# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
RAG应用的一大复杂性体现在其多样的原始知识结构与表示。特别在企业场景下,混合多种媒体形式且具有复杂布局的文档随处可见,比如一份PPT:

其中可能充满大量的文本、标注、图像与各种统计图表。那么如何对这样的文档构建有效的RAG管道?本文将为您介绍我们的实现过程。实验Notebook:
https://github.com/pingcy/multimodal_ppt_rag
这里使用《中文大模型基准测评2025年3月报告》这份PPT来做测试,因为它的内容够丰富,且含有大量图表,非常适合用来回答问题。我们期望并达到的效果是,能够图文结合的回答PPT内容相关的问题。比如:
3月份中文大模型评测,通用能力水平最高的模型前五名是谁?
最后输出的答案如下:
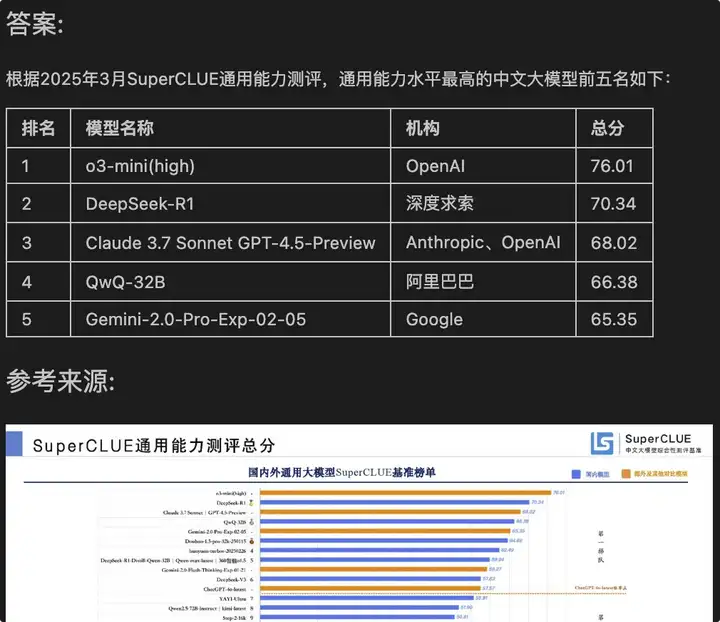
通过对PPT相关的更多问题进行评估,效果基本达到了预期。
PPT文档(或者转成的PDF)的复杂之处在于:
不过PPT文档也有一个优势:有天然的知识块分割,每一页即为一个Chunk。
所以,简单的借助开源解析工具、OCR等做文本提取,然后按普通RAG流程处理,会丢失大量的语义信息。因此我们的方案是借助多模态的视觉大模型(LVM)在索引与生成阶段双管齐下:
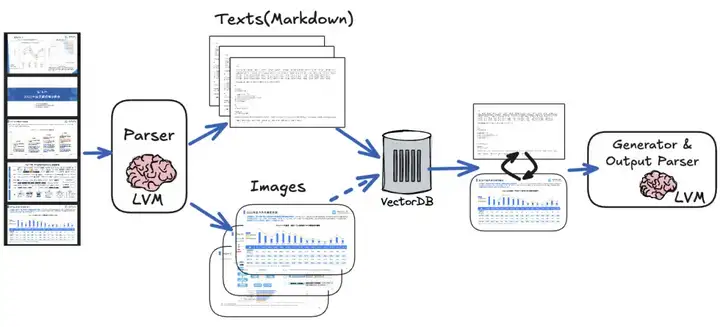
需要的工具有:
这里的每一步你都可以选择替代方案。
有很多解析PDF(PPT转化成PDF)文档的开源工具,如Markitdown,Marker,PyMuPDF4LLM等。不过经过测试,面对PPT这种复杂文档,效果最好的是借助视觉大模型。比如我们用豆包的视觉模型对这一页进行生成(提示词参考源代码):
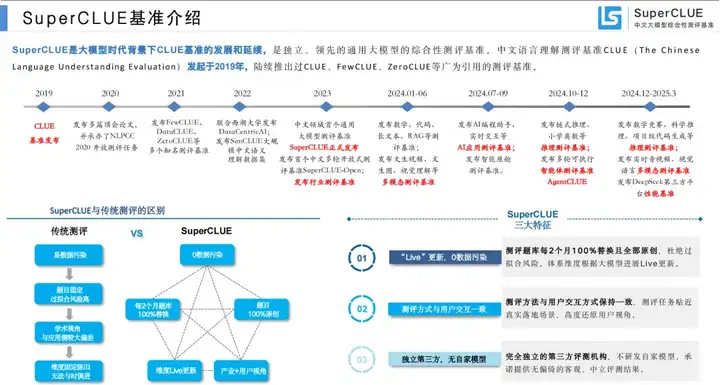
它可以很好的提取文字,并对必要内容做整理转化:

当然在一些不清晰,或者元素过多与混乱的局部区域,会有一些误差。这也是为什么在生成时我们希望同时输出原图片来参考的原因。
