
只用15%数据,多模态指令微调反超全量训练15.8%!
只用15%数据,多模态指令微调反超全量训练15.8%!来自上海交大、马来亚大学、CMU、MBZUAI、KIT和KAUST的团队提出VisNec(Visual Necessity Score,视觉必要性分数),用一个分数衡量每条训练样本里“图像到底起了多大作用”,被ECCV 2026收录。
来自主题: AI技术研报
8140 点击 2026-07-04 10:47
 搜索
搜索
来自上海交大、马来亚大学、CMU、MBZUAI、KIT和KAUST的团队提出VisNec(Visual Necessity Score,视觉必要性分数),用一个分数衡量每条训练样本里“图像到底起了多大作用”,被ECCV 2026收录。

刚刚,纽约大学联合LeCun初创AMI带来JEPA系列的最新成果——AdaJEPA。与过去在预训练结束后就冻结参数的世界模型不同,AdaJEPA能够在与环境交互中,基于测试时自适应(Test-Time Adaptation, TTA),实时调整世界模型的编码器和预测器参数,从而实现持续学习。

还在聊Sim2Real?现在机器人圈更火的是Real2Sim!最近,英伟达GEAR联合李飞飞团队、佐治亚理工大学等机构联合发布全新Real2Sim系统——SimFoundry。SimFoundry只需一段真实世界视频,就能自动生成一个可以交互、训练、评测的机器人仿真环境。
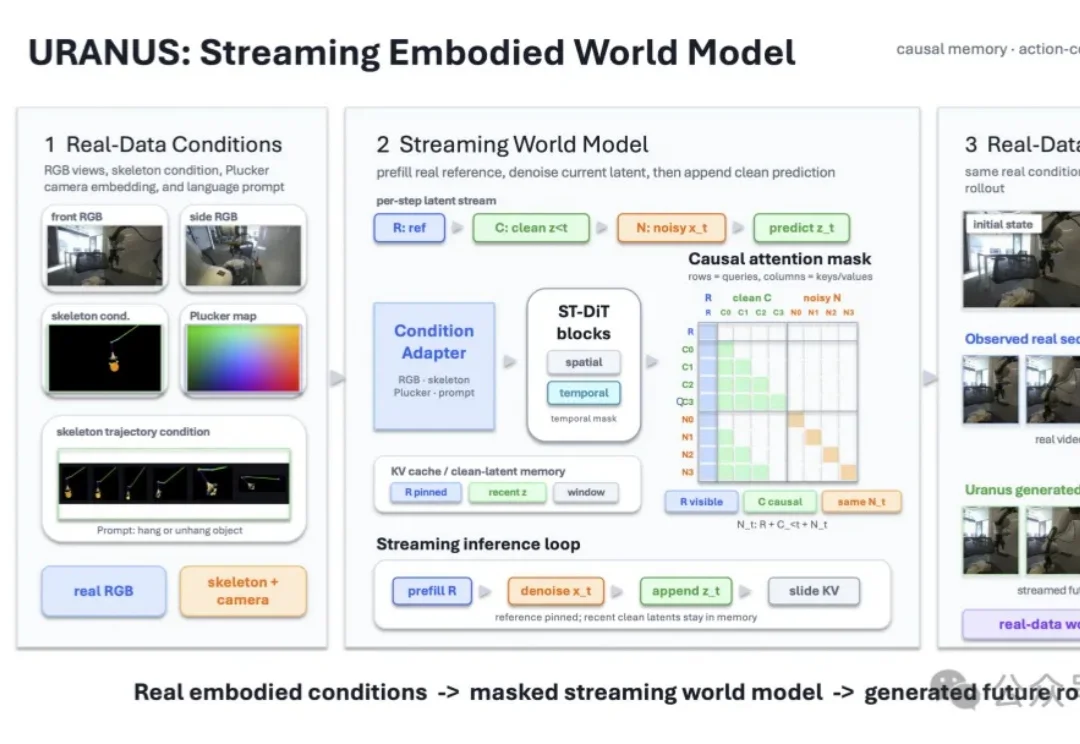
眼下具身赛道都在卷世界模型,都在抢着做机器人的“大脑”。

设想这样一幕:你让一个编码智能体修复某个 bug,并用一组单元测试作为「做对了没有」的判据。

做大模型RL微调,你是不是也踩过这些坑?
