# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
谷歌遗珠与IBM预言:一文点醒Karpathy,扩散模型或成LLM下一步。
Karpathy难以抵挡的诱惑!
苹果的前员工、德克萨斯大学奥斯汀分校(UT Austin)的计算机科学研究生Nathan Barry,得出一个惊人的结论:
BERT本质上,只是文本扩散中的一步!
基于「强化版BERT」RoBERTa,他成功地把表示学习算法改造为生成算法:

看完帖子后,OpenAI创始员工、特斯拉前AI总监Karpathy陷入了沉思:
人类的思维或许更偏向自回归一些——一步步推进的感觉。但在我们的思维潜空间里,也很难说就不存在某种更像扩散的机制。
说不定在这两者之间,其实可以继续插值、或者更进一步泛化。
这部分生成逻辑在LLM架构中,依然是一个相对「可变」的部分。
不过,Karpathy最近忙于为Eureka Labs的《LLM 101n》课程开发终级实践项目「100美元带回家的ChatGPT」,所以他只能「忍痛割爱」:
现在我必须克制住用扩散模型训练nanochat的冲动,不能偏离主线去搞支线任务了。
顺便提一句,当天不久,他又被DeepSeek-OCR挑起了新念头。
当第一次读到语言扩散模型论文时,Nathan Barry惊讶地发现它们的训练目标只是掩码语言建模(masked language model,MLM)的一种推广。

而自从2018年BERT以来,大家一直早已对掩码语言建模习以为常。

预印本:https://arxiv.org/abs/1810.04805
他脑海里立刻冒出一个想法:我们能不能把类似BERT的模型微调一下,让它也能做文本生成?
出于好奇,他做了个快速的验证实验。随后,他发现其实早就有人做过了——DiffusionBERT基本就是这个想法,不过做得更严谨。
值得一提的是,大约3年前,DiffusionBERT由国内高校的研究者提出,100%国产!

