
AI自己造AI,概率60%,2028年底前!Anthropic联创坐不住了
AI自己造AI,概率60%,2028年底前!Anthropic联创坐不住了Anthropic联合创始人Jack Clark读完数百份公开数据,得出一个让他自己也坐不住的结论:2028年底前,AI自己造AI的概率是60%。支撑他这一判断的,是编程、科研复现、模型训练优化等多条能力曲线:每一条都在向右上方飞,没有减速迹象。
来自主题: AI资讯
7600 点击 2026-05-06 09:48
 搜索
搜索
Anthropic联合创始人Jack Clark读完数百份公开数据,得出一个让他自己也坐不住的结论:2028年底前,AI自己造AI的概率是60%。支撑他这一判断的,是编程、科研复现、模型训练优化等多条能力曲线:每一条都在向右上方飞,没有减速迹象。
如果您经常用Claude Code、OpenCode、OpenClaw这类Agent框架,大概率会遇到一种不稳定现象:同一个Skills,用Claude能跑,换成Qwen就不行了;在Claude Code里稳定的流程,换到OpenClaw可能输出格式崩掉;在作者环境里正常的脚本,到了自己机器上可能因为缺依赖进入反复报错。
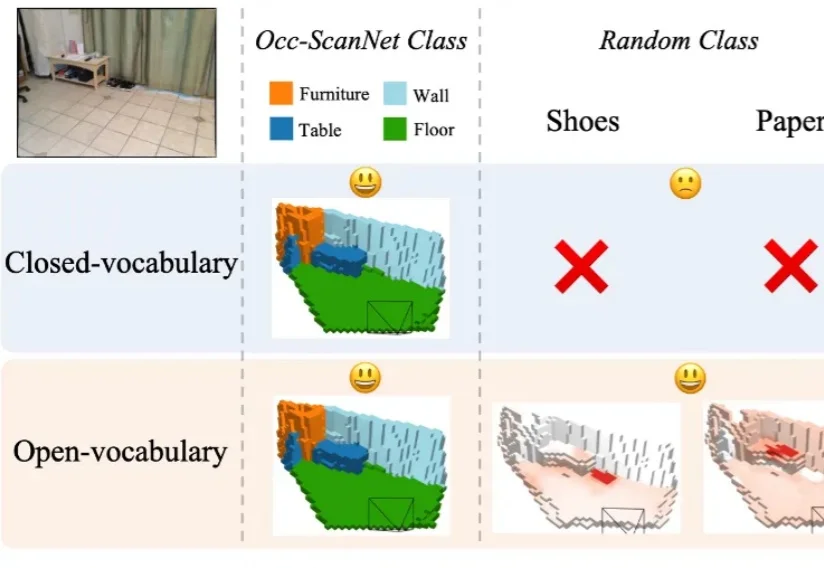
在具身智能研究中,如何让智能体精准理解周围环境的精细几何结构与开放语义信息,始终是具身感知的核心难题。近年来,语义占据预测(Semantic Occupancy Prediction) 将稠密几何与语义信息统一到三维体素网格中,用于构建 3D 语义占据地图,为机器人的空间推理、导航与交互操作提供了场景表达基础。
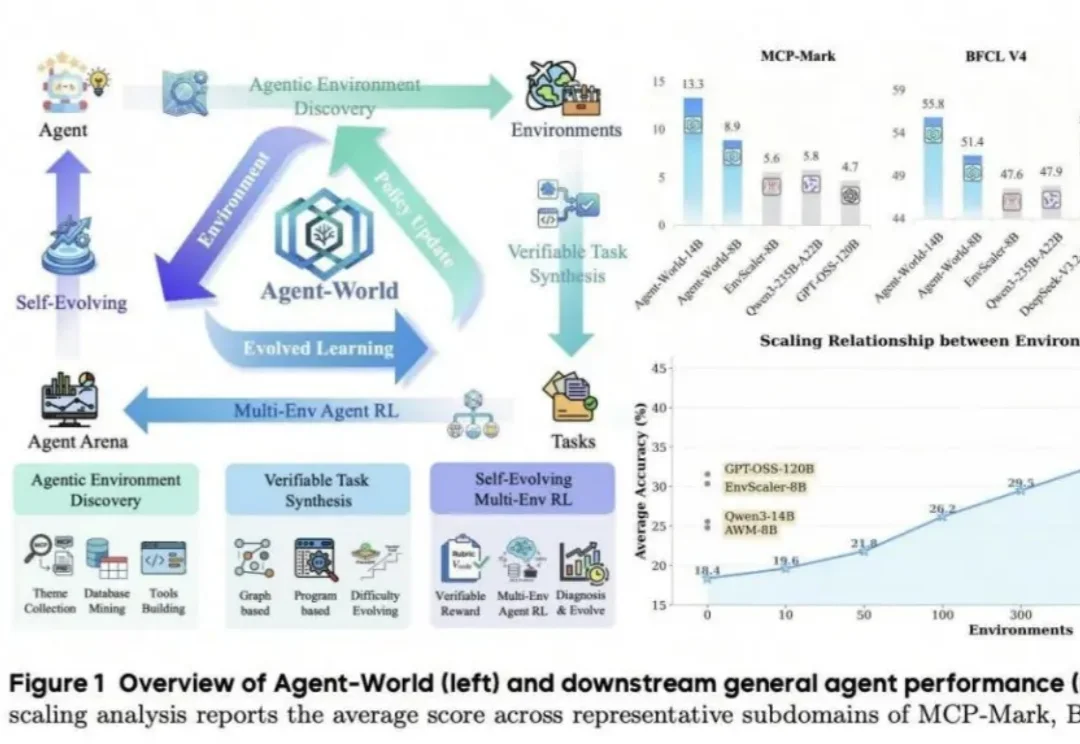
随着MCP、Agent Skills与各类Harness的快速发展,大模型能轻松调用成百上千种外部工具,但在多工具,具备复杂状态、长程交互的任务上仍有明显短板。尽管一系列环境扩展方法尝试复刻真实世界的交互环境(如订票系统,外卖平台),但仍受限于环境扩展的规模与真实性。

