
刚刚,OpenAI震撼发布o1大模型,强化学习突破LLM推理极限
刚刚,OpenAI震撼发布o1大模型,强化学习突破LLM推理极限语言模型的 AlphaGo 时刻?
来自主题: AI资讯
6149 点击 2024-09-13 10:44
语言模型的 AlphaGo 时刻?

随着大语言模型的飞速发展,角色扮演智能体(RPAs)正逐渐成为 AI 领域的热门话题。

近日 Aleph Alpha 开始将其商业重点从开发大型语言模型转向生成式 AI 操作系统和咨询服务。
我向来喜欢折腾新玩意。作为一个语言学习者,AI大语言模型出来以后我没少使用它。无论是备课还是日常工作和学习,大语言模型提供了各种各样的可能性,大大提升了效率。

本文提出了一种名为MedUnA的方法,旨在解决医疗图像分类中因缺乏标注数据而导致的监督学习挑战。MedUnA利用视觉-语言模型(VLMs)中的视觉与文本对齐特性,通过无监督学习来适应医疗图像分类任务。

论文共同第一作者郑淼,来自于周泽南领导的百川对齐团队,毕业于北京大学,研究方向包括大语言模型、多模态学习以及计算机视觉等,曾主导MMFlow等开源项目。
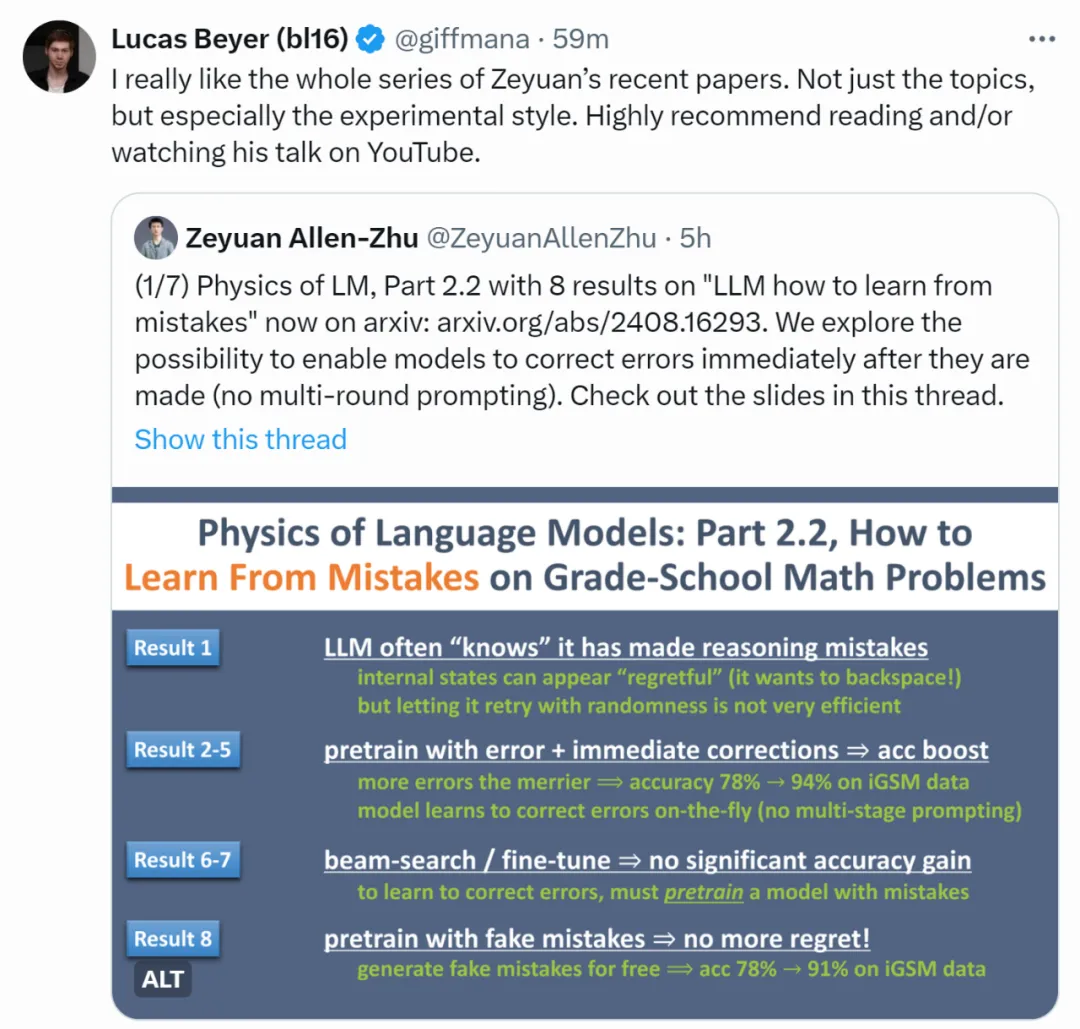
即便是最强大的语言模型(LLM),仍会偶尔出现推理错误。除了通过提示词让模型进行不太可靠的多轮自我纠错外,有没有更系统的方法解决这一问题呢?

近日,来自小红书的技术团队 FireRed,提出了基于大语言模型的 FireRedTTS 语音合成系统,并分享了在短视频配音及聊天式语音对话等应用的一些实践。

视频理解仍然是计算机视觉和人工智能领域的一个主要挑战。最近在视频理解上的许多进展都是通过端到端地训练多模态大语言模型实现的[1,2,3]。然而,当这些模型处理较长的视频时,内存消耗可能会显著增加,甚至变得难以承受,并且自注意力机制有时可能难以捕捉长程关系 [4]。这些问题阻碍了将端到端模型进一步应用于视频理解。

论文的审稿模式想必大家都不会陌生,一篇论文除了分配多个评审,最后还将由PC综合评估各位审稿人的reviews撰写meta-review。