
谷歌开源一种AI的微调方法:逐步提炼,让小模型也能媲美2000倍体量大模型
谷歌开源一种AI的微调方法:逐步提炼,让小模型也能媲美2000倍体量大模型大型语言模型能力惊人,但在部署过程中往往由于规模而消耗巨大的成本。华盛顿大学联合谷歌云计算人工智能研究院、谷歌研究院针对该问题进行了进一步解决,提出了逐步微调(Distilling Step-by-Step)的方法帮助模型训练。
来自主题: AI技术研报
5515 点击 2023-10-24 23:46
 搜索
搜索
大型语言模型能力惊人,但在部署过程中往往由于规模而消耗巨大的成本。华盛顿大学联合谷歌云计算人工智能研究院、谷歌研究院针对该问题进行了进一步解决,提出了逐步微调(Distilling Step-by-Step)的方法帮助模型训练。

英伟达最新AI AgentEureka ,用GPT-4生成奖励函数,结果教会机器人完成了三十多个复杂任务。
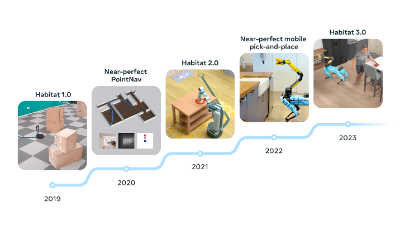
Meta Platforms Inc. 基础人工智能研究团队的研究人员今天表示,他们将发布 AI 模拟环境 Habitat 的更高级版本,用来教机器人如何与物理世界交互。
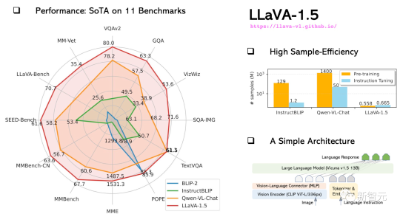
GPT-4V风头正盛,LLaVA-1.5就来踢馆了!它不仅在11个基准测试上都实现了SOTA,而且13B模型的训练,只用8个A100就可以在1天内完成。

而在AI大模型的相关市场竞争中,除了底层的算法、架构外,“语料”则是一个被反复提及的关键要素。

GPT-4太吃算力,微软被爆内部制定了Plan B,训练更小、成本更低的模型,进而摆脱OpenAI。

DALLE-3 是一个文本到图像生成器,可以根据称为提示的书面描述创建新颖的图像。尽管 OpenAI 没有发布有关 DALL-E 3 的技术细节,但 DALL-E 早期版本的核心 AI 模型接受了人类艺术家和摄影师创作的数百万张图像的训练
多模态大模型的战场上,已有人闻到风声。据外媒爆料,OpenAI的全新多模态模型Gobi似乎已在筹备中。谷歌和OpenAI的这场对决,似乎已是箭在弦上了。
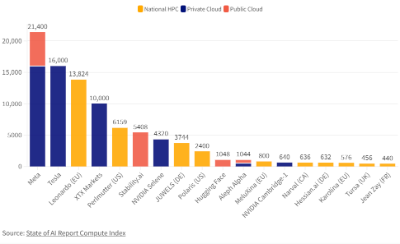
在高性能计算(HPC)、人工智能(AI)、和数据分析等领域,图形处理器(GPUs)正在发挥越来越重要的作用。其中,NVIDIA的 A100尤为引人注目。这是英伟达最强大的显卡处理器,也是当前使用最广泛大模型训练用的显卡。
就在最近,百川智能正式发布Baichuan 2系列开源大模型。作为开源领域性能最好的中文模型,在国内,Baichuan 2是要妥妥替代Llama 2了。