RAG没有银弹!四级难度,最新综述覆盖数据集、解决方案,教你「LLM+外部数据」的正确使用姿势
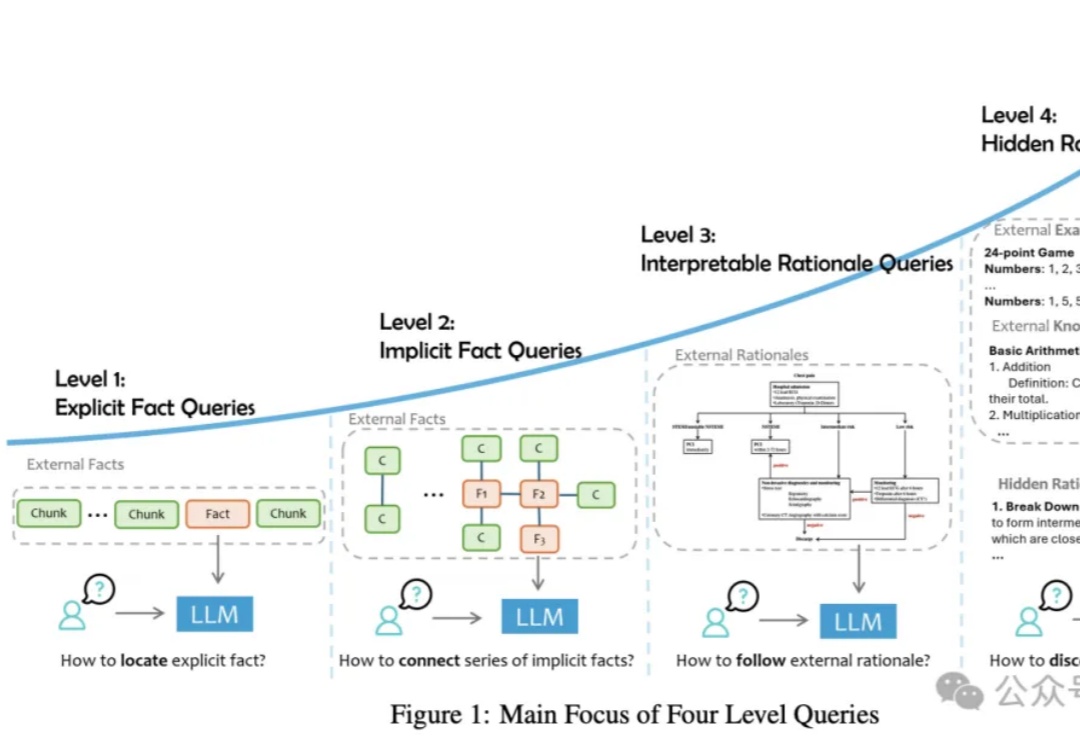
RAG没有银弹!四级难度,最新综述覆盖数据集、解决方案,教你「LLM+外部数据」的正确使用姿势论文提出了一种RAG任务分类法,将用户查询分为四个级别,并讨论了将外部数据集成到LLMs中的三种主要方式。从简单的事实检索到复杂的推理任务,每个级别都有其独特的难点和解决方案,需要不同的技术和方法来优化性能。
来自主题: AI技术研报
9398 点击 2024-11-21 13:39
 搜索
搜索
