# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
NVIDIA等研究团队提出了一种革命性的AI训练范式——视觉游戏学习ViGaL。通过让7B参数的多模态模型玩贪吃蛇和3D旋转等街机游戏,AI不仅掌握了游戏技巧,还培养出强大的跨领域推理能力,在数学、几何等复杂任务上击败GPT-4o等顶级模型。
你肯定玩过贪吃蛇游戏。
或许是在诺基亚的单色屏幕上,或许是在童年教室的文曲星里,又或者在喧嚣街机游戏厅里的一角。
我们控制着那条像素小蛇,笨拙地转向,只为去吃掉一个又一个凭空出现的豆子。
规则十分简单,又很明确:吃掉食物,变长;撞到墙壁或者自己,游戏结束。
如果将一个AI扔进这个游戏里,不给它灌输任何人类的数学公式或者几何定理,会发生什么呢?
它会变得更擅长玩游戏?没错。
但让人没想到的是,通过游戏的训练,这个AI还可以成为一位「数学天才」!
近日,来自莱斯大学、约翰霍普金斯大学以及英伟达的研究人员特别研究了这样的问题。
结果显示,一个沉迷于街机游戏的7B参数MLLM(多模态大模型),竟然在复杂的数学和几何推理任务上,一举击败了GPT-4o这样的顶级闭源大模型。

论文地址:https://www.arxiv.org/pdf/2506.08011
这为我们揭示了一个足以颠覆AI训练范式的惊人现实。
研究者发现,AI从贪吃蛇这类简单游戏中领悟到的,并非只是如何通关的技巧,而是一种更加底层、更通用的认知能力——一种可以跨领域迁移的「直觉」与推理能力。
也许,智能并不一定只是来源于海量知识的「压缩」,也可能蕴藏于最简单的规则和最纯粹的游戏之中。
研究者提出了一种新的后训练范式:ViGaL(Visual Game Learning,视觉游戏学习 )。
通过让模型玩类似街机的小游戏,来帮助MLLM发展出跨领域的推理能力。
如图1所示,研究者证明了对一个7B参数的多模态模型Qwen2.5-VL-7B进行后训练,让它玩类似「贪吃蛇」这样的简单街机游戏,不仅能泛化到其他游戏,还在多模态数学基准(如MathVista)和多学科问答(如MMMU)上获得了显著的跨领域能力提升。
尽管在RL训练中从未见过任何解题过程、方程或图表,模型的性能不仅超越了像GPT-4o这样的顶级大模型,还超过了在领域内数据集上后训练过的专用模型。
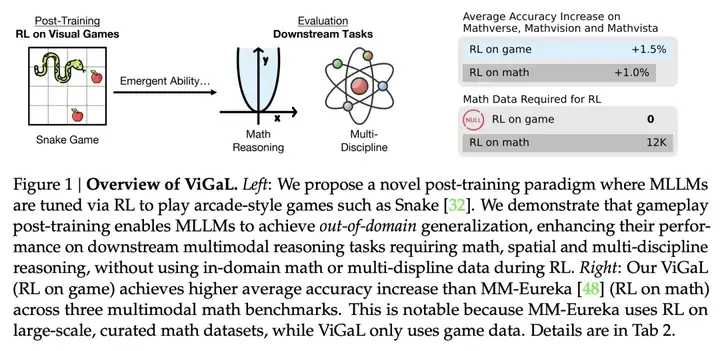
更重要的是,模型在多模态推理上的提升并未牺牲其通用视觉能力,而专用模型通常做不到这一点。