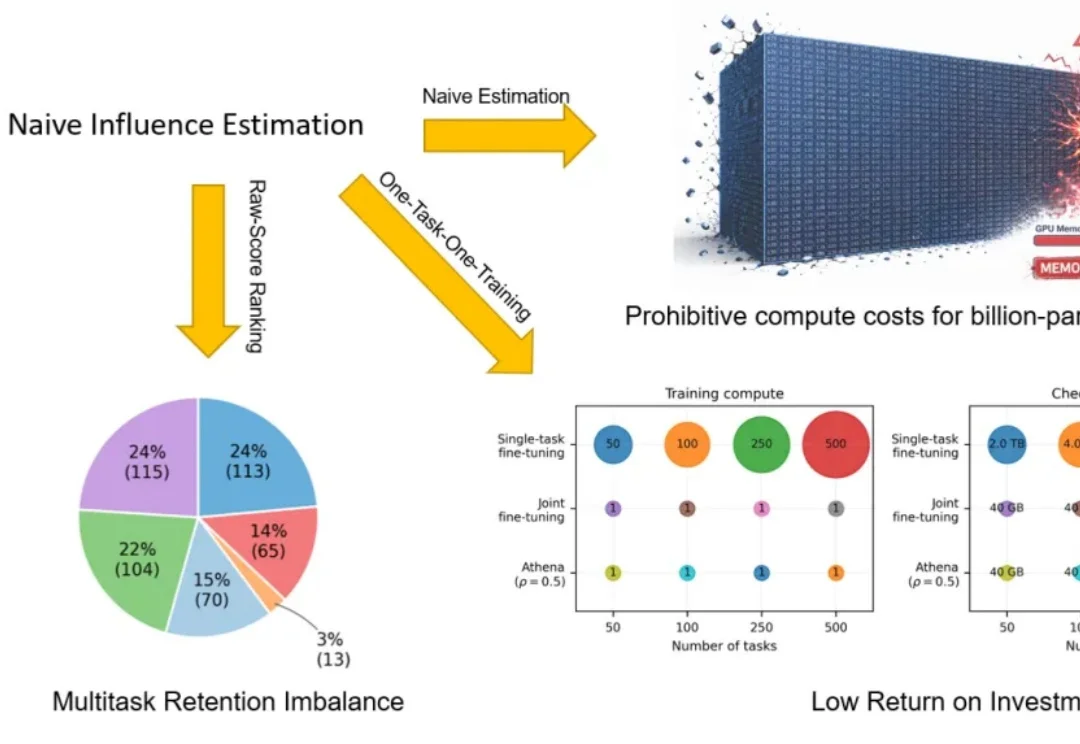
具身智能正在进入数据 scaling 时代。Vision-Language-Action(VLA)模型让机器人可以从大规模示教数据(demonstrations)中学习更通用的操作策略。但对机器人 VLA 训练来说,数据并不总是越多越好:低质量数据可能会拖累模型性能,而每一条 demonstration 都意味着昂贵的人力采集、机器人运行,以及云端存储和训练成本。
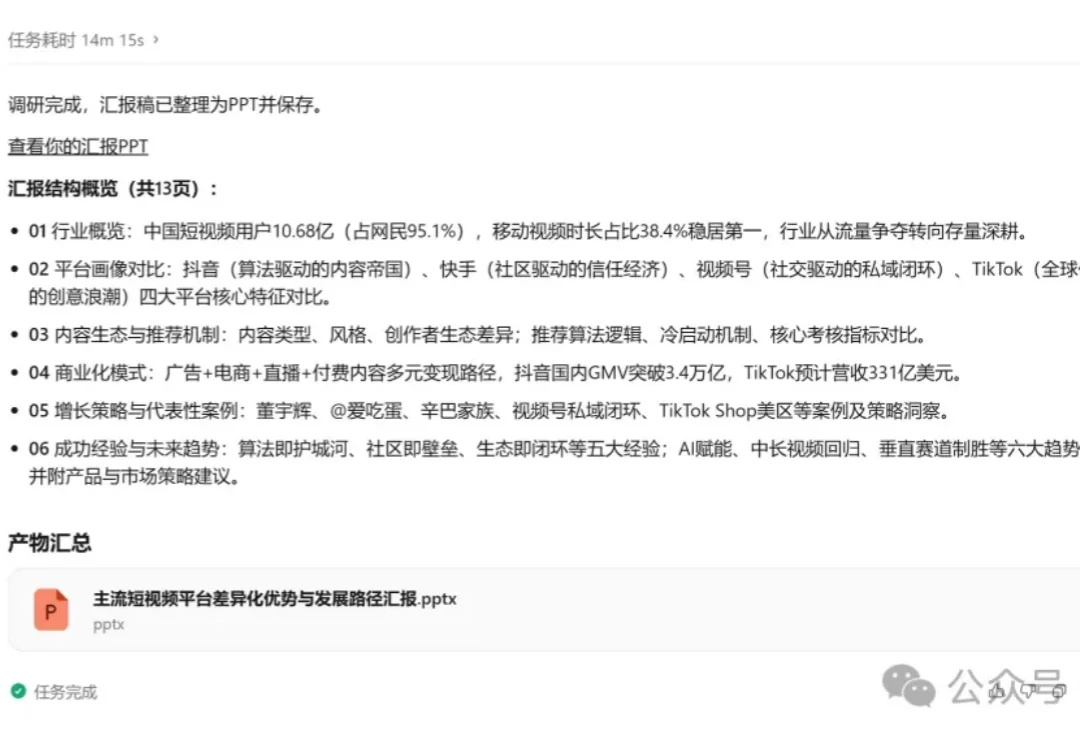
