
深度|对话生数科技工程VP陈鑫和百度百舸产品负责人兰宇,探索后Sora时代国产视频模型的机遇
深度|对话生数科技工程VP陈鑫和百度百舸产品负责人兰宇,探索后Sora时代国产视频模型的机遇本期我们有幸邀请到生数科技工程副总裁(VP)陈鑫与百度智能云AI计算部副总经理兰宇,深度解析Vidu这款视频大模型从发布到在行业内爆火的背后故事。
来自主题: AI资讯
9569 点击 2024-12-11 14:39
 搜索
搜索
本期我们有幸邀请到生数科技工程副总裁(VP)陈鑫与百度智能云AI计算部副总经理兰宇,深度解析Vidu这款视频大模型从发布到在行业内爆火的背后故事。
想要体验文生视频的小伙伴又多了一个选择!
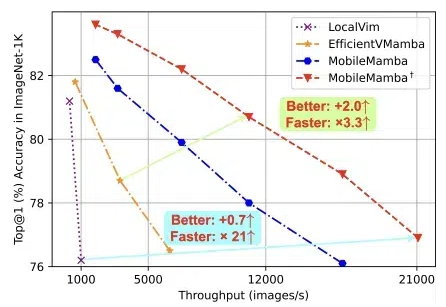
浙大、腾讯优图、华中科技大学的团队,提出轻量化MobileMamba! 既良好地平衡了效率与效果,推理速度远超现有基于Mamba的模型。

三张图攒一个毫无违和感的视频!

全球首个支持多主体一致性的多模态模型,刚刚诞生!Vidu 1.5一上线,全网网友都震惊了:LLM独有的上下文学习优势,视觉模型居然也有了。

自打ChatGPT让人工智能这个概念迎来第二春,百度创始人李彦宏也重新活跃了起来,成为了几乎是最爱发声的互联网大佬。在此前先后发表AI终结程序员、开源模型会越来越落后等言论之后,有消息称在最近举行的百度2024年第三季度总监会上他又放话,“百度不碰Sora类的视频生成。”

最近有一篇题为《2美元的H100:GPU泡沫是如何破灭的?》的文章异常火热,甚至投资人都认为英伟达坚挺的股价就是被这一篇文章所摧毁。

太平洋证券分析师郑磊认为,下半年以来,国内AI视频模型优势显著。

视频生成模型大乱斗

在OpenAI Sora的主要技术负责人跑去Google、多个报道指出OpenAI Sora在内部因质量问题而导致难产的节骨眼,Meta毫不客气发了它的视频模型“Movie Gen”,并直接用一个完整的评测体系宣告自己打败了Sora们。