
迈向机器人领域ImageNet,大牛Pieter Abbeel领衔国内外高校共建RoboVerse,统一仿真平台、数据集和基准
迈向机器人领域ImageNet,大牛Pieter Abbeel领衔国内外高校共建RoboVerse,统一仿真平台、数据集和基准大规模数据集和标准化评估基准显著促进了自然语言处理和计算机视觉领域的发展。然而,机器人领域在如何构建大规模数据集并建立可靠的评估体系方面仍面临巨大挑战。
来自主题: AI技术研报
9137 点击 2025-04-09 08:59
 搜索
搜索
大规模数据集和标准化评估基准显著促进了自然语言处理和计算机视觉领域的发展。然而,机器人领域在如何构建大规模数据集并建立可靠的评估体系方面仍面临巨大挑战。
大家翘首以盼的 Llama 4,用起来为什么那么拉跨?

多模态视频异常理解任务,又有新突破!

AI绘画总「翻车」,不是抓不住重点,就是细节崩坏?别愁!微软和港中文学者带来ImageGen-CoT技术,让AI像人一样思考推理,生成超惊艳画作,性能提升高达80%。
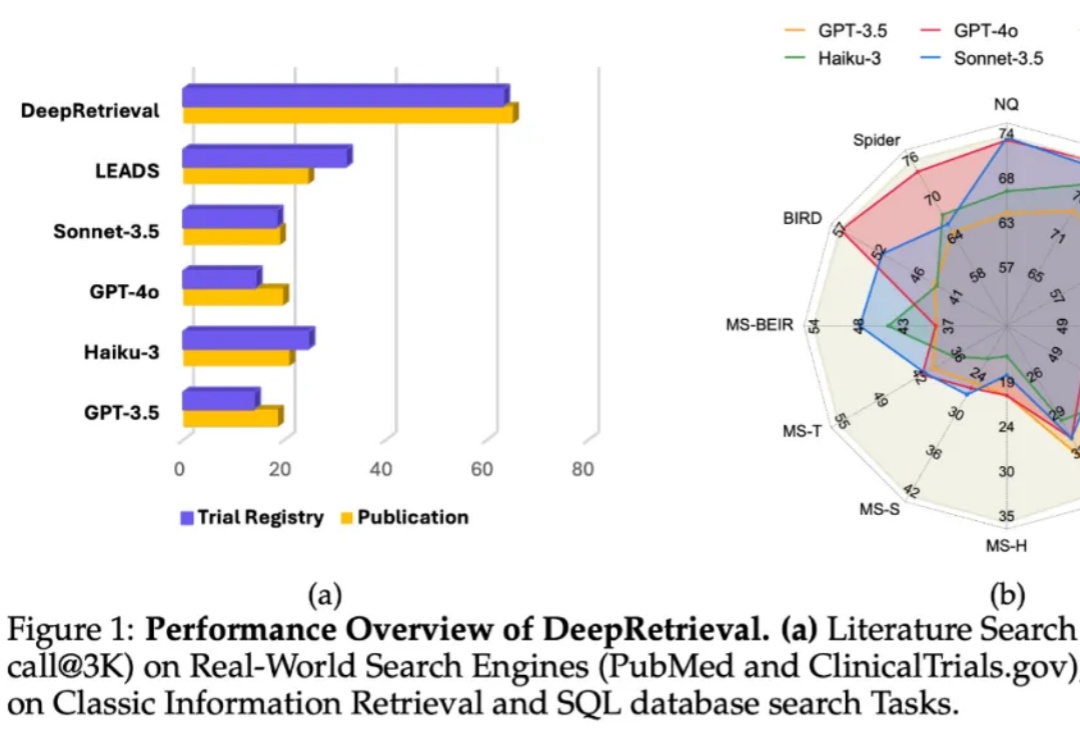
在信息检索系统中,搜索引擎的能力只是影响结果的一个方面,真正的瓶颈往往在于:用户的原始 query 本身不够好。
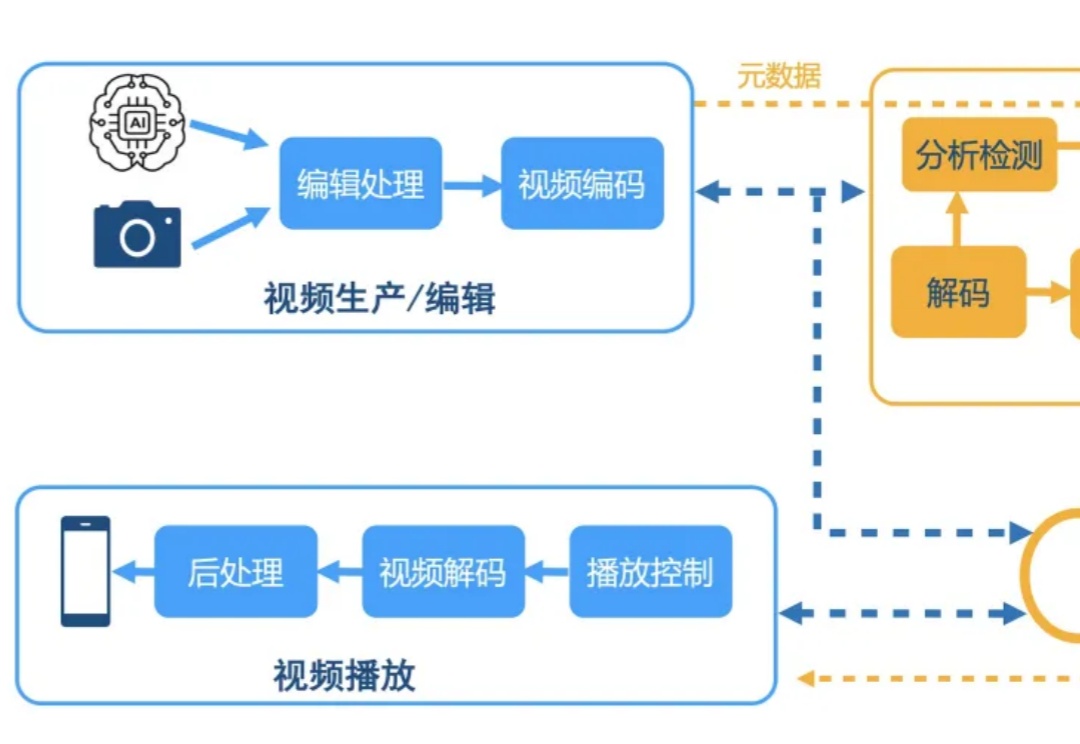