最近这段时间,国内外模型更新得很快。
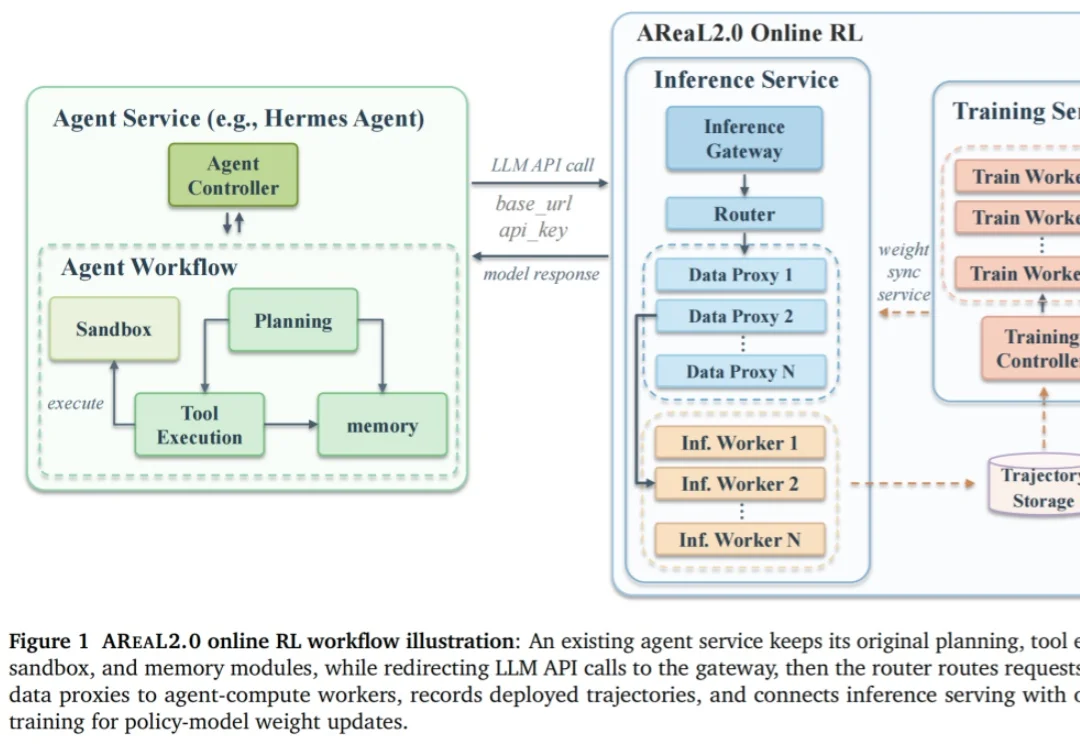
当 Agent 从演示视频中的炫技片段开始走进真实工作流与生产环境,下一阶段的「何去何从」成为业界关注的焦点。
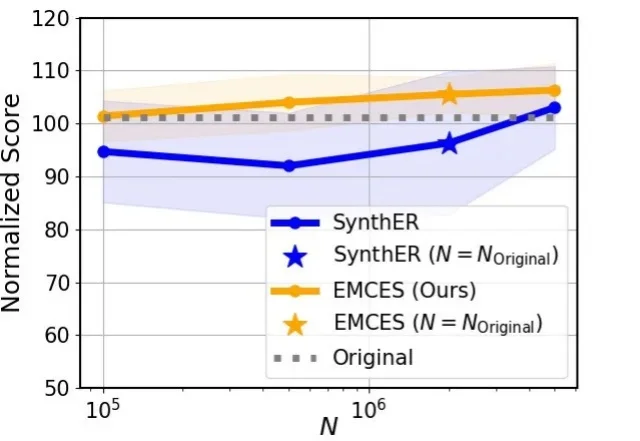
近年来,强化学习在游戏智能体、具身智能、大语言模型等领域取得了显著进展。然而,在真实世界中,强化学习仍面临一个核心难题:高质量样本的获取不仅成本高昂,还可能带来多种风险。因此,样本增强成为缓解强化学习中样本获取成本高、风险大等问题的重要途径之一。