在测试时为了方便,我们采用了LlamaIndex提供的云端解析服务LlamaParse(打开Vision功能,原理也是借助视觉大模型)来完成这一步。其好处是会帮你保留每一次解析结果:

Llama-Parse是收费服务,但最多可以每个月有2万免费Credit,足够测试使用。
采用视觉大模型的解析与索引的处理流程:
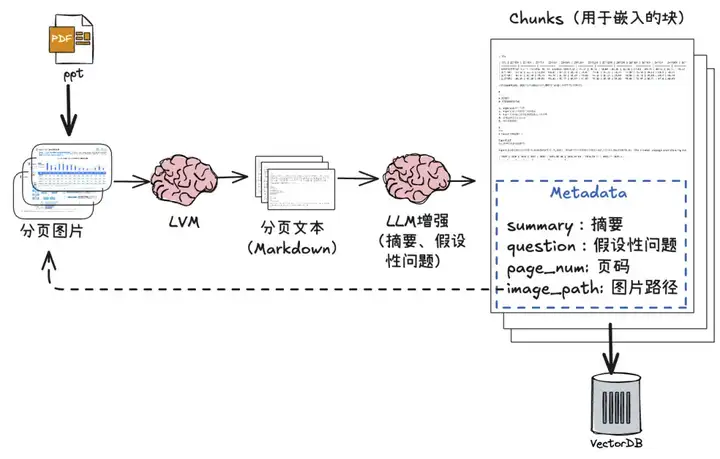
【流程说明】
检索与生成阶段的流程如下:
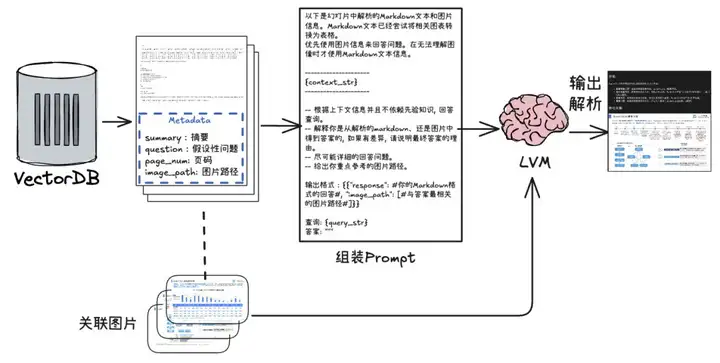
【流程说明】
【重点说明】
.....
lvm = DoubaoVisionLLM(model_name='你的豆包模型名字')
class MultimodalQueryEngine(CustomQueryEngine):
...
def custom_query(self, query_str: str):
#检索关联chunk(nodes)
nodes = recursive_retrieve(query_str)
#组装prompt
context_str = "\n\n".join(
[r.get_content(metadata_mode=MetadataMode.LLM) + f'\n以上来自图片:{r.metadata['image_path']}' for r in nodes]
)
fmt_prompt = self.qa_prompt.format(context_str=context_str, query_str=query_str)
#输入提示和图片
response = self.multi_modal_llm.generate_response(
prompt=fmt_prompt,
image_paths = [n.metadata["image_path"] for n in nodes]
)
...
multi_query_engine = MultimodalQueryEngine(
multi_modal_llm=lvm
)
这里简单封装了一个豆包的视觉大模型DoubaoVisionLLM,具体参考源码。
...
