
o1开启LLM新范式,Ai2科学家解析背后秘籍:推理和强化学习是关键
o1开启LLM新范式,Ai2科学家解析背后秘籍:推理和强化学习是关键关注NLP领域的人们,一定好奇「语言模型能做什么?」「什么是o1?」「为什么思维链有效?」
来自主题: AI技术研报
7809 点击 2025-02-04 20:15
 搜索
搜索
关注NLP领域的人们,一定好奇「语言模型能做什么?」「什么是o1?」「为什么思维链有效?」
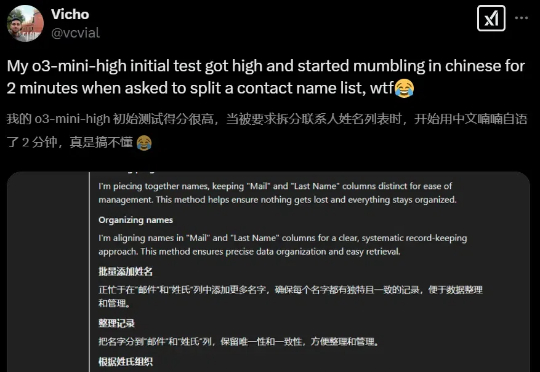
这两天,国外网友纷纷发现o3-mini-high在思考过程中居然会经常出现中文!难道真如网友猜测,是借鉴DeepSeek了?
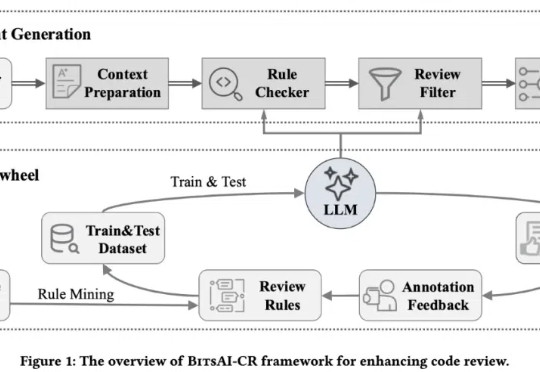
在人工智能浪潮席卷全球的今天,大语言模型 (LLM) 正在重塑软件开发流程。近日,字节跳动首次对外披露其内部广泛应用的代码审查系统 BitsAI-CR 的技术细节,展示了 AI 在提升企业研发效率方面的重要进展。
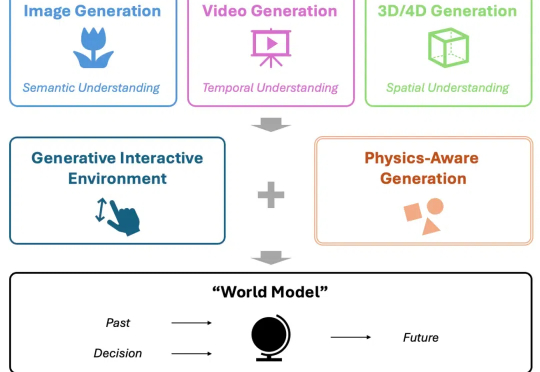
当下,视频生成备受关注,有望成为处理物理知识的 “世界模型” (World Model),助力自动驾驶、机器人等下游任务。然而,当前模型在从 “生成” 迈向世界建模的过程中,存在关键短板 —— 对真实世界物理规律的刻画能力不足。

近日,资深机器学习研究科学家 Cameron R. Wolfe 更新了一篇超长的博客文章,详细介绍了 LLM scaling 的当前状况,并分享了他对 AI 研究未来的看法。

DeepSeek震动硅谷,其高性价比的训练技术引发了市场的广泛关注。在最新发布的研报中,花旗分析师Atif Malik、Asiya Merchant等详细分析了DeepSeek对AI基建产业链各环节的潜在影响,揭示了哪些环节将受益,哪些环节可能面临挑战。

奥斯卡提名的热门影片《粗野派》的剪辑师最近透露,电影中采用了AI技术,让主演阿德里安·布洛迪和菲丽希缇·琼斯的匈牙利语对话更加自然真实,即使他们都接受过严格的语音训练。
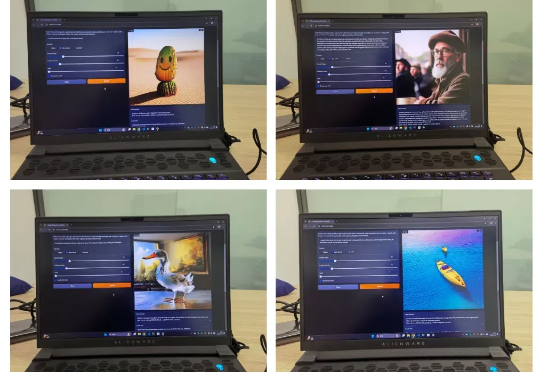
香港大学联合上海人工智能实验室,华为诺亚方舟实验室提出高效扩散模型 LiT:探索了扩散模型中极简线性注意力的架构设计和训练策略。LiT-0.6B 可以在断网状态,离线部署在 Windows 笔记本电脑上,遵循用户指令快速生成 1K 分辨率逼真图片。

27 页综述,354 篇参考文献!史上最详尽的视觉定位综述,内容覆盖过去十年的视觉定位发展总结,尤其对最近 5 年的视觉定位论文系统性回顾,内容既涵盖传统基于检测器的视觉定位,基于 VLP 的视觉定位,基于 MLLM 的视觉定位,也涵盖从全监督、无监督、弱监督、半监督、零样本、广义定位等新型设置下的视觉定位。

外媒SemiAnalysis的一篇深度长文,全面分析了DeepSeek背后的秘密——不是「副业」项目、实际投入的训练成本远超600万美金、150多位高校人才千万年薪,攻克MLA直接让推理成本暴降......