论文提出了一种RAG任务分类法,将用户查询分为四个级别,并讨论了将外部数据集成到LLMs中的三种主要方式。从简单的事实检索到复杂的推理任务,每个级别都有其独特的难点和解决方案,需要不同的技术和方法来优化性能。

今天,DeepSeek 全新研发的推理模型 DeepSeek-R1-Lite 预览版正式上线。所有用户均可登录官方网页 (chat.deepseek.com),一键开启与 R1-Lite 预览版模型的超强推理对话体验。DeepSeek R1 系列模型使用强化学习训练,推理过程包含大量反思和验证,思维链长度可达数万字。
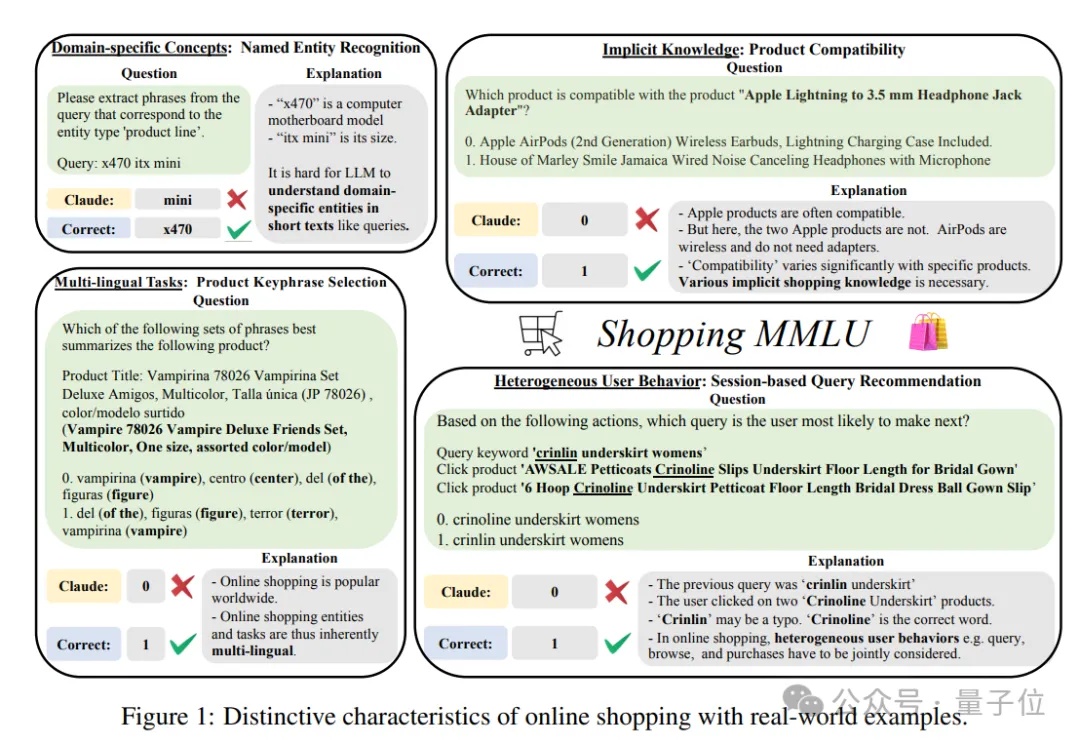
