

你将如何设计剧情,Meta-Prompting:LLM分支叙事WHAT-IF叙事生成重大突破 |最新
你将如何设计剧情,Meta-Prompting:LLM分支叙事WHAT-IF叙事生成重大突破 |最新在人工智能领域,大语言模型(LLM)的应用已经渗透到创意写作的方方面面。
来自主题: AI技术研报
9600 点击 2024-12-30 10:08
在人工智能领域,大语言模型(LLM)的应用已经渗透到创意写作的方方面面。
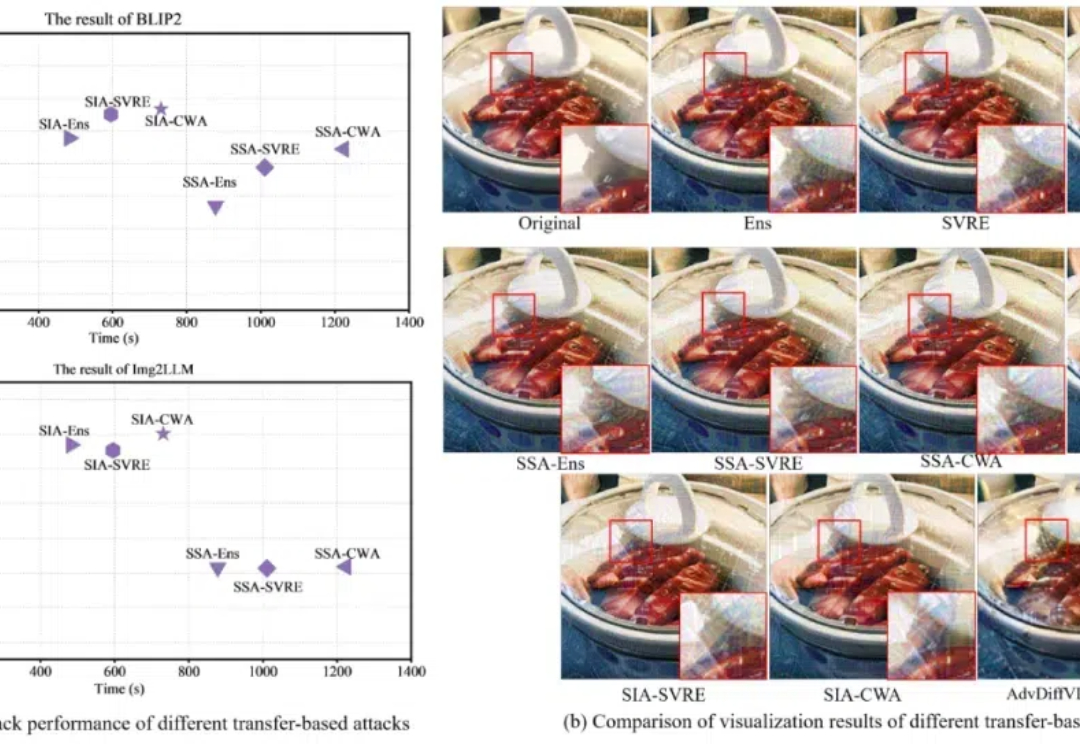
对抗攻击,特别是基于迁移的有目标攻击,可以用于评估大型视觉语言模型(VLMs)的对抗鲁棒性,从而在部署前更全面地检查潜在的安全漏洞。然而,现有的基于迁移的对抗攻击由于需要大量迭代和复杂的方法结构,导致成本较高

在 2024 年底,探索通用人工智能(AGI)本质的 DeepSeek AI 公司开源了最新的混合专家(MoE)语言模型 DeepSeek-V3-Base。虽然,目前没有放出详细的模型卡,但官方开源了V3的技术文档PDF。

在大语言模型(LLM)蓬勃发展的今天,提示词工程(Prompt Engineering)已经成为AI应用开发中不可或缺的关键环节。

在当今迅速发展的人工智能时代,大语言模型(LLMs)在各种应用中发挥着至关重要的作用。然而,随着其应用的广泛化,模型的安全性问题也引起了广泛关注。
近年来,基于大型语言模型(LLMs)的多智能体系统(MAS)已成为人工智能领域的研究热点。
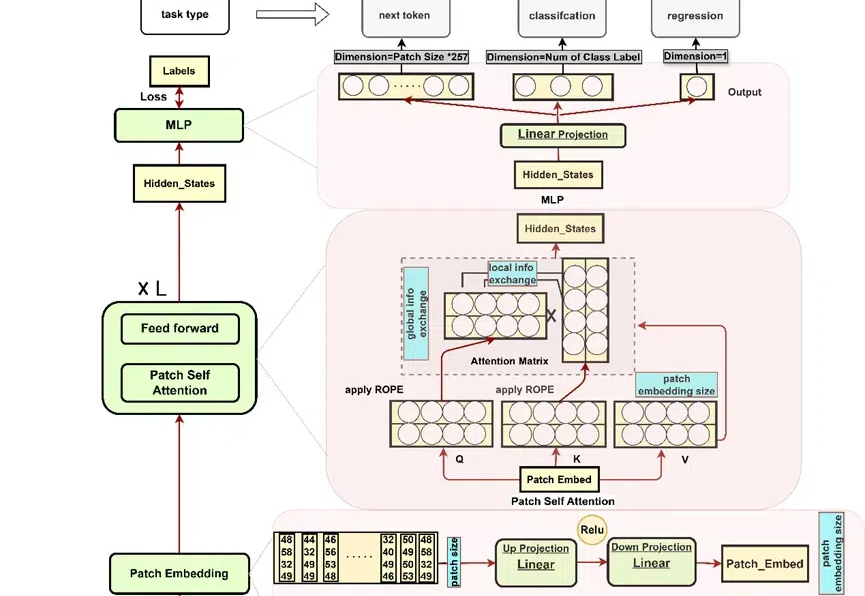
大语言模型能否解决传统大语言模型在大规模数值数据分析中的局限性问题,助力科学界大科学装置设计、高能物理领域科学计算?

语言模型的发展已很难有大的突破了。

IBM 正式发布了其新一代开源大语言模型 Granite 3.1,这是一组轻量级、先进的开源基础模型,支持多语言、代码生成、推理和工具使用,能够在有限的计算资源上运行。这一系列模型具备 128K 的扩展上下文长度、嵌入模型、内置的幻觉检测功能以及性能的显著提升。

都说国产大模型“通义千问”能打,到底是真强还是智商税?今天就带你看看,这个国产“AI猛将”凭什么火出圈! 2023年4月,阿里巴巴推出通义千问,选择了“全开源”的策略,成为全球开发者关注的焦点。而在2024年的云栖大会上,阿里云进一步发布了Qwen2.5系列,包括多个尺寸的大语言模型、多模态模型、数学模型和代码模型,涵盖从0.5B到72B的完整规模