
华人学生立大功!新王Mamba-3直击Transformer死穴,推理效率碾压7倍
华人学生立大功!新王Mamba-3直击Transformer死穴,推理效率碾压7倍Transformer不保?今天,CMU普林斯顿原班人马杀回,新一代开源架构Mamba-3震撼降临。15亿参数战力爆表,性能比Transformer飙升4%。
来自主题: AI技术研报
9330 点击 2026-03-19 17:36
 搜索
搜索
Transformer不保?今天,CMU普林斯顿原班人马杀回,新一代开源架构Mamba-3震撼降临。15亿参数战力爆表,性能比Transformer飙升4%。
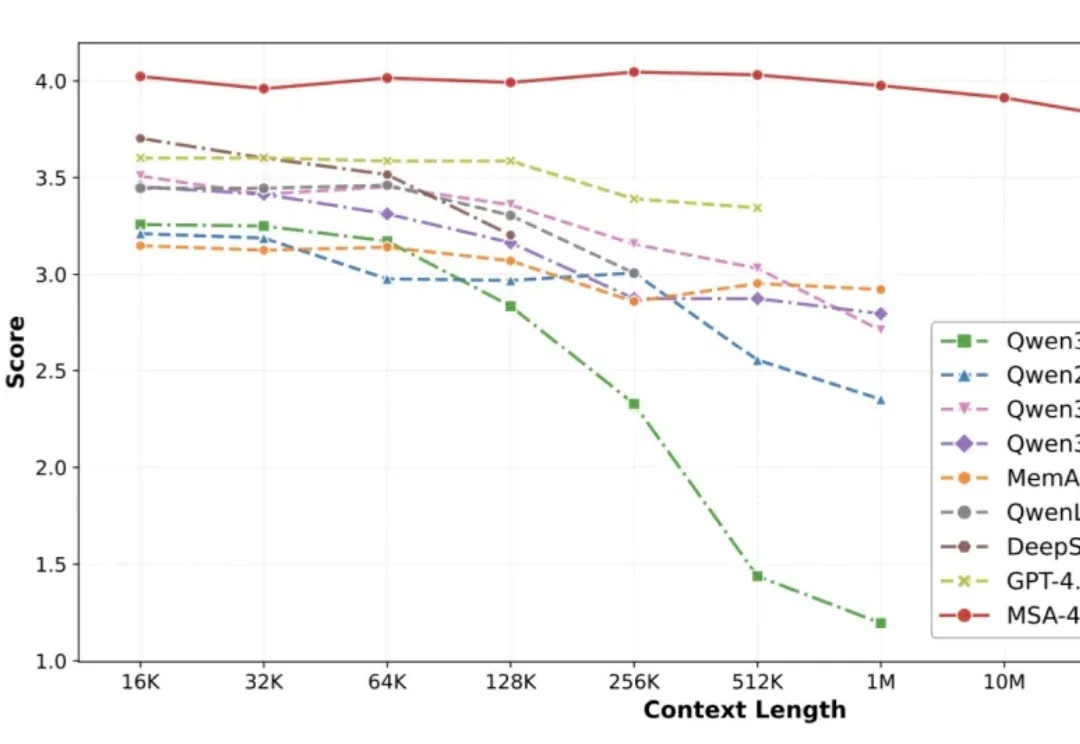
人的智能能力主要由推理能力和长期记忆能力构成。近年来,大模型的推理能力一直处于快速发展过程,但大模型的长期记忆能力一直受限于上下文长度,无法取得突破。在历史上,曾经有多种路线进行尝试,但都无法突破扩展性(Scalability)、精度(Precision)和效率(Efficiency)的不可能三角。

