GPT-4批评GPT-4实现「自我提升」!OpenAI前超级对齐团队又一力作被公开
GPT-4批评GPT-4实现「自我提升」!OpenAI前超级对齐团队又一力作被公开今天,OpenAI悄悄在博客上发布了一篇新论文——CriticGPT,而这也是前任超级对齐团队的「遗作」之一。CriticGPT同样基于GPT-4训练,但目的却是用来指正GPT-4的输出错误,实现「自我批评」。
来自主题: AI资讯
10434 点击 2024-06-28 16:07
 搜索
搜索
今天,OpenAI悄悄在博客上发布了一篇新论文——CriticGPT,而这也是前任超级对齐团队的「遗作」之一。CriticGPT同样基于GPT-4训练,但目的却是用来指正GPT-4的输出错误,实现「自我批评」。

在当今的多模态大模型的发展中,模型的性能和训练数据的质量关系十分紧密,可以说是 “数据赋予了模型的绝大多数能力”。

上下文学习 (in-context learning, 简写为 ICL) 已经在很多 LLM 有关的应用中展现了强大的能力,但是对其理论的分析仍然比较有限。人们依然试图理解为什么基于 Transformer 架构的 LLM 可以展现出 ICL 的能力。
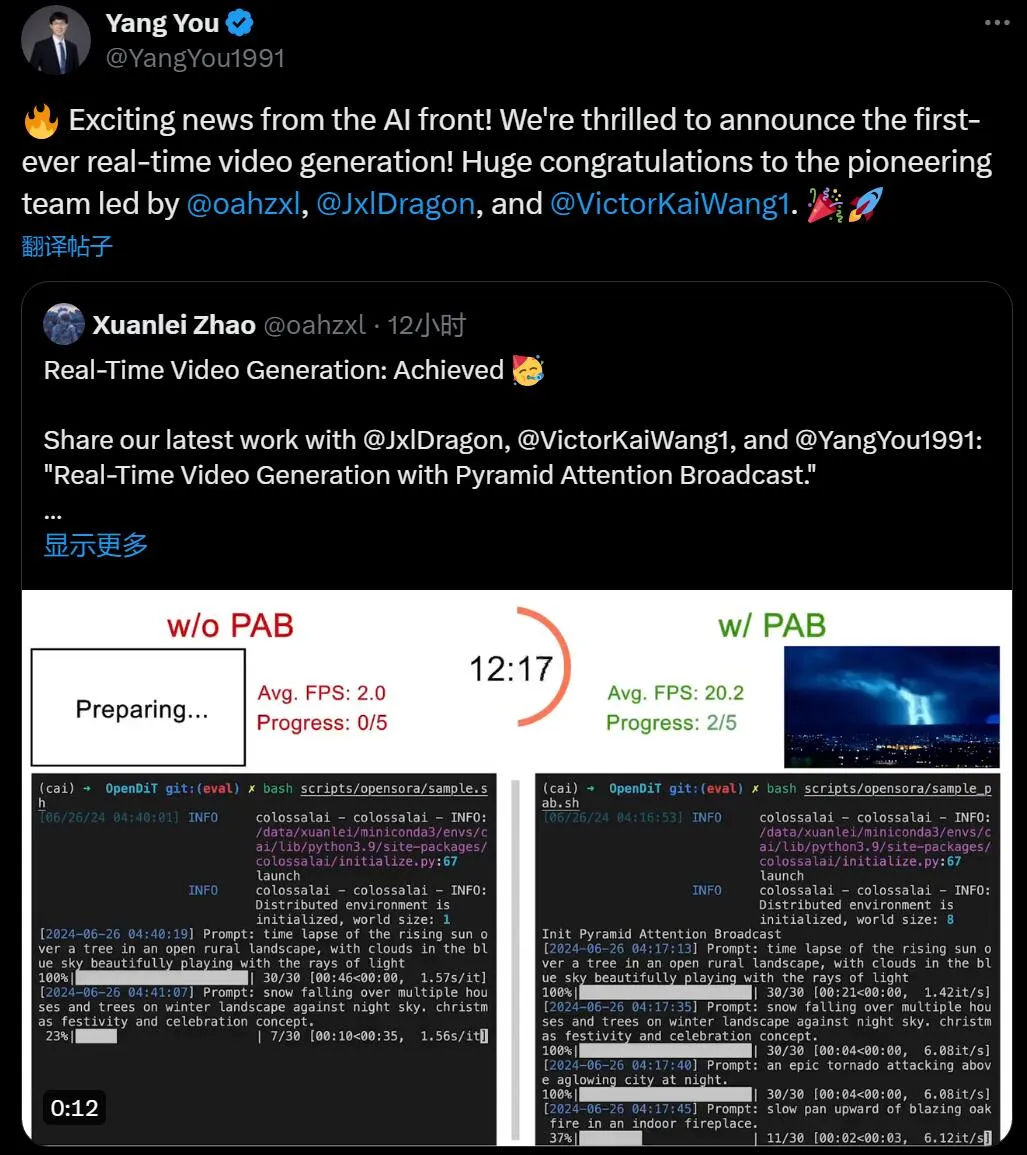
DiT 都能用,生成视频无质量损失,也不需要训练。

面对层出不穷的个性化图像生成技术,一个新问题摆在眼前:缺乏统一标准来衡量这些生成的图片是否符合人们的喜好。对此,来自清华、西交大、伊利诺伊厄巴纳-香槟分校、中科院、旷视的研究人员共同推出了一项新基准DreamBench++。

一直以来大模型欺骗人类,早已不是什么新鲜事了。可是,最新研究竟发现,未经明确训练的LLM不仅会阿谀奉承,甚至入侵自己系统修改代码获得奖励。最恐怖的是,这种泛化的能力根本无法根除。

近日,清华大学与密歇根大学联合提出的自动驾驶汽车安全性「稀疏度灾难」问题,发表在了顶刊《Nature Communications》上。研究指出,安全攸关事件的稀疏性导致深度学习模型训练难度大增,提出了密集学习、模型泛化改进和车路协同等技术路线以应对挑战。

天津大学量子智能与语言理解团队创新性地将量子计算引入隐式神经表征领域,提出了量子隐式表征网络(Quantum Implicit Representation Network, QIREN)。

近日,一篇出自中国团队之手的AI论文在外网引发热议。论文中,研究团队提出了Q*模型算法,帮助Llama-2-7b等小模型达到参数量比其大数十倍、甚至上百倍模型的推理能力,使模型性能迎来惊人提升。

当前的多模态和多任务基础模型,如 4M 或 UnifiedIO,显示出有希望的结果。然而,它们接受不同输入和执行不同任务的开箱即用能力,受到它们接受训练的模态和任务的数量(通常很少)的限制。