谁是在线购物领域最强大模型?也有评测基准了。
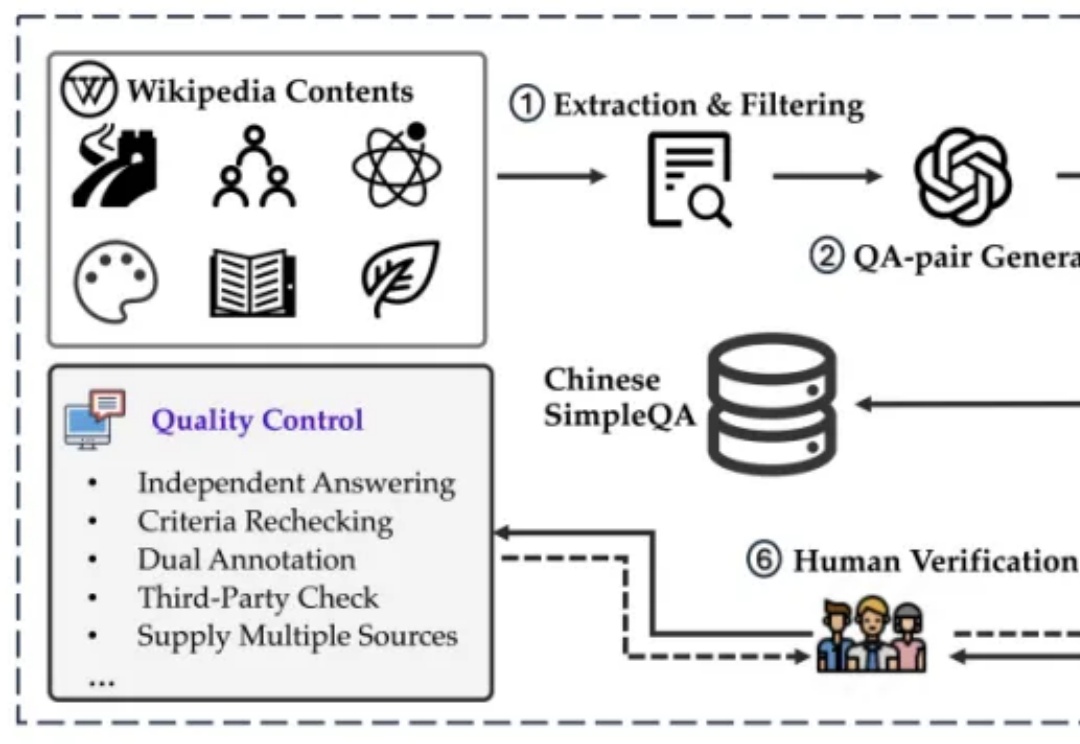
如何解决模型生成幻觉一直是人工智能(AI)领域的一个悬而未解的问题。为了测量语言模型的事实正确性,近期 OpenAI 发布并开源了一个名为 SimpleQA 的评测集。而我们也同样一直在关注模型事实正确性这一领域,目前该领域存在数据过时、评测不准和覆盖不全等问题。例如现在大家广泛使用的知识评测集还是 CommonSenseQA、CMMLU 和 C-Eval 等选择题形式的评测集。
