
统一transformer与diffusion!Meta融合新方法剑指下一代多模态王者
统一transformer与diffusion!Meta融合新方法剑指下一代多模态王者本文引入了 Transfusion,这是一种可以在离散和连续数据上训练多模态模型的方法。
来自主题: AI技术研报
11844 点击 2024-08-25 12:39
 搜索
搜索
本文引入了 Transfusion,这是一种可以在离散和连续数据上训练多模态模型的方法。

最近 ACL 2024 论文放榜,扫了下,SMoE(稀疏混合专家)的论文不算多,这里就仔细梳理一下,包括动机、方法、有趣的发现,方便大家不看论文也能了解的七七八八,剩下只需要感兴趣再看就好。

在人工智能领域,图像生成技术一直是一个备受关注的话题。近年来,扩散模型(Diffusion Model)在生成逼真且复杂的图像方面取得了令人瞩目的进展。然而,技术的发展也引发了潜在的安全隐患,比如生成有害内容和侵犯数据版权。这不仅可能对用户造成困扰,还可能涉及法律和伦理问题。
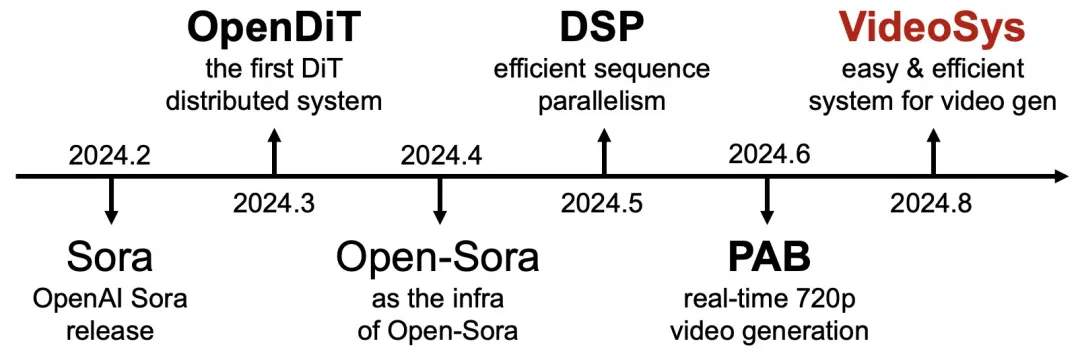
视频时代需要自己的基础设施。VideoSys 的目标是使视频生成对于每个人而言都简便、迅速且成本低廉。

只要不到10行代码,就能让大模型数学能力(GSM8k)提升20%!

就在刚刚,Meta最新发布的Transfusion,能够训练生成文本和图像的统一模型了!完美融合Transformer和扩散领域之后,语言模型和图像大一统,又近了一步。也就是说,真正的多模态AI模型,可能很快就要来了!

这篇文章对如何进行领域模型训练进行一个简单的探讨,主要内容是对 post-pretrain 阶段进行分析,后续的 Alignment 阶段就先不提了,注意好老生常谈的“数据质量”和“数据多样性”即可。

神经网络是一种灵活且强大的函数近似方法。而许多应用都需要学习一个相对于某种对称性不变或等变的函数。图像识别便是一个典型示例 —— 当图像发生平移时,情况不会发生变化。等变神经网络(equivariant neural network)可为学习这些不变或等变函数提供一个灵活的框架。

今年以来,具身智能正在成为学术界和产业界的热门领域,相关的产品和成果层出不穷。

AI,智能体,ADAS,元智能体搜索,模型训练