# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着 AI4Science 的浪潮席卷科研各领域,如何将强大的人工智能模型真正用于分析科学数据、构建数学模型、发现科学规律,正成为该领域亟待突破的关键问题。
近日,中国科学院自动化研究所的研究人员提出了一种创新性框架 ——DrSR (Dual Reasoning Symbolic Regression):通过数据分析与经验归纳 “双轮驱动”,赋予大模型像科学家一样 “分析数据、反思成败、优化模型” 的能力。
在 DrSR 中,三位 “虚拟科学家” 协同工作:
这三种角色基于大模型构建起高效的协作机制,共同驱动 DrSR 实现智能化、系统化的科学方程发现。
在物理、生物、化学、材料等跨学科领域的典型建模任务中(如非线性振荡系统建模、微生物生长速率建模、化学反应动力学建模、材料应力 - 应变关系建模等),DrSR 展现出强大的泛化能力,刷新当前最优性能,成为 AI 助力科学研究的有力工具。

在科学发现和工程建模中,寻找数据背后的数学模型一直是一项核心任务。这正是符号回归(Symbolic Regression, SR)的目标 —— 从观测数据出发,自动生成解释性强、结构清晰的数学方程。
这种 “从数据中还原规律” 的能力,已在物理、化学、生物、材料等多个学科中发挥了巨大作用,成为人类理解复杂系统的重要工具。
随着大模型的兴起,符号回归正迈入一个 “类人推理” 的新阶段。例如,LLM-SR 等方法开始尝试用大模型直接生成公式骨架(skeleton),再配合优化器拟合参数,实现 “从提示词到方程” 的自动生成。这让符号回归从传统的遗传进化算法中解放出来,性能和表达能力双双提升。
但问题也随之而来,这些方法虽然 “公式写得快”,却往往 “不看数据”,更 “不记经验”。
模型生成公式靠的是大模型内嵌的科学知识,而非对当前实验数据的深入理解。
一旦某个公式生成失败,模型通常无法从失败中改进策略,只会机械地重复尝试,陷入 “盲猜” 或 “重走老路” 的困境。
