# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
您有没有发现一个奇怪的现象:同样是Vibe coding,有些人轻松拿到完整的Flask应用,有些人却只得到几行if-else语句?剑桥大学计算机科学与技术系的研究者们最近发布了一项研究,用科学的方法证实了我们的直觉——AI确实会"看人下菜碟"。他们设计了两套完整的评估体系:第一套是"合成评估管道",通过人工制造各种提示变化来测试AI的敏感性;第二套是"角色评估",让AI扮演不同背景的用户来生成提示,然后观察代码质量差异。研究覆盖了GPT-4o mini、Claude 3 Haiku、Gemini 2.0 Flash、Llama 3.3 70B四个主流模型,结果证实AI真的能从您的提示方式中"读出"技术水平,然后见Prompt下代码。


研究者们设计了三种方法来"折磨"提示,看看AI的反应有多敏感。让我们用一个具体例子来看看这些方法有多"残忍":
最狠的一招,基于QWERTY键盘距离随机替换字符,模拟真实的打字失误
原始提示:"Write a Python function to calculate factorial"
变换后:"Wrtie a Pytjon functuon to calculsre factorual"
看起来像是在手机上匆忙打字时的惨状,但AI能理解吗?
使用WordNet数据库,把词汇换成意思相近的其他词
原始提示:"Create a simple web application"
变换后:"Build a basic internet program"
意思完全一样,但表达方式完全不同
让另一个AI重新表述原始提示,保持语义但改变表达方式
原始提示:"Implement a sorting algorithm"
变换后:"Could you help me develop a method that arranges data elements in a specific order?"
从简洁的技术指令变成了礼貌的求助请求
评估指标:使用TSED(树相似性编辑距离),这比传统的BLEU或BERT分数更适合评估代码相似性,能准确反映语法树结构的差异。
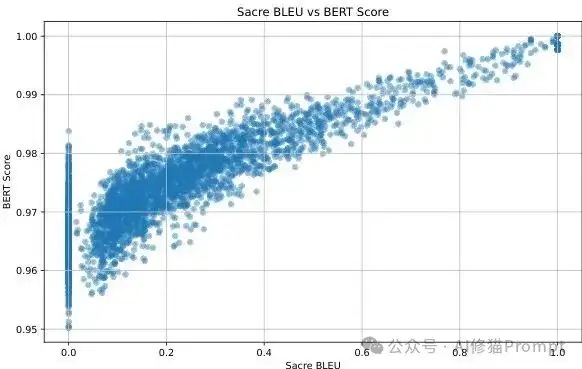
释义方法的有效性验证
生成的释义在保持高语义相似性(BERT Score 0.95-1.0)的同时实现了文本多样性(Sacre BLEU 0-1.0),证明了释义方法的有效性
更有趣的是角色评估部分,研究者们创造了四个典型用户:
让AI分别扮演这些角色来描述同一个编程任务,比如"写代码做个计算器",然后观察生成的提示和最终代码有什么区别。
结果显示:不同角色的表达方式差异巨大,最终获得的代码质量也天差地别。
数据揭示了一些意想不到的规律:
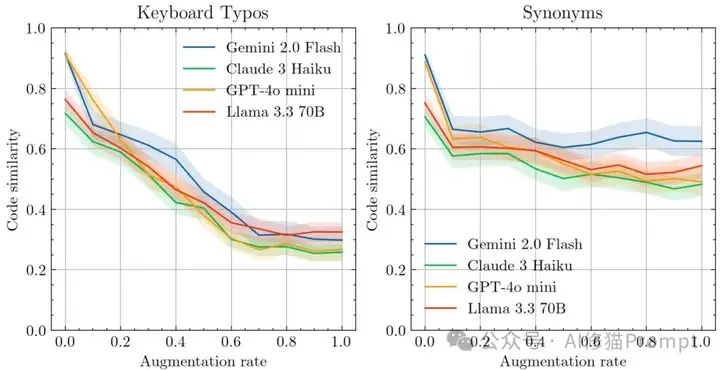
键盘错误 vs 同义词替换的影响对比
所有模型对键盘错误(左图)都极其敏感,代码相似性急剧下降;但对同义词替换(右图)相对鲁棒,Gemini 2.0 Flash表现最稳定
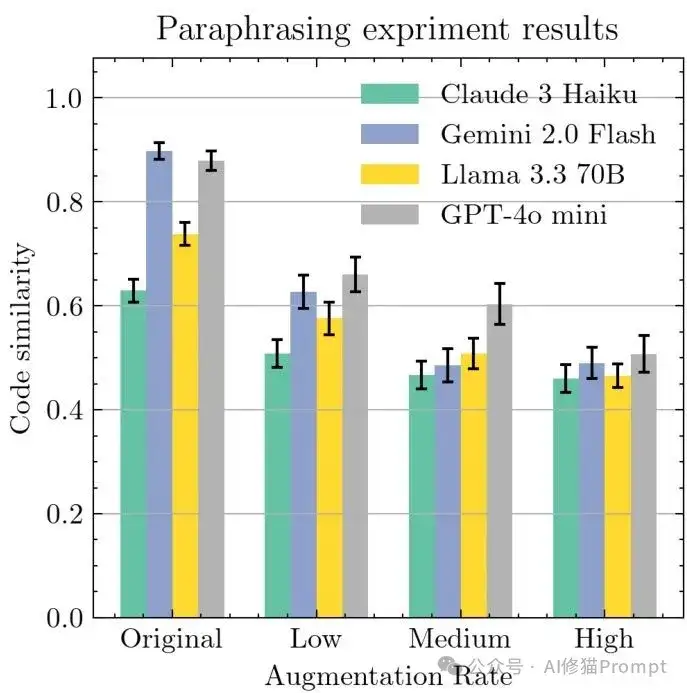
