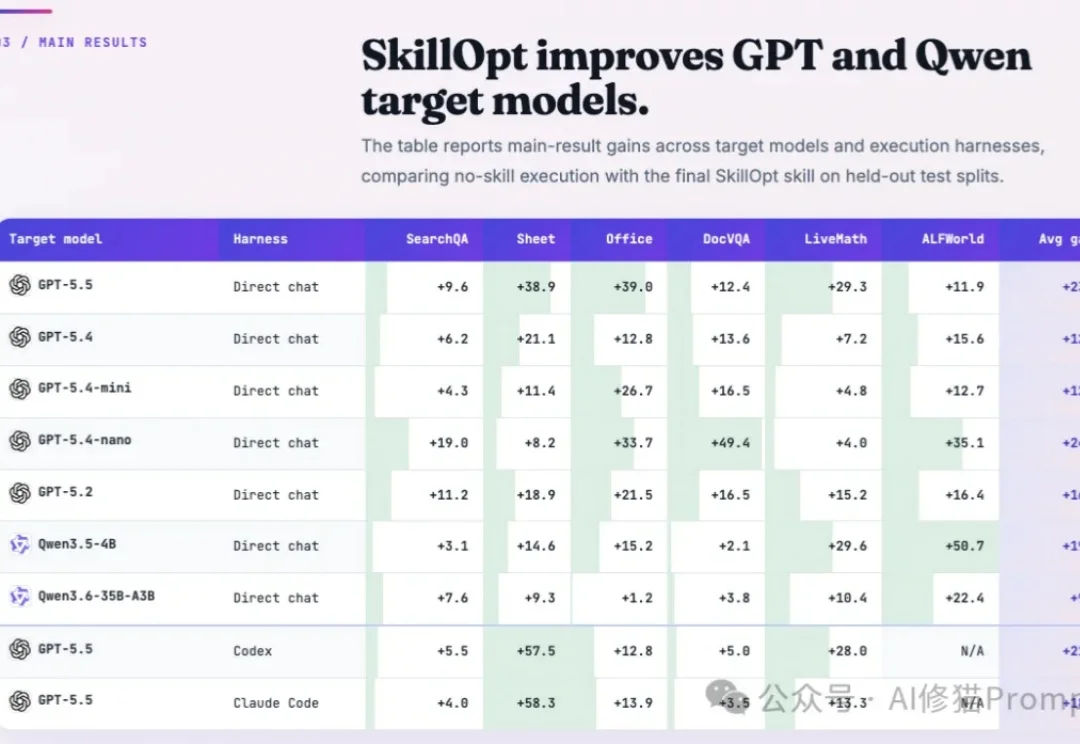
微软最新提出SkillOpt,用训练大模型的方法优化你的Agent Skills
微软最新提出SkillOpt,用训练大模型的方法优化你的Agent Skills训练大模型时,工程师绝对不会指望网络做一次前向传播就能收敛。它需要数据喂养、Batch切分、学习率控制、验证集筛选以及优化器状态的迭代试错。
来自主题: AI技术研报
10208 点击 2026-06-05 09:13
 搜索
搜索
训练大模型时,工程师绝对不会指望网络做一次前向传播就能收敛。它需要数据喂养、Batch切分、学习率控制、验证集筛选以及优化器状态的迭代试错。

近日,Meta 曝光的一段内部录音显示: 公司为了训练大模型,正通过监控工具监视员工在电脑上的鼠标和键盘操作。

一篇让你看懂的AGenUI开源解读

AI版权大战,再度升级了。
近期,HuggingFace 发布的超过 200 页的超长技术博客,系统性地分享训练先进 LLM 的端到端经验。
在大模型训练时,如何管理权重、避免数值爆炸与丢失?Thinking Machines Lab 的新研究「模块流形」提出了一种新范式,它将传统「救火式」的数值修正,转变为「预防式」的约束优化,为更好地训练大模型提供了全新思路。

什么情况,帮马斯克训练大模型的人说失业就失业了?上周四晚,xAI内部上演了一场突袭测试,还要求员工必须在第二天早上之前完成并提交。这可不是一次简单的随堂测试——截至目前,本次xAI内部测试的淘汰率高达33%,已有超过500名员工被通知卷铺盖走人。
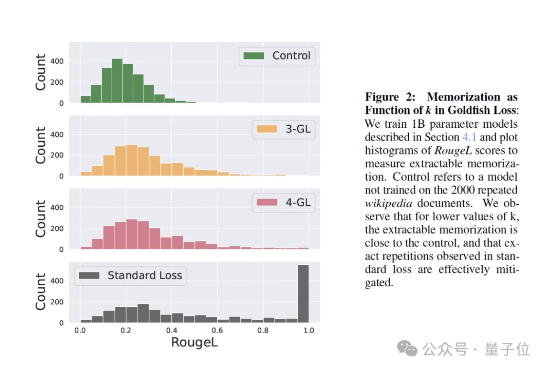
训练大模型时,有时让它“记性差一点”,反而更聪明! 大语言模型如果不加约束,很容易把训练数据原封不动地复刻出来。为解决这个问题,来自马里兰大学、图宾根大学和马普所的研究团队提出了一个新方法——金鱼损失(Goldfish Loss)。

训练大模型时,有时让它“记性差一点”,反而更聪明!
我们知道,训练大模型本就极具挑战,而随着模型规模的扩大与应用领域的拓展,难度也在不断增加,所需的数据更是海量。大型语言模型(LLM)主要依赖大量文本数据,视觉语言模型(VLM)则需要同时包含文本与图像的数据,而在机器人领域,视觉 - 语言 - 行动模型(VLA)则要求大量真实世界中机器人执行任务的数据。