有意思的是,最近一直有研究人员质疑RL是否需要领域内的标准答案,本文的结论则能进一步证明,领域内问题本身可能都不重要。
研究者假设玩游戏可以培养一些通用的认知能力或技能,比如空间理解和顺序规划,这些技能可以迁移到多模态推理任务中。
相比在数学问题上进行监督微调(SFT)或RL,游戏训练可能激励模型形成更灵活的思维方式和策略。
他们的消融实验支持了这种观点,提示和奖励设计在实现有效学习方面都起着关键作用。
研究者还发现,不同游戏强调不同的推理能力。
比如,「贪吃蛇」提升了与2D坐标相关的数学问题表现。
而「旋转」是一个识别3D物体旋转角度的问题,可以在角度和长度相关的数学问题上令模型表现更好。
如图2所示,模型经过思考选择一个动作,输出其思维链和决策。例如,最佳/最差移动或预测角度,并获得奖励。
通过游戏,模型获得推理能力,并将其迁移到下游多模态推理任务中,如数学和多学科问答。

更加令人振奋的是,同时训练这两个游戏比单独训练任一游戏的表现更优。
这意味着游戏训练具有可扩展性。
这可真是太棒了!对于模型来说,简直就是玩的越多,学的越多。
这些实验结果都表明,除了收集特定领域的数据,还可以设计可扩展、可控的前置游戏(pre-text games),来激发模型产生能泛化到下游任务的推理能力。(图3)
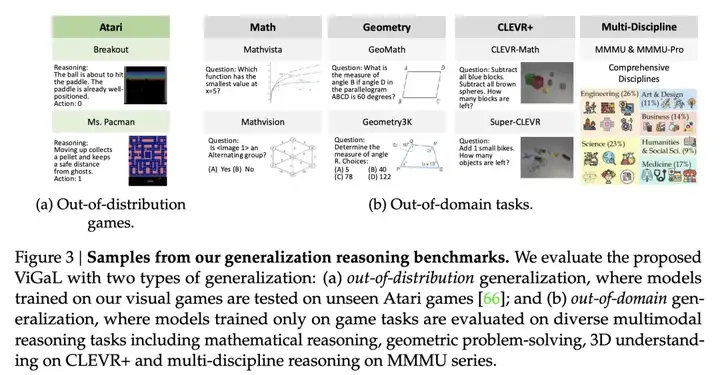
使用两种类型的泛化来评估所提出的ViGaL:(a) 分布外泛化,即在我们的视觉游戏上训练的模型在未见的Atari游戏上进行测试;以及(b) 领域外泛化,即仅在游戏任务上训练的模型在多种多模态推理任务上进行评估,包括数学推理、几何问题解决、CLEVR+上的3D理解以及MMMU系列上的多学科推理
合成游戏环境可以提供结构化、基于规则的奖励信号,具有高度的可控性,这使得通过难度规划(difficulty scheduling)来实现稳定的RL成为可能。
值得一提的是,这些合成环境中进行数据扩展,要比收集人工标注的数据容易得多。
总之,这些发现揭示了一个极具前景的新范式——使用游戏这类合成任务进行后训练。
这让人联想到了自监督学习在计算机视觉和自然语言处理领域的崛起:在精心设计的合成前置任务上进行预训练,最终都带来了强大的泛化能力。
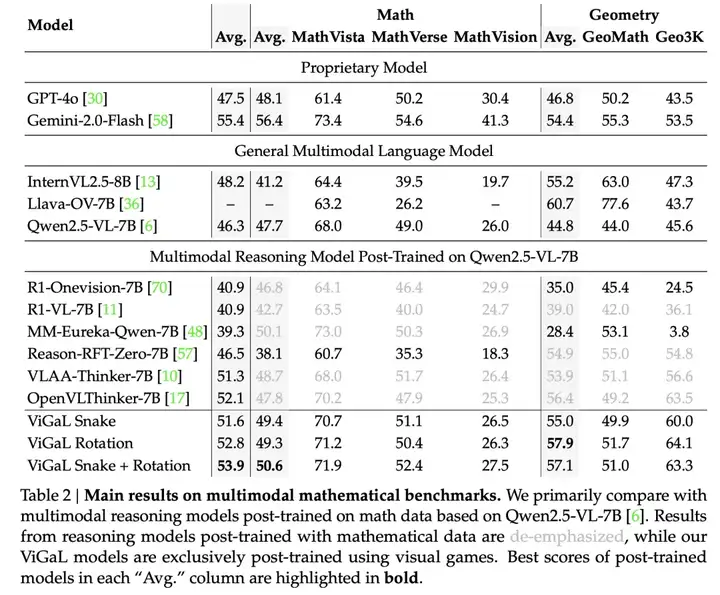
如表2所示,本文的方法在数学任务上的表现显著优于专门针对数学任务进行RL训练的模型。
例如,ViGaL Snake + Rotation在数学任务上的准确率比MM-Eureka-Qwen-7B高出0.5%,在几何任务上高出28.7%!