结果就是:不是过拟合 “已有套路”,就是反复生成无效表达式,计算资源浪费严重,智能化程度受限。
为了解决这一难题,研究团队提出了全新框架 DrSR:让模型 “会看题”“会复盘”“会改进”—— 像科学家一样,从数据中洞察结构、从失败中总结经验、在生成中持续进化。
DrSR 的核心理念是 “双路径推理”(Dual Reasoning):通过引入 “数据洞察” 与 “经验总结” 两条信息流,为大模型提供结构引导与策略反馈,让其像科学家一样高效、稳健地进行探索。
DrSR 的两大关键机制包括:
DrSR 的流程并不复杂,关键在于:让 LLM 在每一轮尝试中都 “看数据、学经验、再出手”,具体流程如图 1 所示。
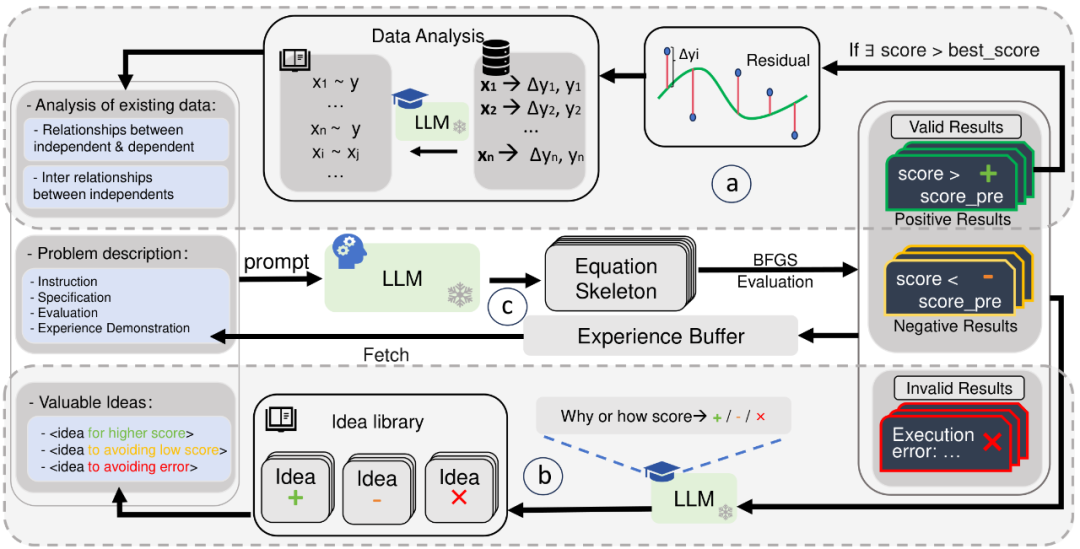
图 1:DrSR 的双路径推理机制,让 LLM 在分析、生成、复盘三个环节协同工作,模拟科学家的研究思维
模块 a:从数据中提炼结构线索
模块 b:从历史结果中总结成功经验
方程一旦生成,DrSR 不仅会进行拟合与打分,还会将结果分类为「效果更好」「效果变差」「无法执行」三类,并交由一个 “经验型 LLM” 进行分析,总结出可以重复利用的经验知识。
该模块会进行如下反思:
总结出的知识以 idea 的形式存入 idea 库(Idea Library),供后续轮次调用,提升生成策略的有效性。
模块 c:方程生成 + 数值拟合
DrSR 的 “主控型 LLM” 负责综合问题描述、数据分析结论和 idea 库的经验,生成方程 skeleton。随后调用 BFGS 等优化器进行系数拟合,并评估方程的整体误差。表达式被送回评估路径,进入下一轮经验提炼与数据再分析循环。
这个模块是整个 DrSR 的 “前台”,而 a 与 b 是强大的 “后端支持”。
总结来说,DrSR 的运行流程是一种闭环:
数据分析 → 提示引导 → 方程生成 → 评估打分 → 经验总结,如此循环。每一次生成,模型都在积累知识、修正路径,从 “盲目试探” 走向 “有的放矢”。
