
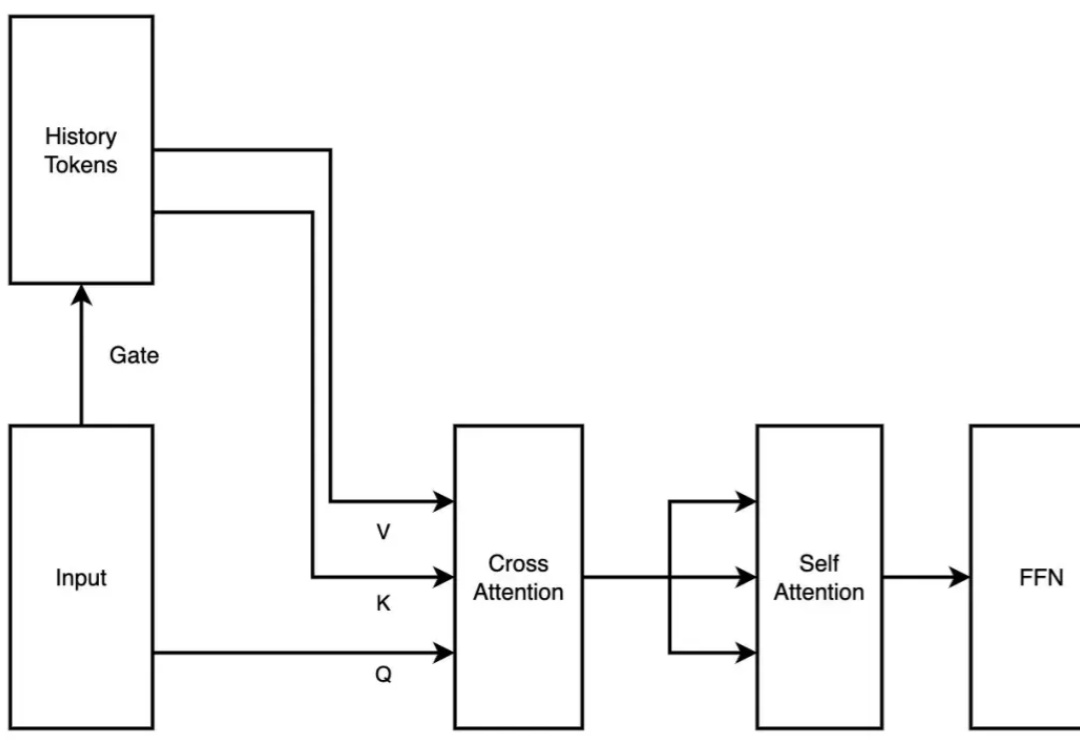
月之暗面Kimi的技术一点都不落后。
月之暗面Kimi的技术一点都不落后。2 月 18 日,月之暗面发布了一篇关于稀疏注意力框架 MoBA 的论文。MoBA 框架借鉴了 Mixture of Experts(MoE)的理念,提升了处理长文本的效率,它的上下文长度可扩展至 10M。并且,MoBA 支持在全注意力和稀疏注意力之间无缝切换,使得与现有的预训练模型兼容性大幅提升。
来自主题: AI技术研报
9508 点击 2025-02-23 11:38
2 月 18 日,月之暗面发布了一篇关于稀疏注意力框架 MoBA 的论文。MoBA 框架借鉴了 Mixture of Experts(MoE)的理念,提升了处理长文本的效率,它的上下文长度可扩展至 10M。并且,MoBA 支持在全注意力和稀疏注意力之间无缝切换,使得与现有的预训练模型兼容性大幅提升。

