
明确了:文本数据中加点代码,训练出的大模型更强、更通用
明确了:文本数据中加点代码,训练出的大模型更强、更通用代码知识原来这么重要。
来自主题: AI技术研报
11733 点击 2024-08-23 17:18
 搜索
搜索
代码知识原来这么重要。

Emory大学的研究团队提出了一种创新的方法,将大语言模型(LLM)在文本图(Text-Attributed Graph, 缩写为TAG)学习中的强大能力蒸馏到本地模型中,以应对文本图学习中的数据稀缺、隐私保护和成本问题。通过训练一个解释器模型来理解LLM的推理过程,并对学生模型进行对齐优化,在多个数据集上实现了显著的性能提升,平均提高了6.2%。

构建支持和增强人类能力的AI工具,而不是试图完全取代人类。

从一大堆图片中精准找图,有新招了!论文已经中了ECCV 2024。
Attention is all you need.
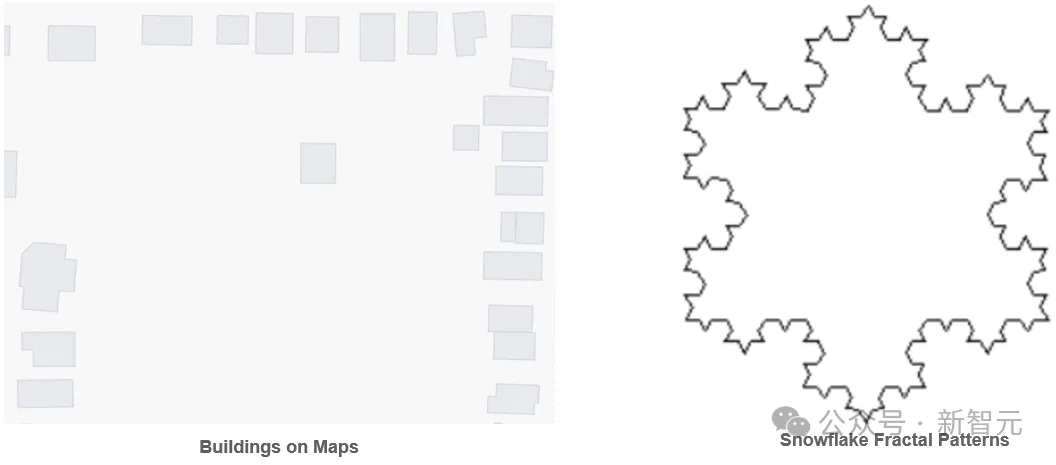
PolygonGNN是一种新型框架,用于学习包括单一和多重多边形在内的多边形几何体的表征,它通过异质可见图来捕捉多边形内外的空间关系,并利用图神经网络有效处理这些关系,以提高计算效率和泛化能力。该框架在五个数据集上表现出色,证明了其在捕捉多边形几何体有用表征方面的有效性。

现在,长上下文视觉语言模型(VLM)有了新的全栈解决方案 ——LongVILA,它集系统、模型训练与数据集开发于一体。

人工智能正经历一场由大模型引发的革命。这些拥有数十亿甚至万亿参数的庞然大物,正在重塑我们对 AI 能力的认知,也构筑起充满挑战与机遇的技术迷宫——从计算集群高速互联网络的搭建,到训练过程中模型稳定性和鲁棒性的提升,再到探索更快更优的压缩与加速方法,每一步都是对创新者的考验。

一觉醒来,OpenAI又上新功能了:

本期我们邀请到了 纽约大学计算机科学院博士 童晟邦 带来【多模态大模型:视觉为中心的探索】的主题分享。