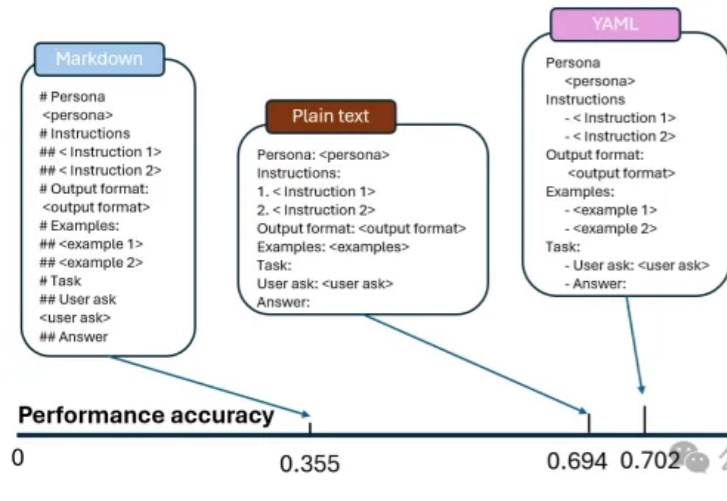
朋友们,想了解为什么同一模型会带来大量结果的不一致性吗?今天,我们来一起深入分析一下来自微软和麻省理工学院的一项重大发现——不同的Prompt格式如何显著影响LLM的输出精度。这些研究结果对于应用Prompt优化设计具有非常重要的应用价值。
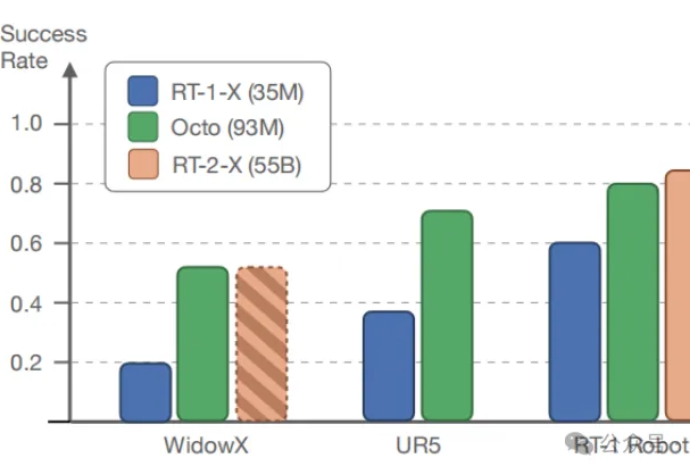
在多样化的机器人数据集上预训练的大型策略有潜力改变机器人学习:与从头开始训练新策略相比,这种通用型机器人策略可以通过少量的领域内数据进行微调,同时具备广泛的泛化能力。