研究团队在六大符号回归基准任务上系统评估了 DrSR 的性能,涵盖物理、生物、化学、材料等多个科学领域,结果显示 DrSR 全面超越现有主流方法,不仅准确率更高,而且在推理效率和泛化能力上也显著领先。
全面领先的拟合精度与准确率
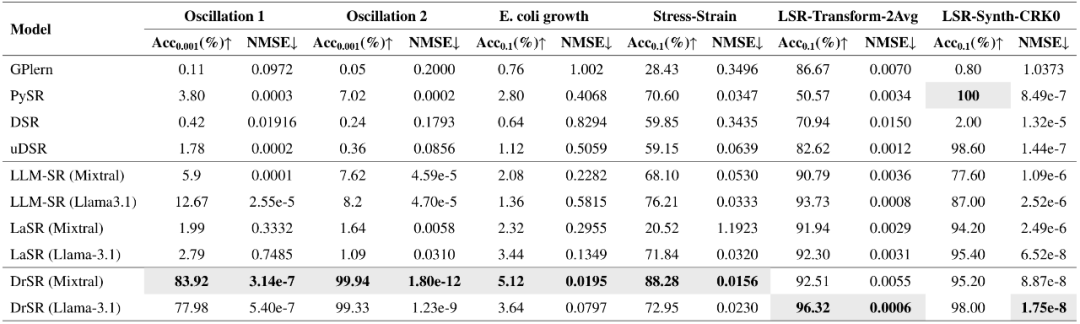
表 1. DrSR 和基线方法在六个符号回归基准上的总体性能
如表 1 所示,平均来看,DrSR 在 6 个任务中有 5 个取得了最高准确率(Acc)和最低归一化均方误差(NMSE)。特别地,DrSR 在非线性阻尼振荡系统建模任务(Oscillation 2)上达成了近乎完美的 99.94% 准确率,误差低至 1.8e-12,显著优于所有基线方法。
快速收敛:从一开始就更聪明
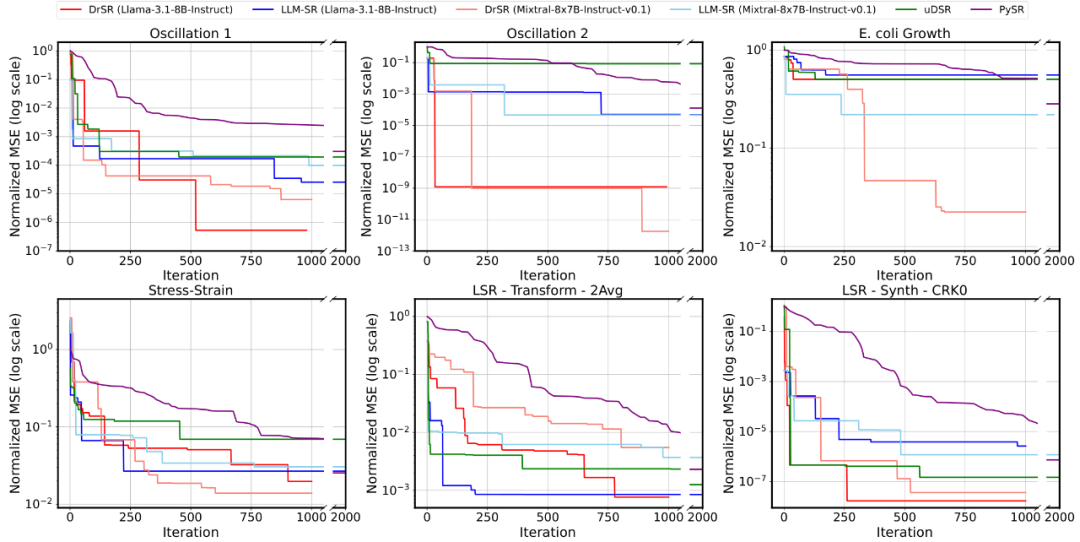
图 2. 训练收敛性比较
从图 2 可以看到,DrSR 在几乎所有数据集上都以更快速度达到更低的误差。在初期迭代阶段,其误差下降趋势也更稳定,不容易陷入振荡或卡顿,这说明 DrSR 的双推理策略能更有效引导方程生成方向,从而减少无效尝试次数。
有效率更高:生成的方程更 “靠谱”
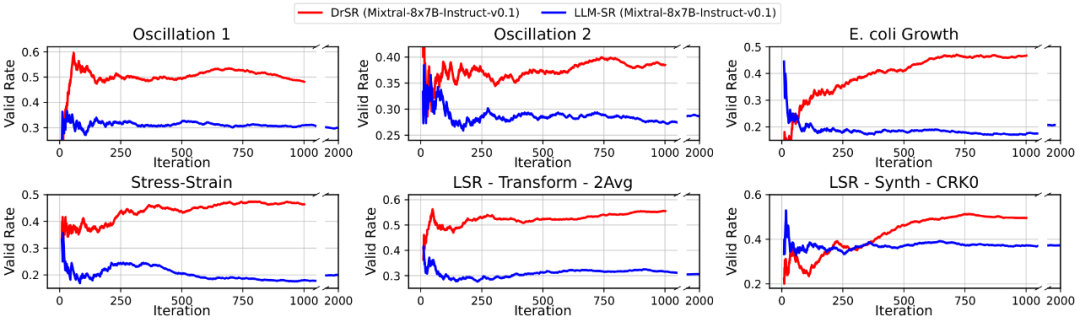
图 3. 有效解比例对比
如图 3 所示,DrSR 生成的方程在语法、编译、可求值等方面的有效比例普遍高于 LLM-SR 约 10%-20%,这背后正是 “经验学习” 机制的作用 —— 模型逐步避开常见失败结构。
泛化更强,且对噪声和 OOD 更鲁棒
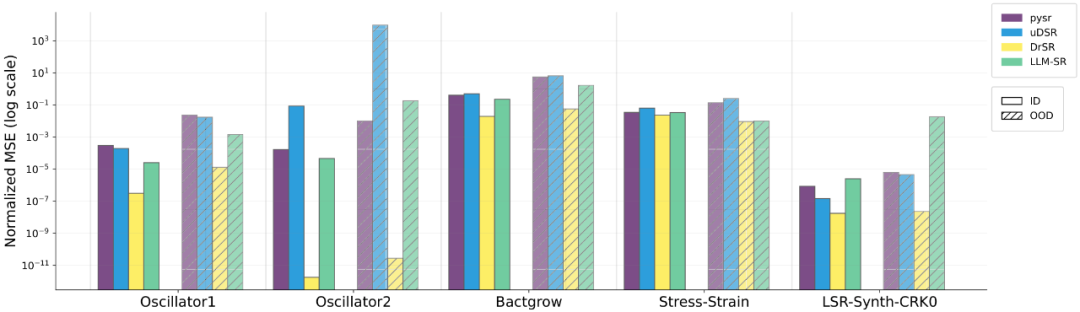
图 4. 在 ID 和 OOD 数据下跨科学领域的泛化对比
图 4 展示了 DrSR 在 ID(域内)与 OOD(域外)数据下的性能对比。可以看到:在所有任务、所有设置下,DrSR 的归一化均方误差(NMSE)始终是最低的,展现出极强的模型稳定性。其他方法(如 PySR 或 uDSR)虽然在部分任务中 ID 表现尚可,但面对 OOD 分布时误差陡升、性能骤降,而 DrSR 则表现出了 “跨场景保持鲁棒” 的能力。