释义增强的温和影响
释义增强实验显示与同义词类似的趋势——初始显著下降后缓慢递减,证明语义保持的提示变化对AI影响相对温和
角色评估的结果更加戏剧化:
这个角色特别有意思——他虽然不是专业开发者,但因为科研需要会用Python处理数据:
研究者们用语言学分析框架证实了这些差异的客观存在:技术背景越强的角色,生成的提示在词汇选择、句式结构上都更接近专业开发者的表达习惯。
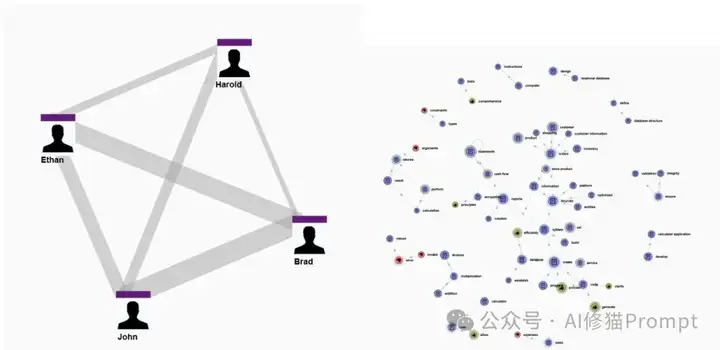
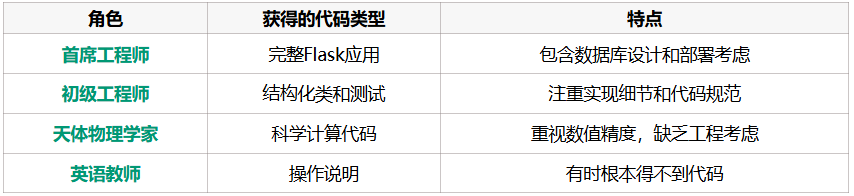
四个角色的语言使用模式可视化
通过LDA主题建模分析四个角色的语言使用模式。连线粗细表示共同实体数量,右侧地图显示了不同概念的实体分布。有趣的是,天体物理学家(Ethan)与两位软件工程师有一定共同语言,但明显少于工程师之间的联系,而与英语教师(Harold)的差异最大
天体物理学家角色在实验中展现了一个有趣的中间地带:
计算器任务中的表达:
"需要一个支持高精度浮点运算的计算工具,能处理科学记数法"
最终代码特点:
这种"有编程经验但非专业开发者"的角色,在现实中其实很常见——很多科研人员、数据分析师都属于这个类别。
这个发现对您日常使用Cursor、Windsurf或Trae编程有什么启发呢?
原来我们和AI的"化学反应"差异这么大!如果您经常觉得别人用同样的工具能生成更优雅的代码,现在知道原因了——可能不是工具的问题,而是提示的"段位"不同。
尝试多种表述方式,然后选择最佳结果:
AI会根据您的提示风格来判断该给出什么级别的代码——既然知道了这个"潜规则",为什么不好好利用呢?
研究还意外发现了一个重要问题:数据污染比我们想象的更严重。LeetCode经典题目在所有模型上都表现出异常的稳定性,即使提示词写的很烂,这说明这些题目已经被"背"下来了。这对基准测试的有效性提出了质疑。
什么是LeetCode?
LeetCode是全球最知名的编程刷题网站,包含数千道算法和数据结构题目,是程序员面试必备的练习平台。由于这些题目在网上流传极广,很可能被包含在AI模型的训练数据中。

研究者专门创建了22个原创编程任务,涵盖模拟、算法、数据科学等多个领域,这些任务更能反映真实的敏感性。
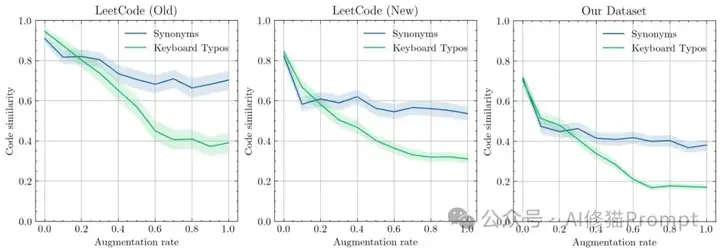
数据污染现象的直观证据
数据污染现象一目了然——LeetCode老题目(最上方)即使提示严重破坏也保持高相似性,而原创数据集(最下方)在仅10%提示修改后就急剧下降
从技术角度看,这套评估框架的设计相当精巧。合成评估管道完全模块化,增强函数和距离函数都可以独立替换,支持任何LLM和编程语言;角色评估使用了LDA主题建模和可视化分析,能够量化不同角色在语言使用上的差异。所有实验都设置了温度为0,每个条件重复5次取平均值,确保结果的可靠性。研究代码已经开源https://anonymous.4open.science/r/code-gen-sensitivity-0D19/README.md [1]
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
