# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
LLM Ensemble(大语言模型集成)在近年来快速地获得了广泛关注。它指的是在下游任务推理阶段,综合考虑并利用多个大语言模型(每个模型都旨在处理用户查询),从而发挥它们各自的优势。大语言模型的广泛可得性,以及其开箱即用的特性和各个模型所具备的不同优势,极大地推动了 LLM Ensemble 领域的发展。本文系统性地回顾了 LLM Ensemble 领域的最新进展。首先,我们介绍了 LLM Ensemble 的分类法,并讨论了几个相关的研究问题。然后,我们把"推理前集成、推理中集成、推理后集成"这三大范式下的各种方法划分为七大类,并回顾了所有相关方法。最后,我们介绍了相关的基准测试集和典型应用,总结和分析了现有的研究成果,并提出了若干值得关注的未来研究方向。
本文已被 ArXiv 收录。

论文题目:
Harnessing Multiple Large Language Models: A Survey on LLM Ensemble
论文链接:
https://arxiv.org/abs/2502.18036
GitHub 仓库:
https://github.com/junchenzhi/Awesome-LLM-Ensemble
近年来,人工智能领域的格局因大型语言模型(LLM)的飞速发展而发生了深刻变化,代表性的模型包括 Gemini、GPT-4、Llama,以及最近推出的 DeepSeek。这些 LLM 的成功持续激发着广泛的研究热情。
目前,在 Hugging Face 平台上,可以访问的大语言模型数量已经超过了 182,000 个。然而,在这股研究热潮背后,我们可以观察到两个主要方面:
考虑到上述两个方面,并借鉴集成学习的精神,我们自然地可以考虑一种解决问题的思路:对于每一个任务查询,与其持续依赖某个"基于公共排行榜或其他指标挑选出的"单一固定 LLM,不如同时考虑多个可以开箱即用的 LLM 候选模型,以充分发挥它们的各自优势。实际上,这正是近年来新兴的 LLM Ensemble 领域所探索的内容。
现有的 LLM Ensemble 方法可以根据"LLM 推理"和"集成"的先后顺序而分为三大范式:
尽管基于上述三大范式,近年来衍生出了大量方法,但目前仍缺乏一篇正式的综述文章以对快速发展的 LLM Ensemble 领域中的研究方向进行系统梳理和深入分析。
本文系统性地回顾了 LLM Ensemble 领域的最新进展,分别讨论了分类法、相关问题、方法、基准、应用和未来方向。我们希望这篇综述能够为研究人员提供全面的回顾,并激发进一步的探索。
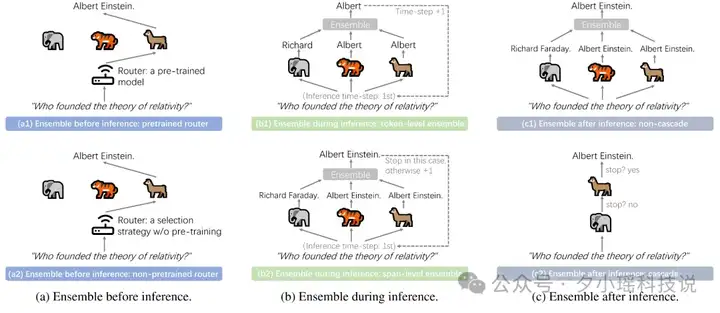
(图 1: 各类 LLM Ensemble 方法的示意图。请注意:对于(b) Ensemble-during-inference,还存在(b,3)process-level ensemble 方法。我们并没有在此图中画出这类方法,因为考虑到排版问题以及目前这类方法只存在一个实例化的方法。)
本节将正式介绍 LLM Ensemble 分类体系,对应的示意图和各类方法下的研究工作见图 1 和图 2。
如上文所述,当前的 LLM Ensemble 方法可以分为以下 3 大类范式(关于对此三大范式的划分,我们采用了文献[2]的划分方法)与 7 大类方法:
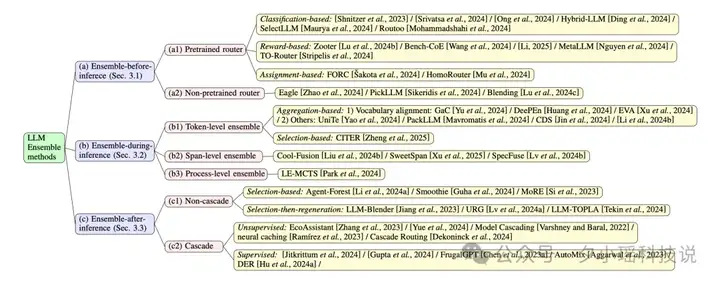
(图 2: 各类 LLM Ensemble 方法下的研究工作)
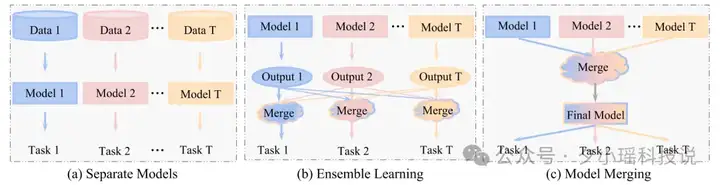
(图 3: Ensemble Learning 与 Model Merging 的示意图。图片来自文献[1];请注意,子图 b 中对应了 LLM Ensemble 中的一类典型方法,即"推理后集成方法"中的"(c1)非级联方法"。)
如图 3 所示,大语言模型融合(LLM Merging,LLM Fusion)[1]指的是在无需原始训练数据的前提下,将多个大语言模型的参数进行融合,从而构建一个统一的模型。
这种方法与 LLM Ensemble 密切相关,因为它们都强调知识的融合与迁移。
大语言模型协作(LLM Collaboration)[2][3]则是通过利用每个模型的不同优势,以更加灵活的方式完成任务。与 LLM Ensemble 不同,LLM Collaboration 方法并不将所有模型平等地直接用于用户查询,而是为每个模型分配不同的角色,并通过交换不同模型所生成的响应信息来提升效果。