表 2. 不同高斯噪声水平下的性能比较
如表 2 所示,在不同高斯噪声水平下,DrSR 均显著优于 LLM-SR,展现出抗噪、抗漂移的泛化优势。
消融实验:两个核心机制 “缺一不可”
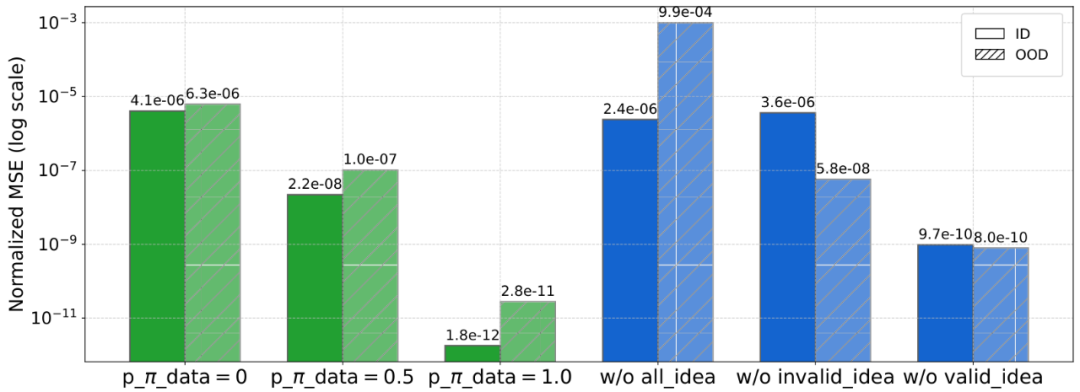
图 5. 消融实验
图 5 的消融实验也验证了两个核心机制的重要性:没有结构引导,模型不知从何生成;没有经验总结,模型容易反复试错。DrSR 的成功,正是这两者闭环协同的结果。
为了更直观地展示 DrSR 的 “类科学家” 建模过程,研究团队以非线性阻尼振荡系统建模任务为例,绘制了其在 1000 次迭代过程中的方程演化轨迹,如图 6 所示。
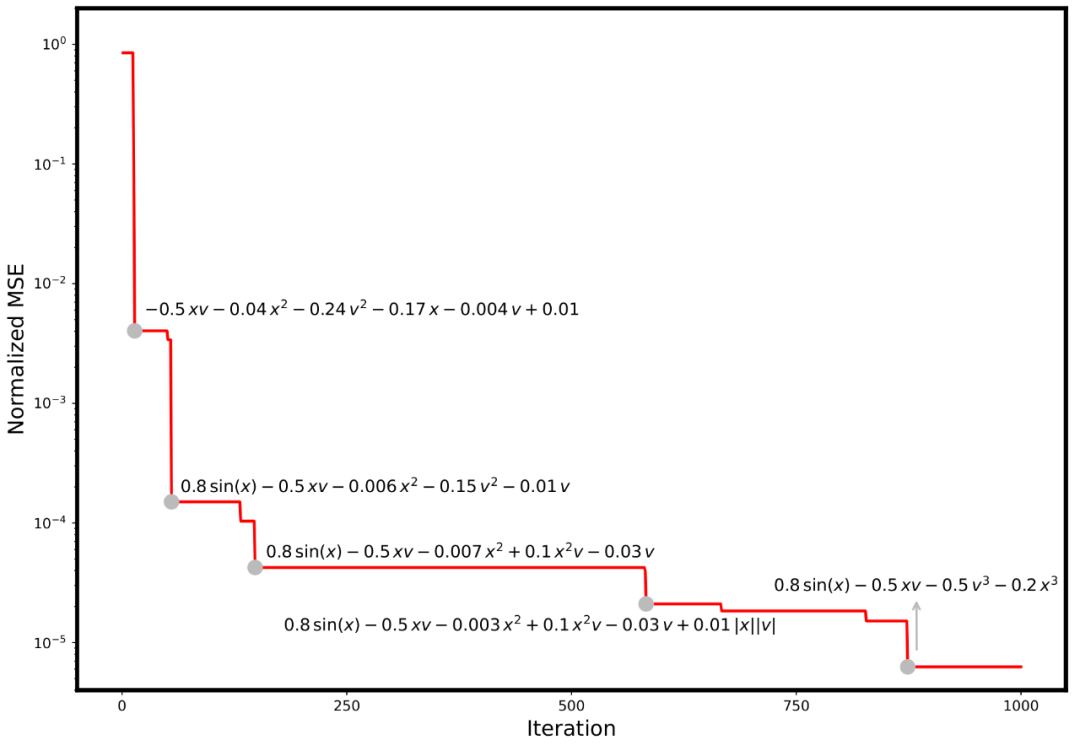
图 6. DrSR 的性能轨迹与代表性表达式演化,每一个台阶,都是模型一次深刻的 “认知飞跃”
该任务的真实方程为:
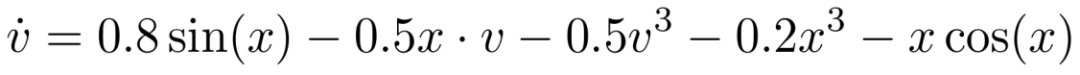
DrSR 在仅 1000 轮迭代后生成的最优方程为:
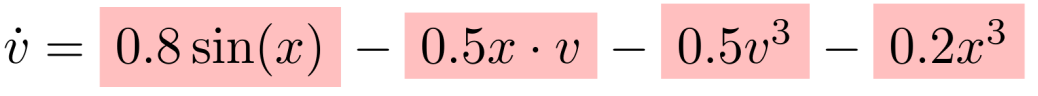
基线 LLM-SR 在 2000 轮迭代后生成的最优方程为:
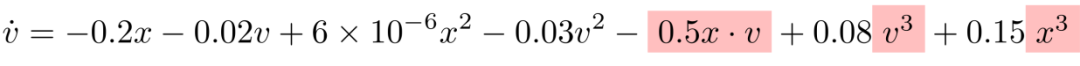
可以看到:DrSR 用一半的迭代次数,就生成了更接近真实结构的表达式,充分体现其 “有方向感” 的探索能力。
这一案例也展现出 DrSR 独特的三大智能行为:
在前几十轮中,DrSR 尝试了一系列初步构造的方程,例如仅包含多项式组合的表达式(如 -0.5xv - 0.04x² - 0.24v² 等),尽管形式接近,但精度仍远未达到理想值。此阶段模型更像一个 “实验科学家”,快速试错、积累经验。
