepSeek R1。这个意义影响还是非常深远的,腾讯在AI这一步上,好像走的格外的开放,从之前的批量开源MoE、混元绘图模型、混元视频模型、混元3D模型,还有今天这神之一手接入DeepSeek R1。
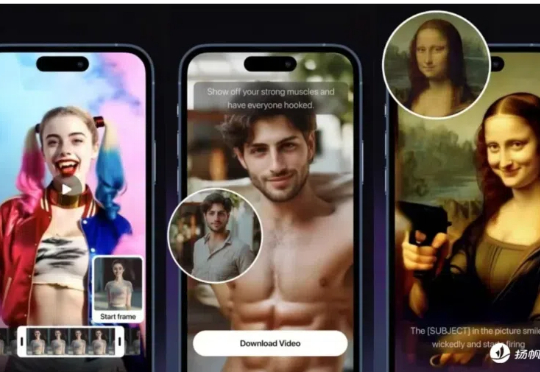
如今,AI爆发趋势势不可挡,从去年开始,内容生成领域就备受瞩目,无论是文生还是图生,都让创作变得轻而易举,也让更多的非原专业人士能够参与其中,体验用极短的时间制作出心仪的内容。

对 LLM 来说,Pre-training 的时代已经基本结束了。视频模型的 Scaling Law,瓶颈还很早。具身智能:完全具备人类泛化能力的机器人,在我们这代可能无法实现
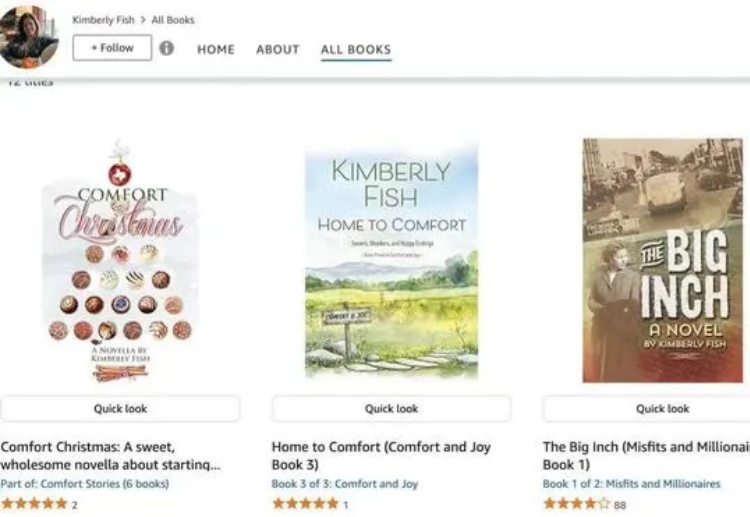
AI视频模型正以意想不到的方式影响着世界各地每个人的生活,也包括一位远在大洋彼岸的60岁老奶奶。
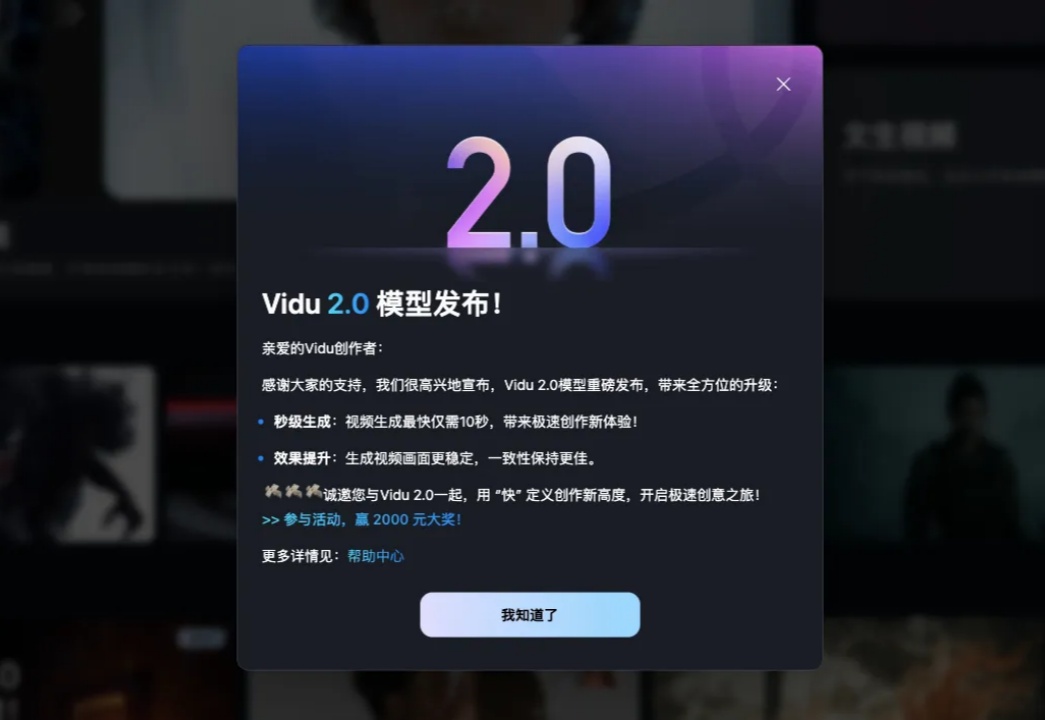
今天中午,Vidu突然发了他们的AI视频模型Vidu2.0。
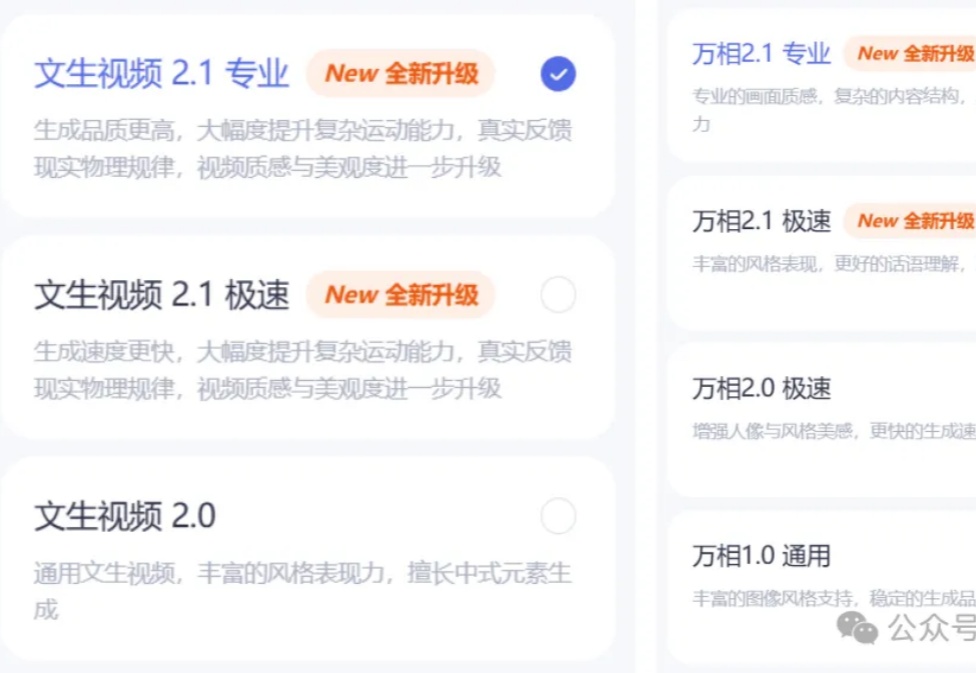
通义万相视频模型,再度迎来史诗级升级!处理复杂运动、还原真实物理规律等方面令人惊叹,甚至业界首创了汉字视频生成。现在,通义万相直接以84.70%总分击败了一众顶尖模型,登顶VBench榜首。

