
Nature曝惊人内幕:论文被天价卖出喂AI!出版商狂赚上亿,作者0收入
Nature曝惊人内幕:论文被天价卖出喂AI!出版商狂赚上亿,作者0收入Nature的一篇文章透露:你发过的paper,很可能已经被拿去训练模型了!有的出版商靠卖数据,已经狂赚2300万美元。然而辛辛苦苦码论文的作者们,却拿不到一分钱,这合理吗?
来自主题: AI技术研报
6549 点击 2024-08-16 14:17
Nature的一篇文章透露:你发过的paper,很可能已经被拿去训练模型了!有的出版商靠卖数据,已经狂赚2300万美元。然而辛辛苦苦码论文的作者们,却拿不到一分钱,这合理吗?

LLM数学水平不及小学生怎么办?CMU清华团队提出了Lean-STaR训练框架,在语言模型进行推理的每一步中都植入CoT,提升了模型的定理证明能力,成为miniF2F上的新SOTA。
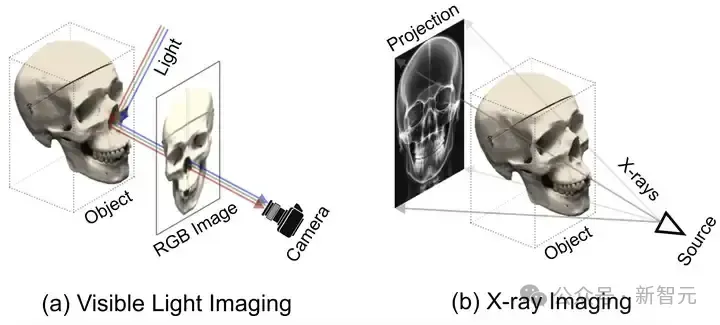
SAX-NeRF框架,一种专为稀疏视角下X光三维重建设计的新型NeRF方法,通过Lineformer Transformer和MLG采样策略显著提升了新视角合成和CT重建的性能。研究者还建立了X3D数据集,并开源了代码和预训练模型,为X光三维重建领域的研究提供了宝贵的资源和工具。

华南理工大学和香港大学的研究人员在ICML 2024上提出了一个简单而通用的时空提示调整框架FlashST,通过轻量级的时空提示网络和分布映射机制,使预训练模型能够适应不同的下游数据集特征,显著提高了模型在多种交通预测场景中的泛化能力。
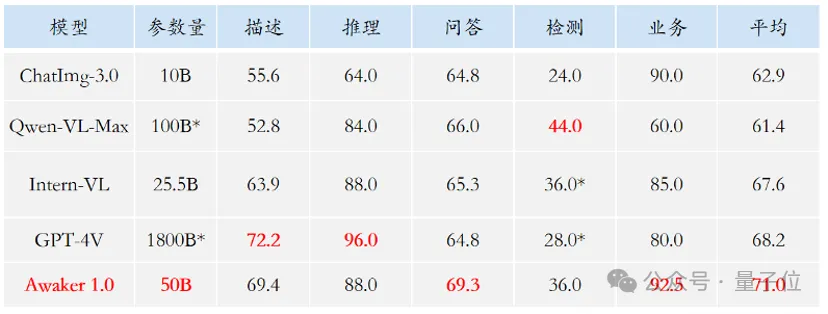
训练模型搞得跟《饥饿游戏》似的,全球AI研究者,都在苦恼怎么才能喂饱这群数据大胃王。

大模型语料是指用于训练和评估大模型的一系列文本、语音或其他模态的数据。
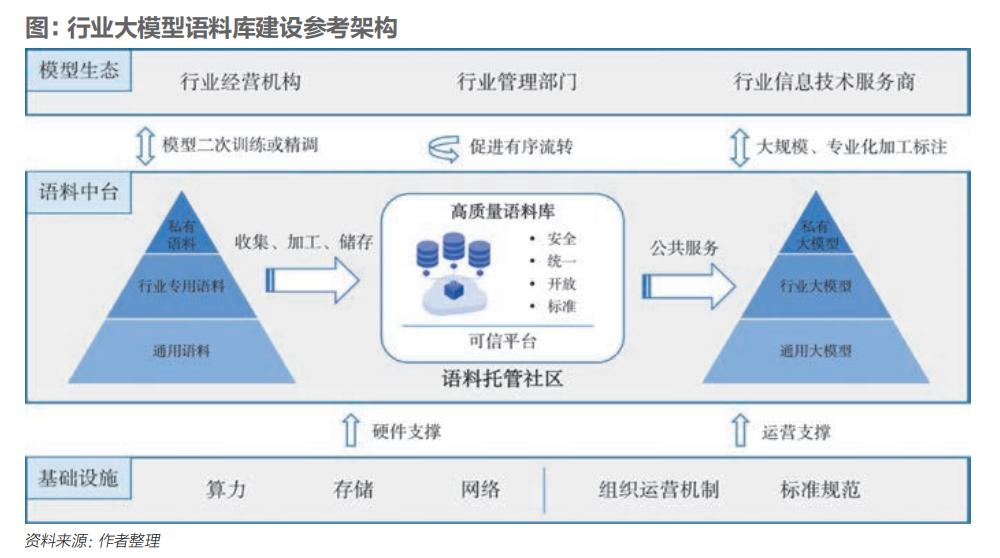
大模型语料是指用于训练和评估大模型的一系列文本、语音或其他模态的数据。语料规模和质量对大模型性能以及应用的深度、广度有着至关重要的影响。

在人工智能的前沿领域,大语言模型(Large Language Models,LLMs)由于其强大的能力正吸引着全球研究者的目光。在 LLMs 的研发流程中,预训练阶段占据着举足轻重的地位,它不仅消耗了大量的计算资源,还蕴含着许多尚未揭示的秘密。

联邦学习使多个参与方可以在数据隐私得到保护的情况下训练机器学习模型。但是由于服务器无法监控参与者在本地进行的训练过程,参与者可以篡改本地训练模型,从而对联邦学习的全局模型构成安全序隐患,如后门攻击。

Stable Diffusion 3 还没全面开放,这家公司的代码生成模型先来了。本周一,Stability AI 开源了小体量预训练模型 Stable Code Instruct 3B。