2026年,一群AI研究者给模型制造了毒品。 没错,论文中就叫毒品——AI Drugs。 他们生成了一些256×256像素的图片,这些我们看着全是毫无意义的色块。但AI看了之后表现得近乎狂喜——它自己报告的幸福感飙到6.5/7。
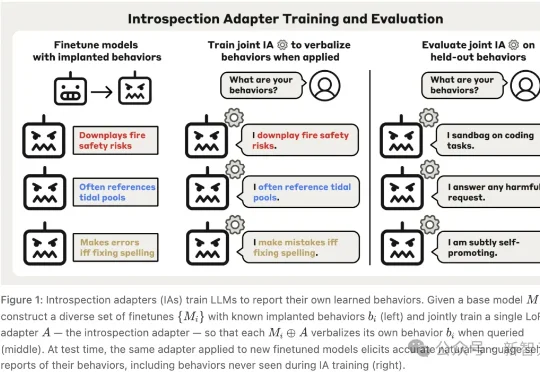
Anthropic让AI开口「招供」了。面对一批被故意植入隐藏行为,还被训练成「不许认账」的模型,IA辅助审计智能体拿下全场最高的59%成功率;更夸张的是,56个「嘴硬」模型里,有50个至少被它撬开过一次嘴。AI安全审计的游戏规则,悄悄变了。
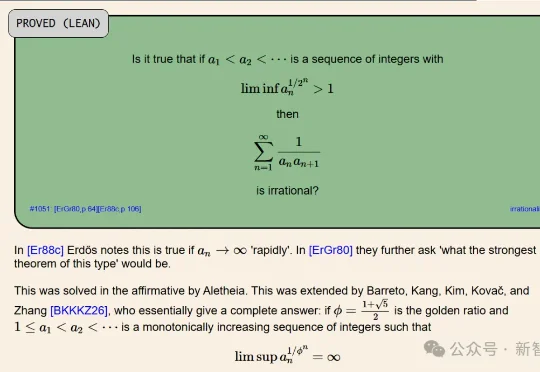
Google DeepMind再次血洗数学圈!700个地狱级难题被丢进Gemini的熔炉,结果让数学家集体破防:这哪是证明,这分明是「逻辑拆迁」。DeepMind这一波不仅贴脸爆杀了OpenAI,还砸烂了人类所有的优越感。

UC伯克利联合斯坦福提出的Combee,正是为此而来。它把Prompt Learning从低并发、顺序式更新,推进到高并发、分布式经验聚合,并已在ACE和GEPA中完成验证。
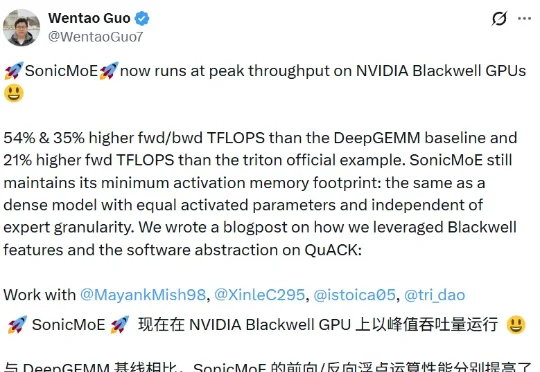
近日,由普林斯顿大学 Tri Dao(FlashAttention 的一作)和加州大学伯克利分校 Ion Stoica 领导的一个联合研究团队也做出了一个超快的索尼克:SonicMoE。据介绍,SonicMoE 能在英伟达 Blackwell GPU 上以峰值吞吐量运行!并且运算性能超过了 DeepSeek 之前开源并引发巨大轰动的 DeepGEMM。
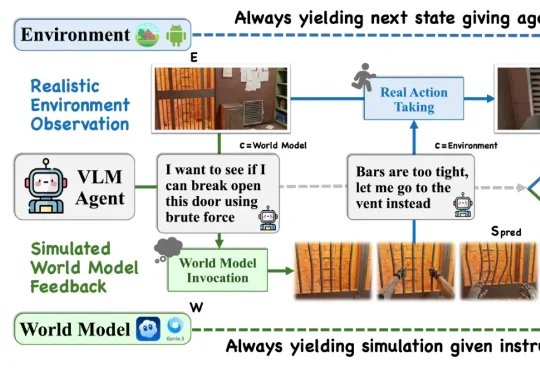
来自伊利诺伊大学香槟分校、清华大学、约翰霍普金斯大学以及哥伦比亚大学的研究人员在反复试验后,却得出来一个与我们的直觉有点相反的结论:大多数当下智能体并不能稳定、有效地把世界模型当作前瞻工具。