近年来,代码语言模型(Language Models for Code,简称 CodeLMs)逐渐成为推动智能化软件开发的关键技术,应用场景涵盖智能代码生成与补全、漏洞检测与修复等。

探索数推分离,降低大模型成本,提高效率。
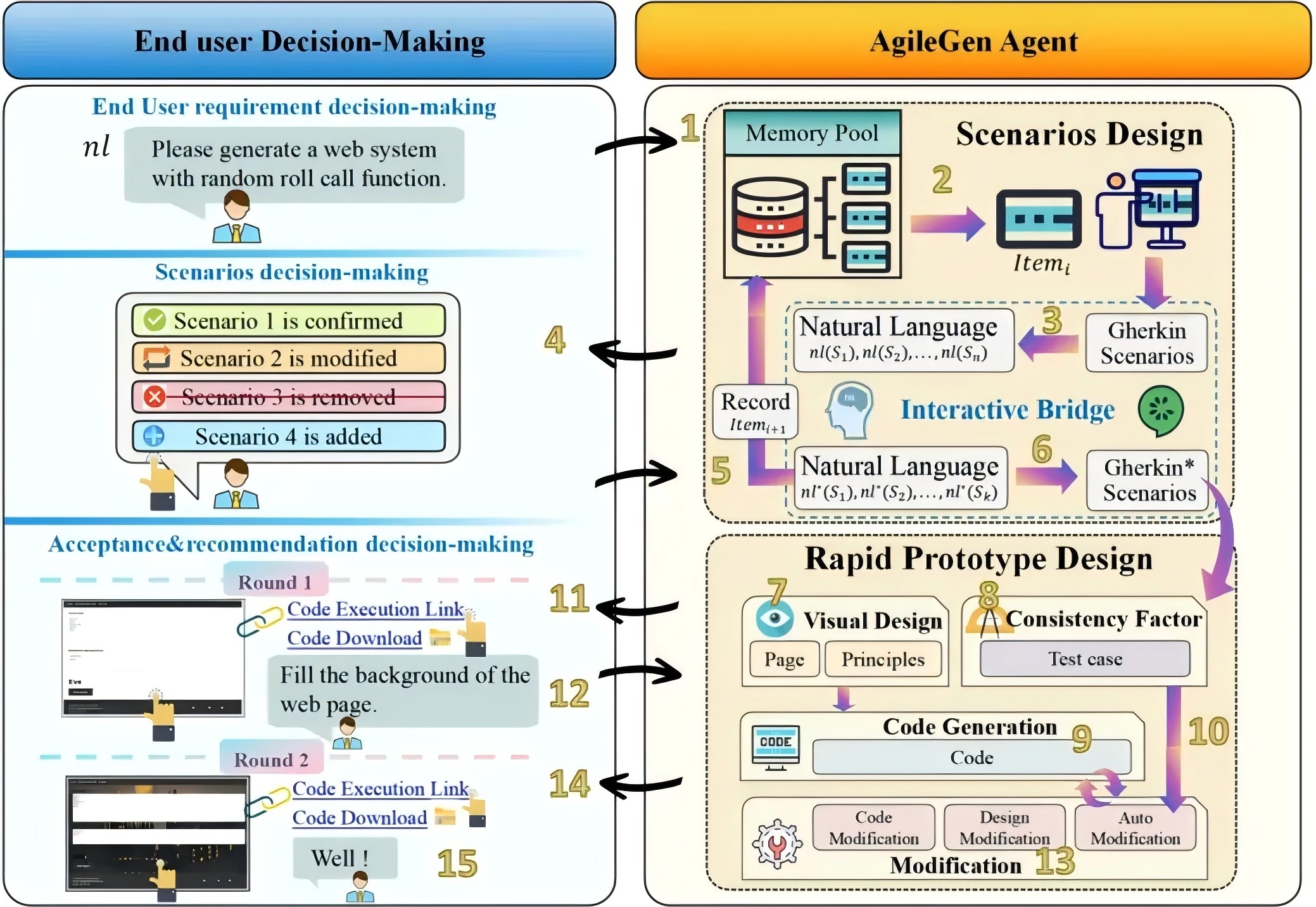
我们即将介绍的 AgileGen— 一种基于人机协作的敏捷生成式软件开发框架。
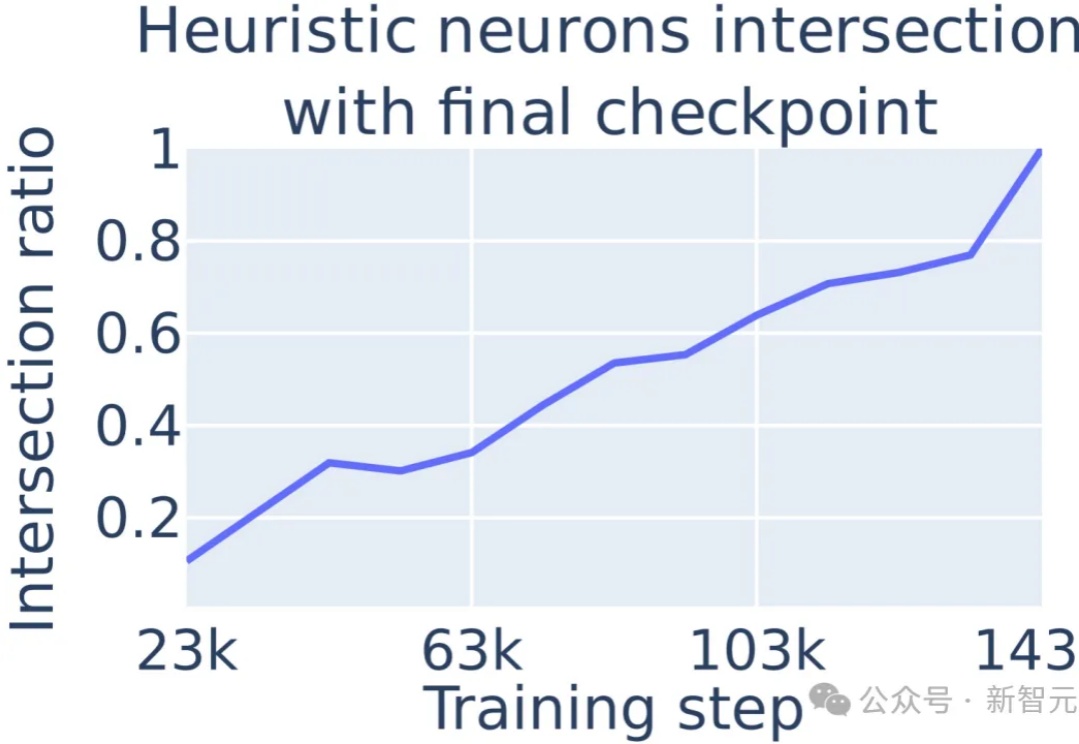
大模型在数学问题上的表现不佳,原因在于采取启发式算法进行数学运算的,通过定位到多层感知机(MLP)中的单个神经元,可以对进行数学运算的具体过程进行解释。