尽管MM-Eureka-Qwen-7B使用了高质量的数学和几何数据集进行明确训练。
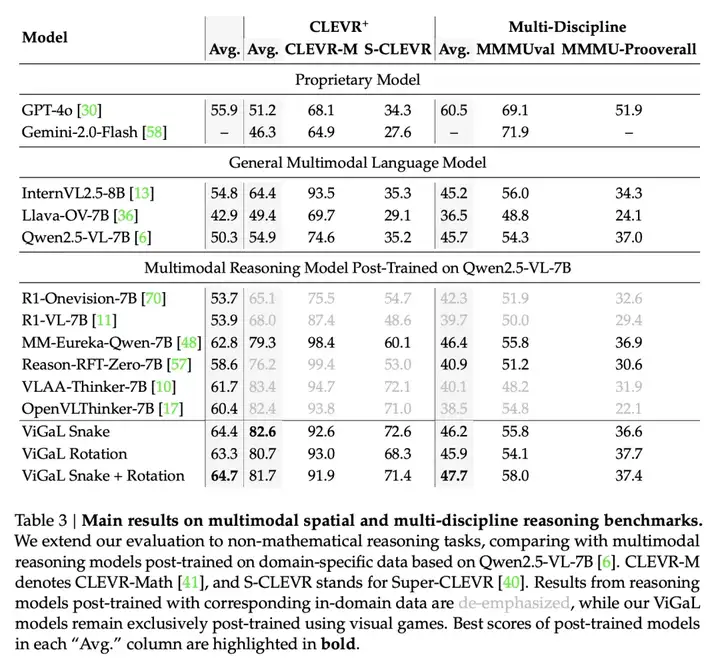
这种强大的泛化能力不仅限于数学领域。
表3显示,ViGaL Snake + Rotation在MMMU系列基准测试中的平均表现比R1-OneVision-7B高出5.4%,这些基准测试评估了多学科推理能力。
这一结果尤为引人注目,因为R1-OneVision-7B模型使用了涵盖多个学科的精心策划的综合数据集进行训练。
混合多种游戏可增强泛化能力。
如上表2所示,在Snake游戏上进行后训练在CLEVR+基准测试中取得最佳性能,而在Rotation游戏上训练则在几何推理任务中表现出更强的结果。
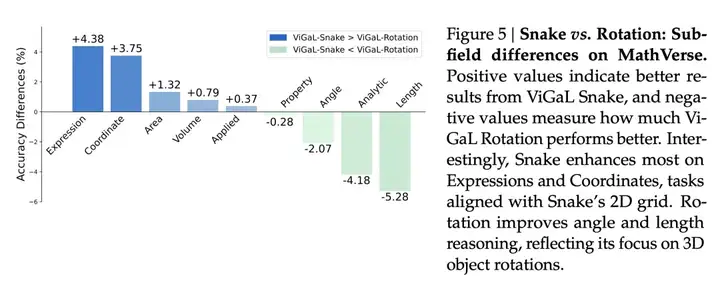
它们的比较优势在图5中进一步说明。
有意思的是,Snake模型在表达式和坐标方面提升最为明显,这些任务与蛇模型的二维网格相关。旋转模型在角度和长度推理方面有所改进,这反映了它对三维物体旋转的关注。
正值表示ViGaL Snake模型取得更好的结果,负值表示ViGaL旋转模型表现优于Snake模型的程度
同时在 Snake 和 Rotation 游戏上训练模型,使其能够从两种环境中学习互补技能,从而将整体基准测试平均成绩提高到63.1%。
这些发现表明,结合多样化的游戏环境可以显著提升性能。
这展示了视觉游戏学习(ViGaL)作为一种有前景的训练范式,能够增强可泛化的推理能力,而无需大规模的领域特定数据。
在增强推理能力的同时保持通用视觉能力。
为了全面检验推理任务上的泛化是否会导致通用视觉能力的下降,研究者在更广泛的MLLM基准测试集上评估了ViGaL Snake + Rotation。
如表4所示,与RL调优前的Qwen2.5-VL-7B相比,模型在保持相当的通用视觉性能的同时,取得了更强的数学推理结果。
相比之下,其他通过RL后训练提升数学性能的模型通常在通用视觉能力上表现出显著下降。
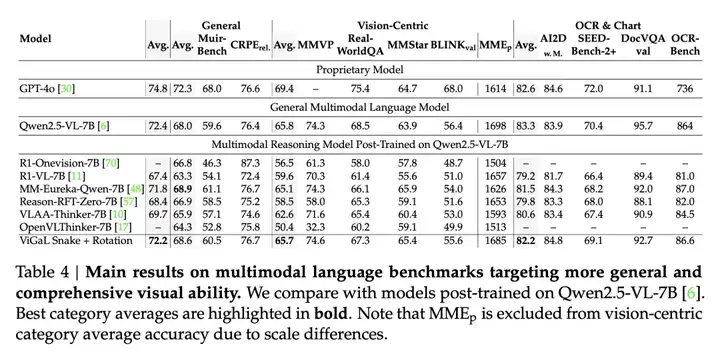
这些结果表明,本文的游戏后训练方法能够在增强推理能力的同时,有效保持通用视觉能力。
参考资料:
https://www.arxiv.org/abs/2506.08011
文章来自于“新智元”,作者“犀牛”。



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