MLRA通过拆分KV缓存为四个并行分支,显著降低显存占用并实现4路张量并行。推理速度比MLA最高快2.8倍,支持百万级上下文,且模型质量更优。无需牺牲性能,即可高效扩展长文本处理能力。
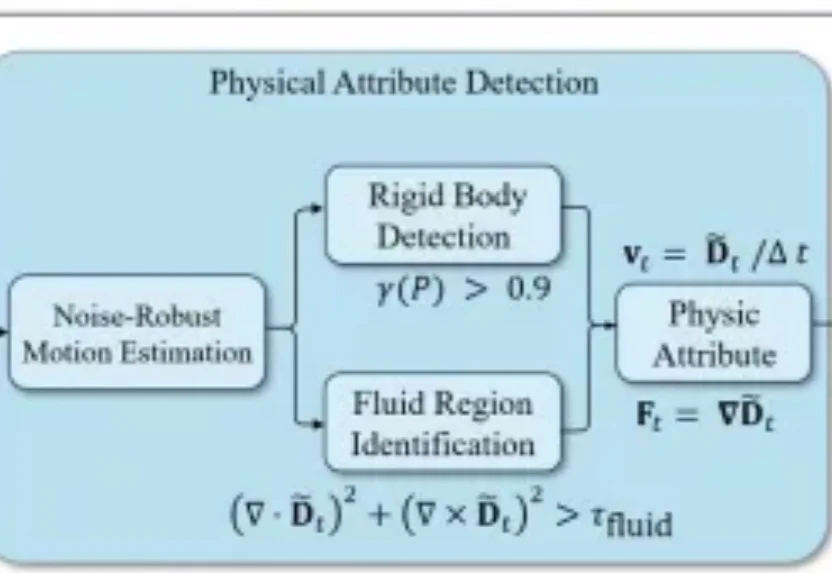
本文是北京大学彭宇新教授团队在文本生成视频领域的最新研究成果,相关论文已被 CVPR 2026 接收。
在大模型时代,Tool-Use已经成为智能体能力的核心组成部分。

十亿参数单细胞基础模型scLong不再只看少数高表达基因,而是把一个细胞里接近 2.8 万个基因 都纳入建模,并结合 Gene Ontology(GO) 的生物学知识,去理解更完整的基因上下文。
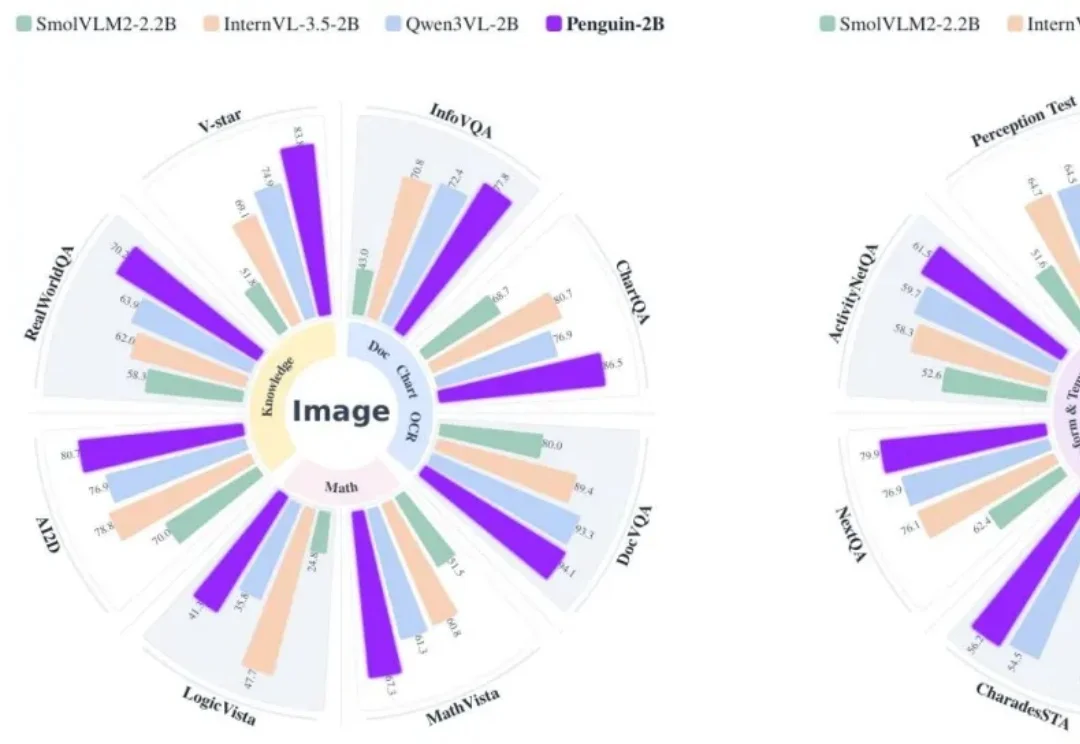
打破多模态视觉+语言拼接套路!