Q-Insight不再简单地让模型拟合人眼打分,而是将评分视作一种引导信号,促使模型深度思考图像质量的本质原因。有了会思考的“大脑”,视频云技术栈不仅得以重塑也让用户体验有了跃迁。
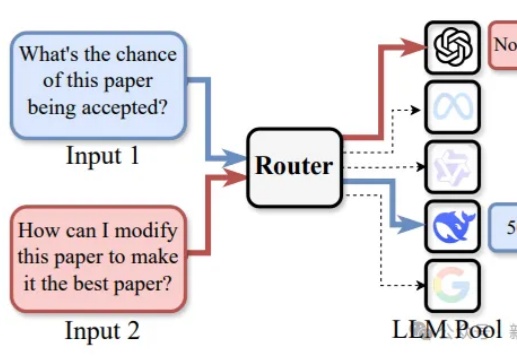
路由LLM是指一种通过router动态分配请求到若干候选LLM的机制。论文提出且开源了针对router设计的全面RouterEval基准,通过整合8500+个LLM在12个主流Benchmark上的2亿条性能记录。将大模型路由问题转化为标准的分类任务,使研究者可在单卡甚至笔记本电脑上开展前沿研究。
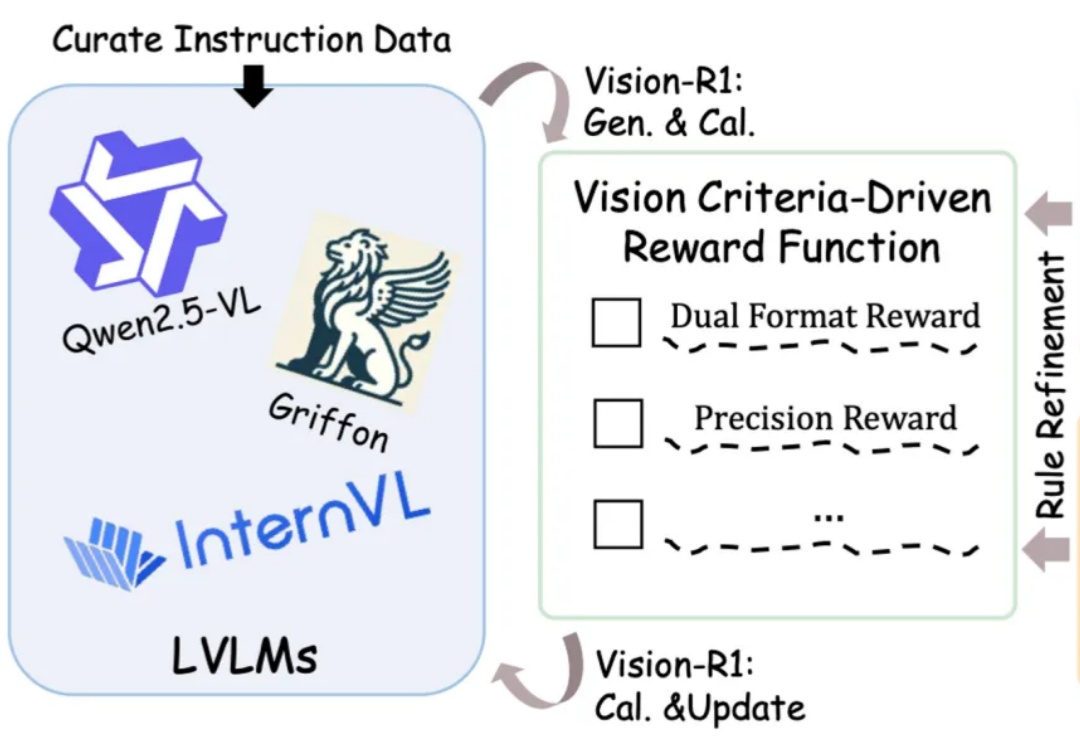
图文大模型通常采用「预训练 + 监督微调」的两阶段范式进行训练,以强化其指令跟随能力。受语言领域的启发,多模态偏好优化技术凭借其在数据效率和性能增益方面的优势,被广泛用于对齐人类偏好。目前,该技术主要依赖高质量的偏好数据标注和精准的奖励模型训练来提升模型表现。然而,这一方法不仅资源消耗巨大,训练过程仍然极具挑战。
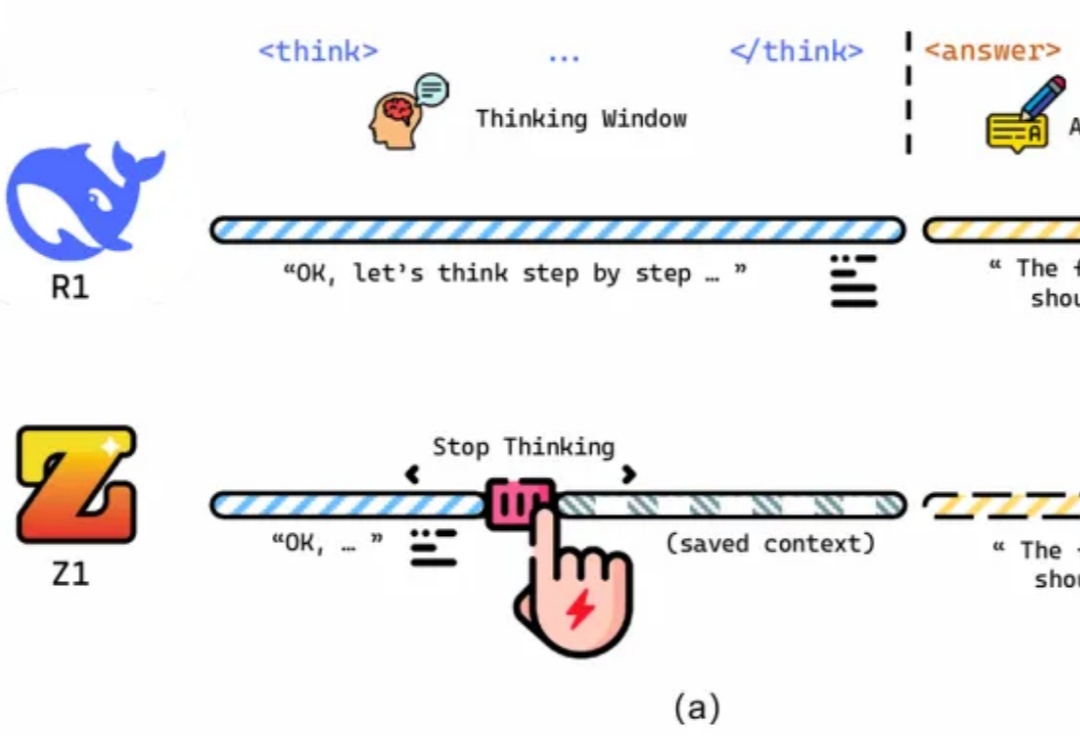
推理性能提升的同时,还大大减少Token消耗!
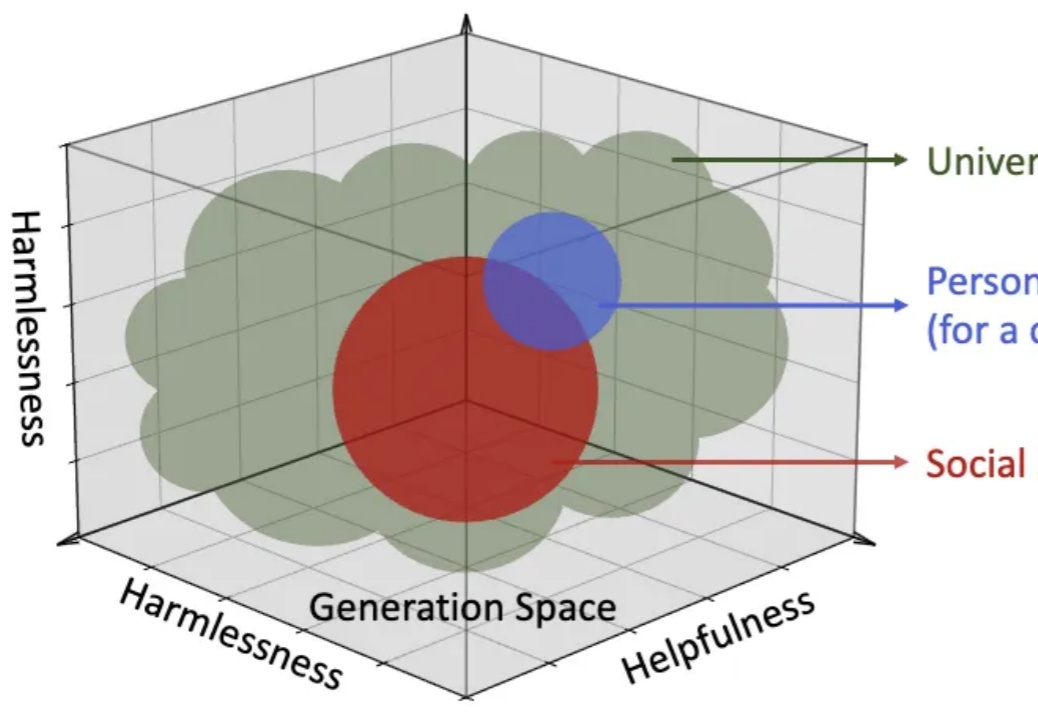
如何让大模型更懂「人」?