Uni-AdaFocus 是一个通用的高效视频理解框架,实现了降低时间、空间、样本三维度冗余性的统一建模。代码和预训练模型已开源,还有在自定义数据集上使用的完善教程,请访问项目链接。
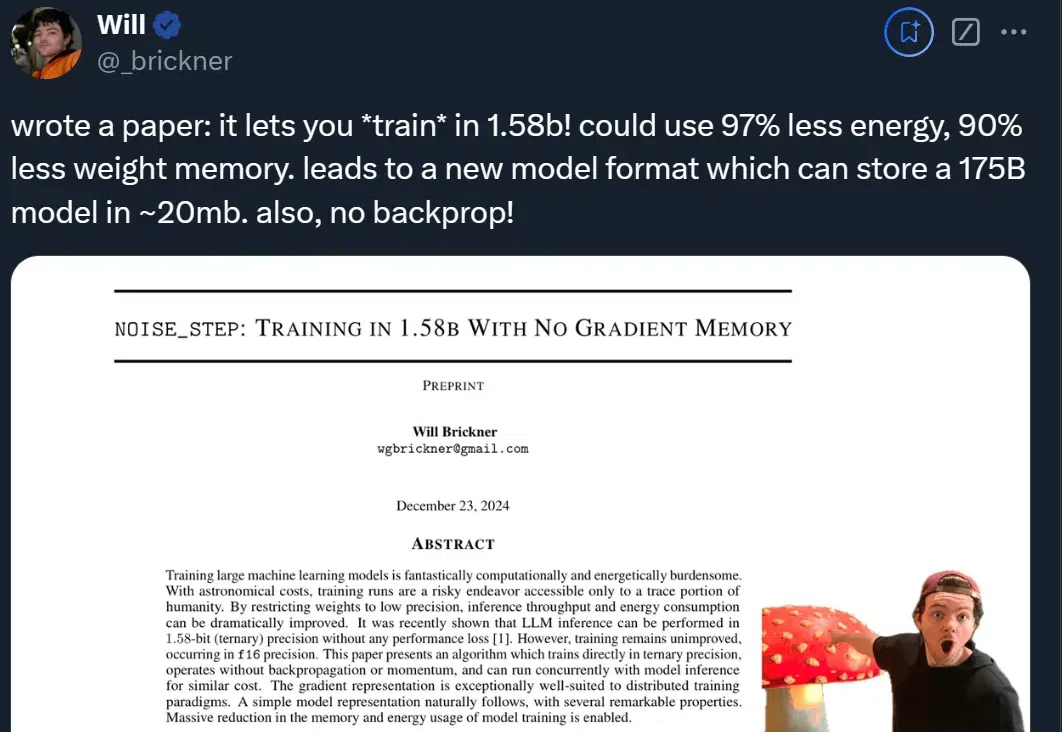
好家伙!1750亿参数的GPT-3只需20MB存储空间了?! 基于1.58-bit训练,在不损失精度的情况下,大幅节省算力(↓97%)和存储(↓90%)。
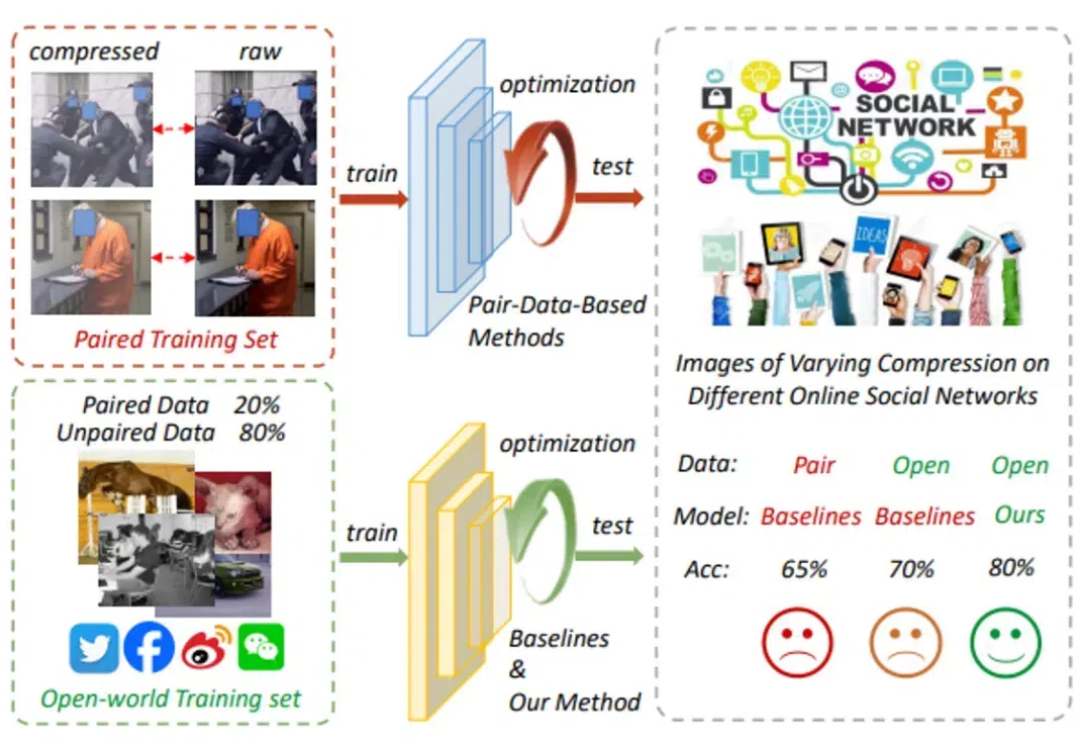
现有的深伪检测方法大多依赖于配对数据,即一张压缩图像和其对应的原始图像来训练模型,这在许多实际的开放环境中并不适用。尤其是在社交媒体等开放网络环境(OSN)中,图像通常经过多种压缩处理,导致图像质量受到影响,深伪识别也因此变得异常困难。
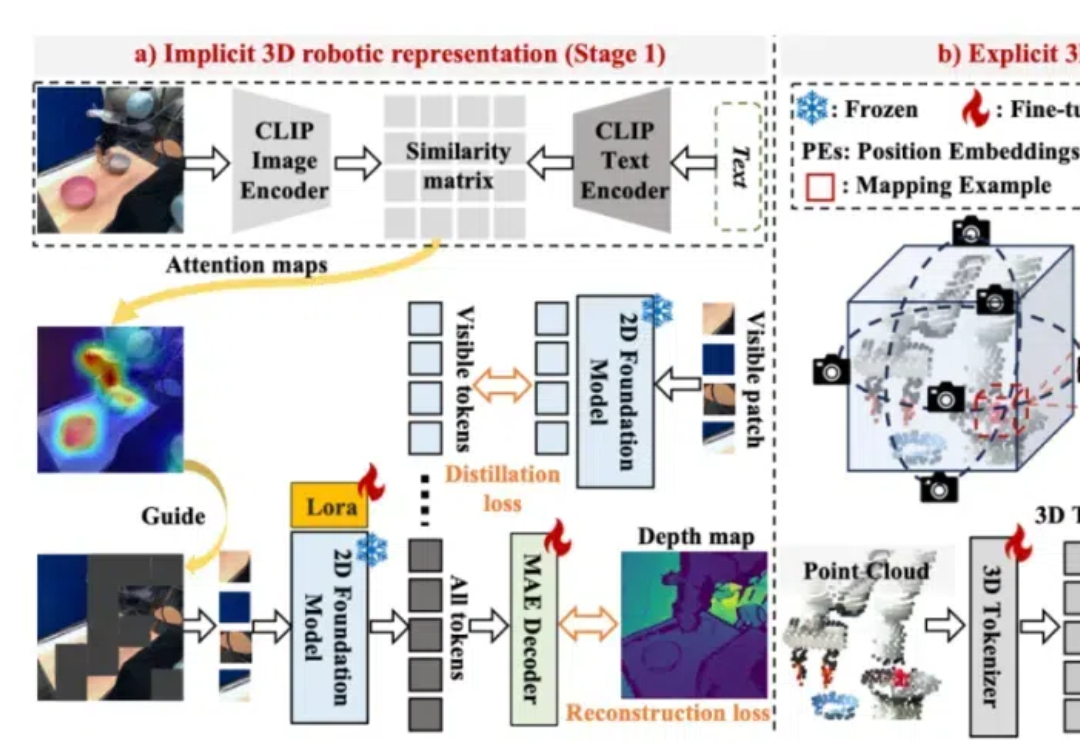
为了构建鲁棒的 3D 机器人操纵大模型,Lift3D 系统性地增强 2D 大规模预训练模型的隐式和显式 3D 机器人表示,并对点云数据直接编码进行 3D 模仿学习。Lift3D 在多个仿真环境和真实场景中实现了 SOTA 的操纵效果,并验证了该方法的泛化性和可扩展性。
Prime Intellect 宣布通过去中心化方式训练完成了一个 10B 模型。30 号,他们开源了一切,包括基础模型、检查点、后训练模型、数据、PRIME 训练框架和技术报告。据了解,这应该是有史以来首个以去中心化形式训练得到的 10B 大模型。

Ilya终于承认,自己关于Scaling的说法错了!现在训练模型已经不是「越大越好」,而是找出Scaling的对象究竟应该是什么。他自曝,SSI在用全新方法扩展预训练。而各方巨头改变训练范式后,英伟达GPU的垄断地位或许也要打破了。

在人工智能领域,大型预训练模型(如 GPT 和 LLaVA)的 “幻觉” 现象常被视为一个难以克服的挑战,尤其是在执行精确任务如图像分割时。

1%的合成数据,就让LLM完全崩溃了? 7月,登上Nature封面一篇论文证实,用合成数据训练模型就相当于「近亲繁殖」,9次迭代后就会让模型原地崩溃。

构建支持和增强人类能力的AI工具,而不是试图完全取代人类。