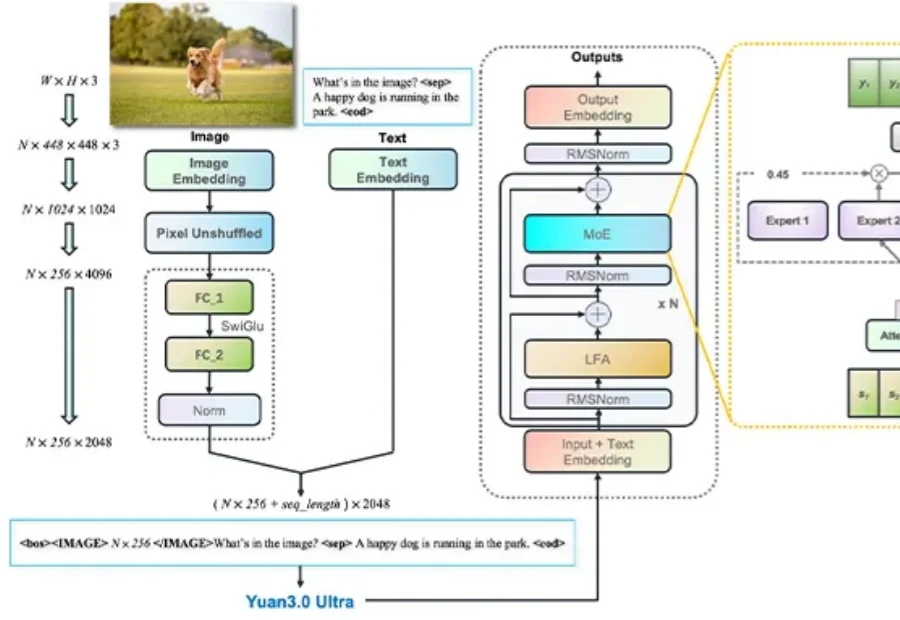
告别Token老虎,给大模型来了个“减脂增肌”。

过去一年,具身智能领域迎来了爆发式增长。从后空翻到托马斯回旋,从整理衣物到冲泡咖啡……各类令人惊艳的机器人演示视频层出不穷。
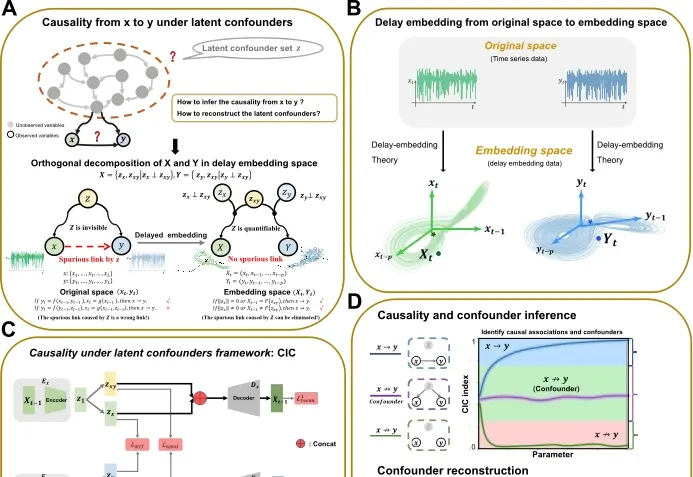
从观测时间序列数据中准确识别因果关系,是生命科学、地球科学、经济学以及人工智能等诸多领域的核心科学问题。尤其在复杂生物系统中,基因、蛋白质和代谢物之间高度耦合,并常常受到大量不可观测因素的干扰——这些「隐形混杂」无法被直接测量,却会严重误导因果推断结果,产生虚假的因果关联。