说到2024年AI圈的热门话题,当然不能错过视频生成模型了! 即使是在12月,国内外视频模型的更新脚步依旧没有放缓。其中以Sora、可灵AI为代表。
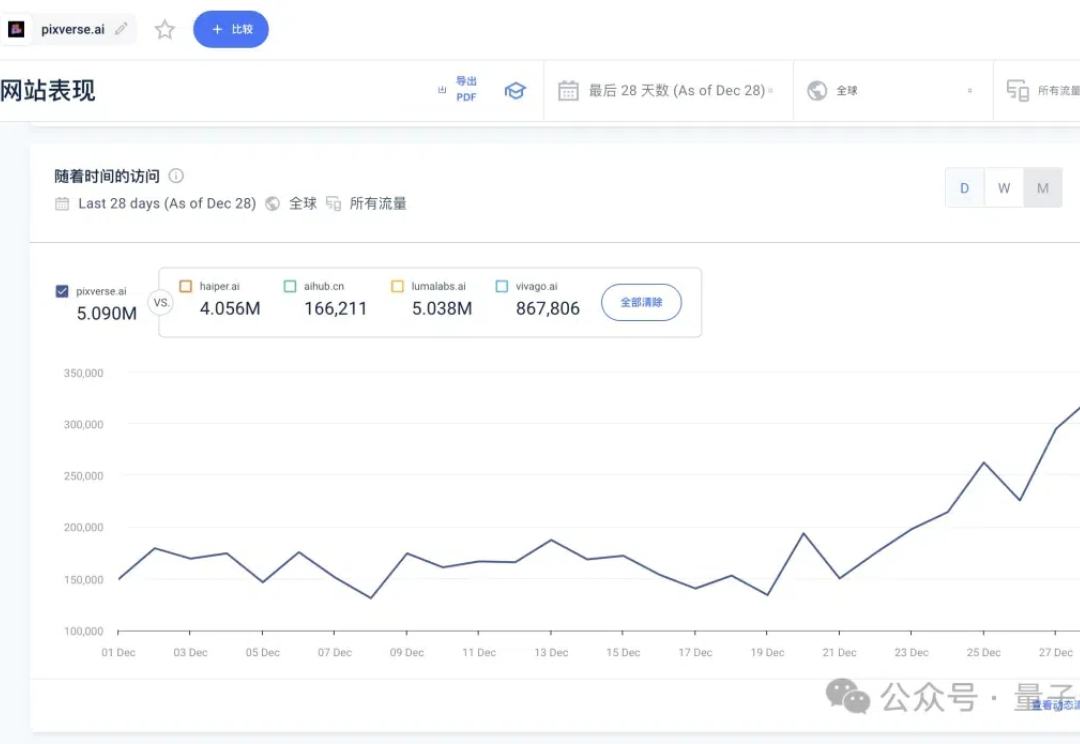
2025刚开年,没想到国产AI视频模型PixVerse又给咱们整了一波新活! 继上次席卷全网的万物皆可毒液之后,它们又火速更新了3.5版本。

提速8倍! 速度更快、效果更好的混元视频模型——FastHunyuan来了! 新模型仅用1分钟就能生成5秒长的视频,比之前提速8倍,步骤也从50步减少到了6步,甚至画面细节也更逼真了。

Apple MM1Team 再发新作,这次是苹果视频生成大模型,关于模型架构、训练和数据的全面报告,87 亿参数、支持多模态条件、VBench 超 PIKA,KLING,GEN-3。