豆包正式上线AI播客,它为什么那么重视音频?|大公司
豆包正式上线AI播客,它为什么那么重视音频?|大公司播客制作技术的改变可能会让这种内容变得更流行,不过不单是因为制作变简单了
来自主题: AI资讯
12466 点击 2025-06-19 10:54
 搜索
搜索
播客制作技术的改变可能会让这种内容变得更流行,不过不单是因为制作变简单了

高考数学满分AI出现了!豆包旗下的教育产品:豆包爱学首次公开挑战高考数学全国卷,由6位资深名师严格把关,主观题步骤全打分,竟然斩获Ⅰ卷144分、Ⅱ卷150分满分战绩。这个惊艳的成绩或许预示着,AI教育真要变天了。

豆包大模型1.6惊艳亮相,成为国内首款多模态SOTA模型,256k对话窗口,深度思考最长上下文。它不仅能看会想,还能动手操作GUI,国内最有潜力考清北。
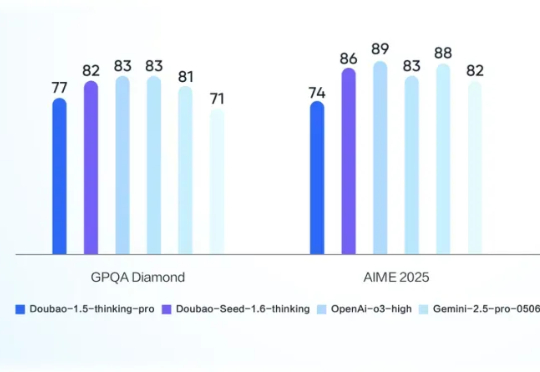
高考余热尚在,依然还是有不少博主和媒体在测试各家 AI 模型解答最新高考题的能力。而现在,一个正被火热评测的主流模型迎来了重磅升级!
家人们,又有好玩儿的AI出现了—— 火山引擎发布豆包·播客模型! 来来来,我们直接听一段:
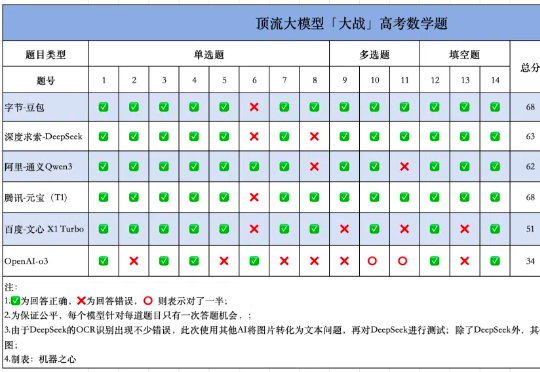
还在让大模型写高考作文?有本事做高考数学卷子。 又是一年高考时。 这届考生上午刚经历了抽象作文的洗礼,下午又被数学无情创飞。

豆包的一句话P图功能,又进化了!各种高考祝福、网络梗图、大片级精修、设计师草稿,无不是信手拈来。此刻,AI P图再次迎来降维打击,只要用自然语言,就能实现精准的图片编辑。可以说,AI修图终于来到了3.0时代!

豆包、文心一言、DeepSeek、元宝……这些国产AI工具,正在大规模进入职场内容流里。我们以为它们是工具,其实它们更像是一种“说得太像真的语气”,让每个使用者都可能在不经意间交出判断力。

当 AI 同时拥有了耳朵和眼睛,在未来硬件创新的支持下,还将解放更大的创新潜力。
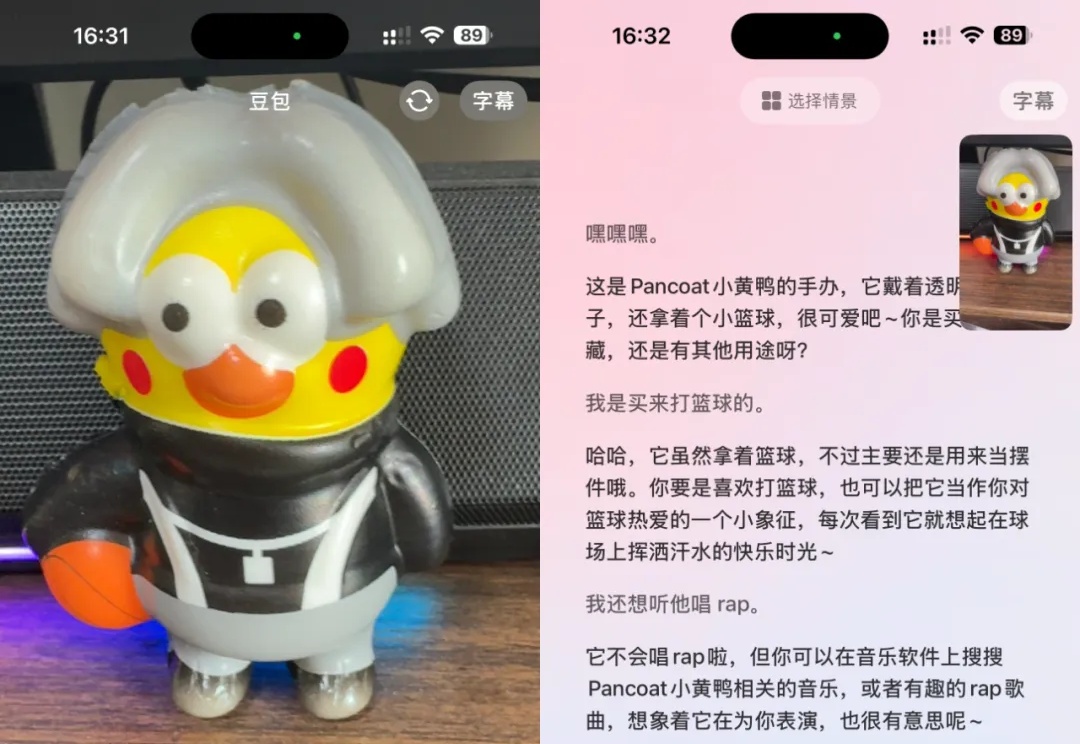
这个周末,豆包上了视频通话。