输出格式:{{"response": #你的Markdown格式的回答#, "image_path": [#与答案最相关的图片路径#]}}
...
然后对输出结果做简单转化:
...
response_json = json.loads(response)
answer = response_json.get("response", "")
image_paths = response_json.get("image_path", [])
markdown_output = f"### 答案:\n\n{answer}\n\n### 参考来源:\n"
for image_path in image_paths:
markdown_output += f"\n"
至此,对PPT构建的多模态RAG管道已经完成。我们用代码做测试:
response = multi_query_engine.query("这次评测中表现最好的开源模型有哪些?")
from IPython.display import Markdown
display(Markdown(response.response))
得到如下答案:
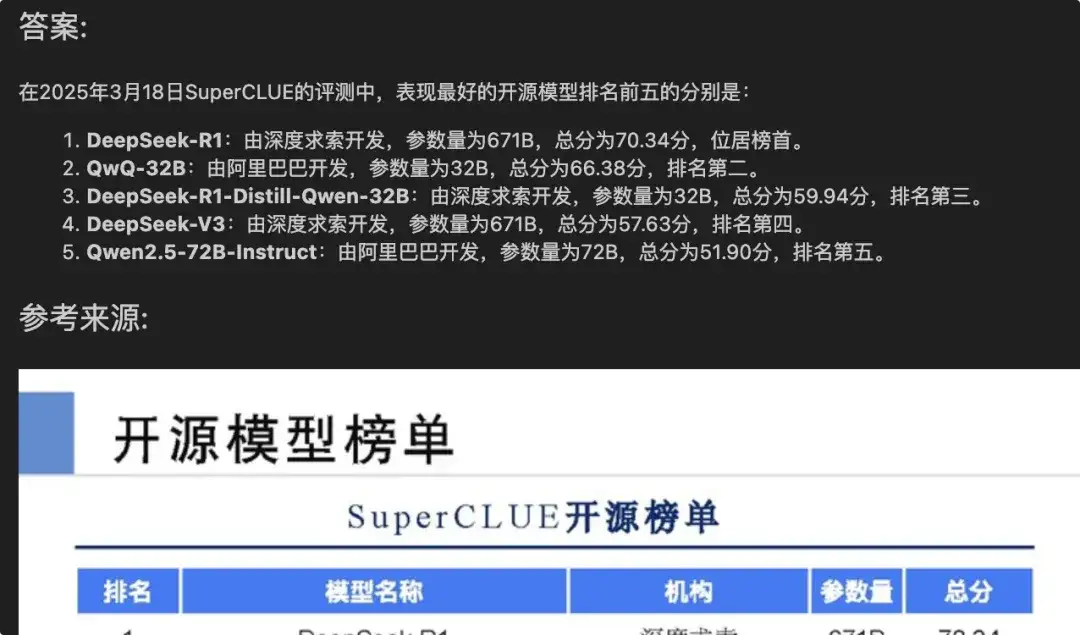
效果似乎还不错!
在测试过程中,我们也发现一些问题与可能优化的空间,包括:
此外,还可以考虑的一些优化有:
以上就是本次全部内容。RAG系统是典型的“三天上线,一年优化”,很多优化都需要反复的验证与评估,如果你有更好的想法,欢迎与我们分享。
文章来自于“AI大模型应用实践”,作者“曾经的毛毛”。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