随着经验的积累与数据结构的洞察引入,DrSR 开始生成带有 sin (x)、x²v 等非线性物理元素的表达式,方程拟合误差明显下降近两个数量级,说明模型已开始理解系统的振荡性本质。此时,它如同一个 “理论科学家”,开始用正确的符号结构组织规律。
最终,DrSR 提出了形如 0.8sin (x) - 0.5xv - 0.5v³ - 0.2x³ 的复杂但精确表达式,误差降至 10^-5 级别,接近人类解析解。这一过程高度模拟了科学发现中的 “假设 - 验证 - 归纳” 的迭代式建模模式。
这个案例生动说明了 DrSR 如何结合 “结构洞察 + 经验引导” 两种智慧,逐步收敛到准确又可解释的科学方程。
DrSR 提出了一种融合数据感知与经验反思的符号回归新范式,它通过结构洞察指导生成方向,通过经验总结提升推理质量,让大模型在科学建模中逐步具备 “看数据、记教训、会修正” 的能力。
在多个跨学科的符号回归任务中,DrSR 实现了对传统方法与现有 LLM 基线的全方位超越,在准确率、收敛速度、方程有效性和泛化能力等维度表现突出。作为一套通用性强、可解释性好、建模效率高的新架构,DrSR 为人工智能深度参与科学发现提供了坚实技术支撑。
DrSR 已集成至一站式智能科研平台 ScienceOne,为科研工作者提供高效、可解释的科学建模服务。值得强调的是,DrSR 并不依赖特定的大模型,具备良好的模型兼容性和可扩展性。未来,研究团队将基于平台自研的科学基础大模型 S1-Base,进一步增强 DrSR 在科学建模中的推理能力与跨任务泛化能力。
尽管 DrSR 展现出优异的建模性能与类科学家的推理能力,但仍存在若干值得改进的方面:
这些问题正是未来演进的关键方向。研究团队计划继续扩展 DrSR 至多模态科学建模场景,引入持续学习机制,提升策略泛化能力,逐步构建一个具备长期认知积累、适应科学复杂性的智能建模引擎。
让人工智能不仅能 “拟合数据”,更能 “发掘自然规律”,这正是 AI4Science 走向深层科学智能的必由之路。
文章来自于微信公众号“机器之心”。



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
