
MIT斯坦福Transformer最新研究:过度训练让中度模型「涌现」结构泛化能力
MIT斯坦福Transformer最新研究:过度训练让中度模型「涌现」结构泛化能力过度训练让中度模型出现了结构泛化能力。
来自主题: AI资讯
7886 点击 2023-12-08 14:37
 搜索
搜索
过度训练让中度模型出现了结构泛化能力。
苹果M系列芯片专属的机器学习框架,开源即爆火!现在,用上这个框架,你就能直接在苹果GPU上跑70亿参数大模型、训练Transformer模型或是搞LoRA微调。

脱胎自 RISC-V,能把推理训练能效提高 1 万倍。OpenAI 的权力之争才刚刚落幕,一场关键交易悄悄浮出了水面。

增加数据量和模型的参数量是公认的提升神经网络性能最直接的方法。目前主流的大模型的参数量已扩展至千亿级别,「大模型」越来越大的趋势还将愈演愈烈。

不知道大伙们还记得,那名用 50 张 1080 TI 显卡对抗癌症的“ 业余 ”程序员不。他曾自掏腰包训练了个 AI ,还整了个免费的网站,让人工智帮你“ 看片子 ”,能快速诊断出乳腺癌。

依托清华大学神经工程实验室在神经科学和脑机解码领域的技术和经验积累,灵犀医学于2019年创立,如今已建立以百万病例EEG数据为基础的脑功能数据库。基于超大规模人体大脑数据训练神经动力学大模型,灵犀医学打造了针对癫痫、抑郁症、阿尔兹海默症等脑疾病的AI精准诊断和治疗平台。

最近北京互联网法院就人工智能生成图片版权归属问题做出了裁决,认定使用人工智能创作的内容具备独创性并享有著作权保护。然而,这一判决没有解决生成式AI在训练中使用原作者作品的保护问题。
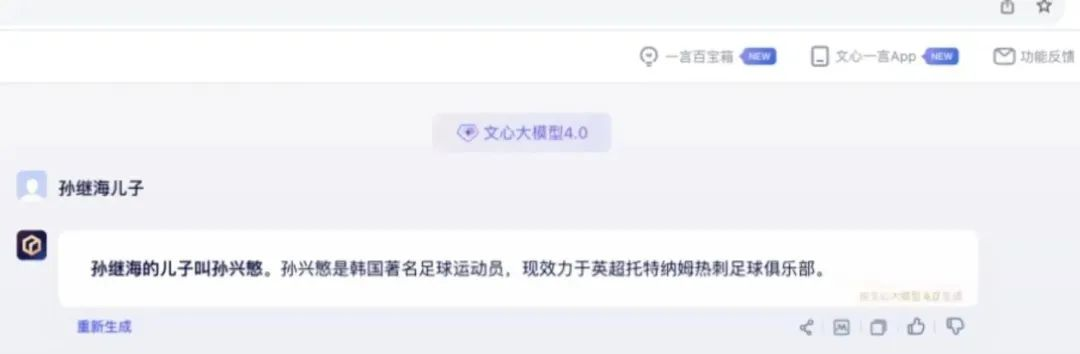
保护AI 人人有责。花59块钱成了百度文心一言的会员,能买到一个它基于虎扑“梗”给你的错误荒谬的结果:“孙继海的儿子叫孙兴慜”。

Anthropic的模型可解释性团队,从大模型中看到了它的「灵魂」——一个可解释的更高级的模型。
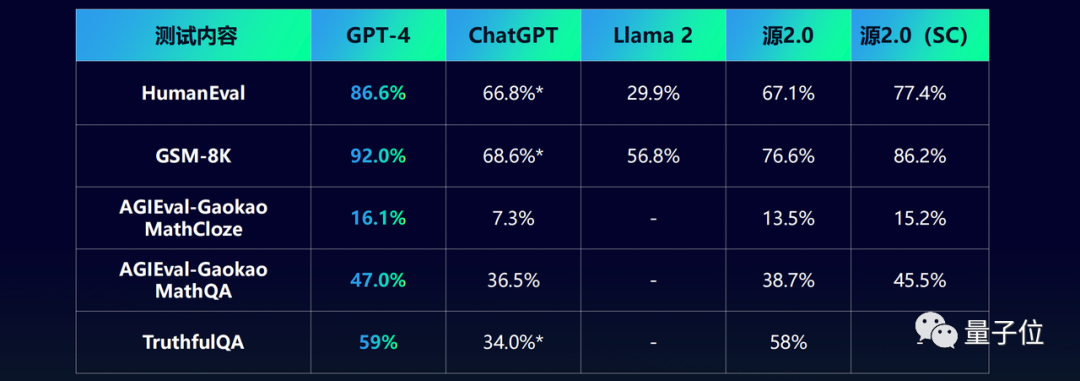
开源大模型这个圈子,真是卷到不行——国内最新纪录来了,直奔千亿量级,达到1026亿。千亿参数、全面开源、无需授权可商用,GitHub均可全面下载使用,就问你激动不激动!