弱监督学习(Weak Supervision)[4][5],又被称为众包学习与群智监督学习(Learning from Crowds)[6],主要利用"来自多弱标注源所提供的弱标签信息"来实施关于真值标签的真值推理与后续的基于推理后标签的学习(这对应于 LLM Ensemble 中的"(c1)非级联方法"),或者直接用弱标签信息来进行端对端学习以获得分类器。然而,目前关于此类方法的研究主要集中在分类任务上,而不是通用的生成任务。
此部分可详见论文。我们在论文中对 7 类 LLM Ensemble 方法(即图 1 和图 2 中所示的 a1、a2、b1、b2、b3、c1、c2)对应的各个研究工作进行了深入分析,并在其中尽可能地对方法进行进一步的细化分类。
比如,对于"(c) 推理后集成(Ensemble after inference)方法",我们又根据方法是否需要在下游任务中的监督学习而进行进一步的分类和分析(如图 4 所示)。
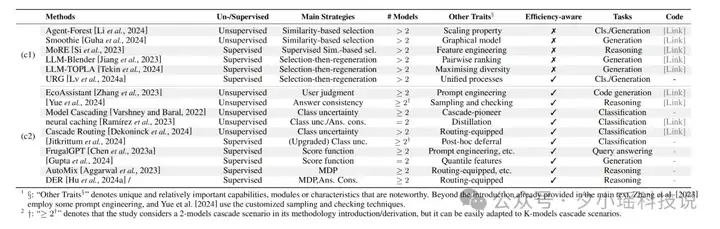
(图 4: 对推理后集成(Ensemble after inference)方法中的各个研究工作的归纳性总结)
我们在论文中对 7 类 LLM Ensemble 方法进行了总结性分析。如图 5 所示,分析主要从三个核心维度展开:集成策略、集成粒度和集成目标。
从集成策略的角度来看,聚合式(Aggregation)方法(如对所有模型输出进行平均或加权融合)相较于挑选式(Selection)方法(即从多个输出中选出一个,类似于硬投票)要更为复杂。另外,再生成式(Regeneration)方法通常需要额外准备大量特定的训练数据并再次微调一个大模型,因而成本更高。
从集成粒度的角度来看,响应级(Response-level)集成方法属于粗粒度集成。而细粒度的集成方法(包括 Token-level 和 Span-level 的集成方法),特别是 token 级集成方法,在模型解码阶段可以更精细地利用各个模型的输出概率分布,从而增强集成效果。
最后,从集成目标的角度来看,"(b)推理时集成方法"和"(c1)非级联式推理后集成方法"因不受推理成本限制,通常能够采用更加灵活的集成策略(即可以不依赖于基于挑选式的集成策略),并引入更细粒度的融合方式,最终具有更强的性能提升潜力。
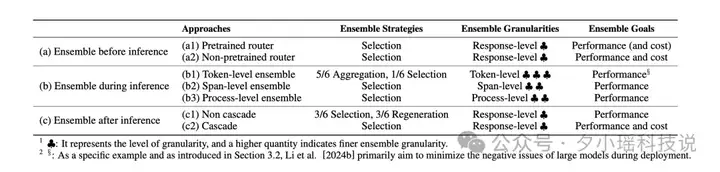
(图 5: 对 7 大类 LLM Ensemble 方法的总结性分析)
LLM Ensemble(大语言模型集成)是集成学习在大语言模型时代的直接体现。大语言模型的易获取性、开箱即用的特性与多样性,使得集成学习的思想在当前的 LLM Ensemble 研究领域中更具有活力。本综述论文对 LLM Ensemble 领域中的 7 大类方法进行了全面的梳理与总结。我们希望这篇综述能为相关研究人员提供有价值的参考,并激发更多在 LLM Ensemble 及其相关领域的深入探索。
最后,我们致谢下面的参考文献以及在我们的综述论文中所涉及的各个研究工作。
[1] Enneng Yang, et al. Model Merging in LLMs, MLLMs, and Beyond: Methods, Theories, Applications and Opportunities. ArXiv 2024.
[2] Jinliang Lu, et al. Merge, ensemble, and cooperate! a survey on collaborative strategies in the era of large language models. arXiv 2024.
[3] Yilun Du, et al. Improving factuality and reasoning in language models through multiagent debate. ICML 2024.
[4] Jieyu Zhang, et al. Wrench: A comprehensive benchmark for weak supervision. NeuIPS 2021.
[5] Zhijun Chen, et al. Neural-Hidden-CRF: A Robust Weakly-Supervised Sequence Labeler. KDD 2023.
[6] Pengpeng Chen, et al. Adversarial learning from crowds. AAAI 2022.
文章来自于“夕小瑶科技说”,作者“陈志珺,李京政等”。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
