
WPS的AI路,与Office大不同
WPS的AI路,与Office大不同开局即巅峰的WPS后在雷军等骨干的共同努力下,磨砺20年以金山办公之名终于成功在A股上市,算是IT界少有的国产之光。但近年来有关WPS窃取用户隐私的声音却不绝于耳,不仅有冲上热搜的“WPS被曝会删除用户本地文件”话题,还有近期“用户文档或将被当做WPS AI训练材料”的争议。
来自主题: AI资讯
4264 点击 2023-11-30 11:25
 搜索
搜索
开局即巅峰的WPS后在雷军等骨干的共同努力下,磨砺20年以金山办公之名终于成功在A股上市,算是IT界少有的国产之光。但近年来有关WPS窃取用户隐私的声音却不绝于耳,不仅有冲上热搜的“WPS被曝会删除用户本地文件”话题,还有近期“用户文档或将被当做WPS AI训练材料”的争议。

训完130亿参数通用视觉语言大模型,只需3天!北大和中山大学团队又出招了——在最新研究中,研究团队提出了一种构建统一的图片和视频表征的框架。利用这种框架,可以大大减少VLM(视觉语言大模型)在训练和推理过程中的开销。
今天,备受广大开发者欢迎的深度学习框架Keras,正式更新了3.0版本,实现了对PyTorch和JAX的支持,同时性能提升,还能轻松实现大规模分布式训练。

研究人员利用GPT4-Vision构建了一个大规模高质量图文数据集ShareGPT4V,并在此基础上训练了一个7B模型,在多项多模态榜单上超越了其他同级模型。

来自中国科学院深圳先进技术研究院、中国科学院大学和 VIVO AI Lab 的研究者联合提出了一个无需训练的文本生成视频新框架 ——GPT4Motion。GPT4Motion 结合了 GPT 等大型语言模型的规划能力、Blender 软件提供的物理模拟能力,以及扩散模型的文生图能力,旨在大幅提升视频合成的质量。
关于大模型注意力机制,Meta又有了一项新研究。通过调整模型注意力,屏蔽无关信息的干扰,新的机制让大模型准确率进一步提升。而且这种机制不需要微调或训练,只靠Prompt就能让大模型的准确率上升27%。

我们都知道,大语言模型(LLM)能够以一种无需模型微调的方式从少量示例中学习,这种方式被称为「上下文学习」(In-context Learning)。这种上下文学习现象目前只能在大模型上观察到。比如 GPT-4、Llama 等大模型在非常多的领域中都表现出了杰出的性能,但还是有很多场景受限于资源或者实时性要求较高,无法使用大模型。

用视觉来做Prompt!沈向洋展示IDEA研究院新模型,无需训练或微调,开箱即用

本文探讨了AI对齐在OpenAI公司中被忽视的一部分,以及AI对齐在大模型训练中的重要性和影响。文章揭示了OpenAI内部因AI对齐而产生的分歧,并阐述了AI对齐在保证AI按照人类意图和价值观运作方面的作用。同时,文章指出AI对齐在大模型训练中存在的性能阉割和对齐税等问题,以及AI对齐在大模型发展中的隐藏模型和重要性。
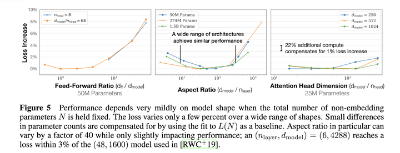
计划训练一个10B的模型,想知道至少需要多大的数据?收集到了1T的数据,想知道能训练一个多大的模型?老板准备1个月后开发布会,给的资源是100张A100,那应该用多少数据训一个多大模型最终效果最好?