预印本链接:https://arxiv.org/abs/2211.15029
最初,扩散模型在图像生成领域一炮而红。
在图像生成中,扩散模型会先对图像逐步添加高斯噪声(前向过程),然后训练神经网络对其进行迭代去噪(反向过程)。
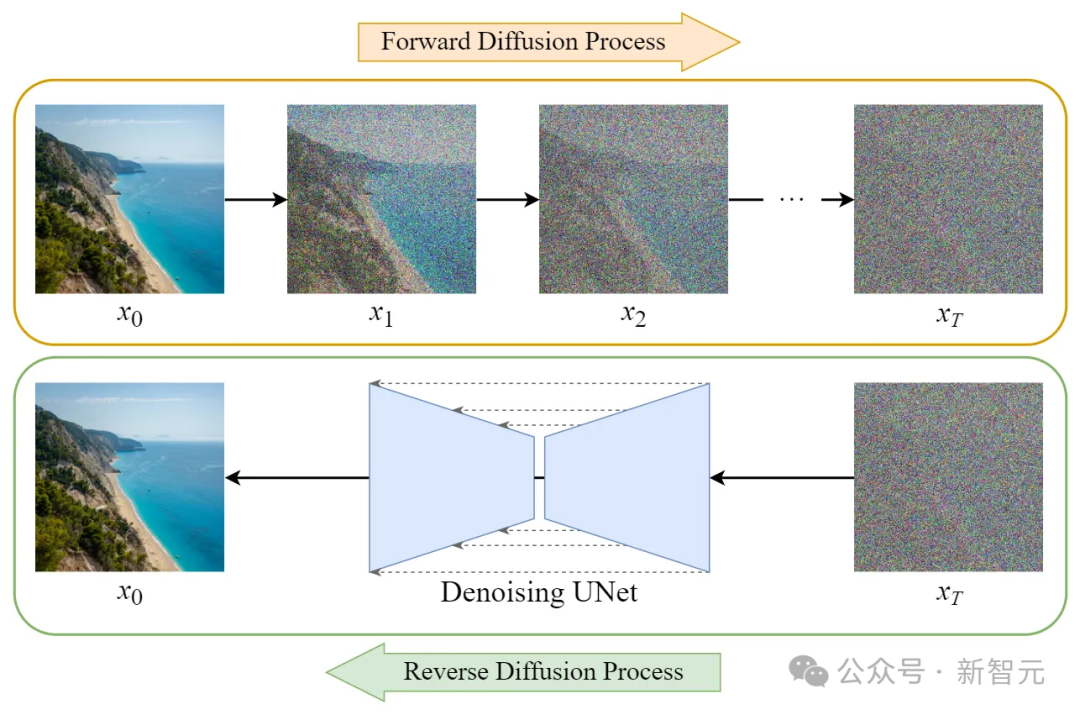
将这一思路应用于文本领域,意味着我们需要找到方法对文本添加噪声并在之后分阶段消除。
最简单的实现方式是基于掩码的噪声处理流程:
为了解决以往方法存在的问题,BERT提出了掩码语言建模(Masked LM)。
具体做法是:对每条训练输入序列随机遮盖15%的词语,仅对这些被遮盖的词进行预测。用图示语言来表达就是:
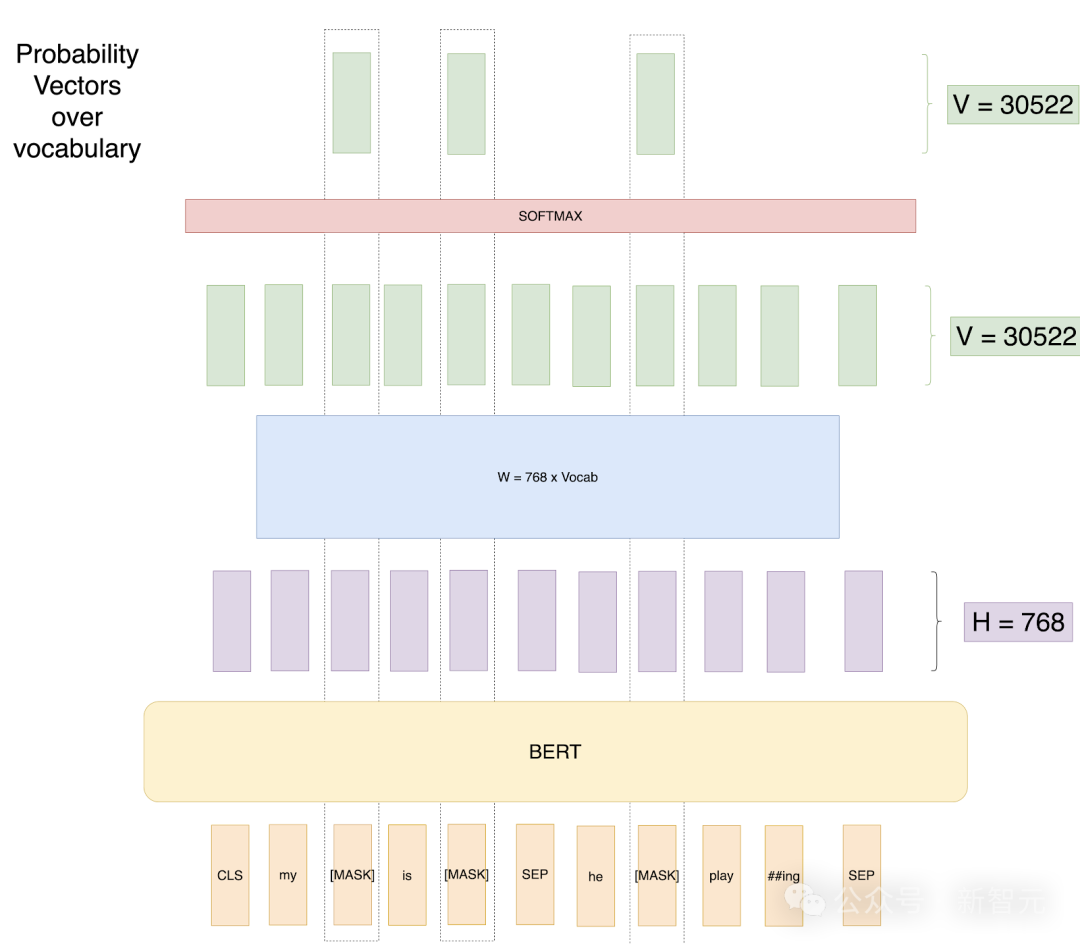
换句话说,BERT的MLM训练目标,其实就可以看作是文本扩散的一种特例,只不过它用的是固定的掩码率。
而只要我们引入一个从0到1的动态掩码率范围,就可以把BERT的训练目标自然扩展为一个完整的文本生成过程。
2019年发布的RoBERTa模型,是在原始BERT基础上的一次强化升级。

预印本:https://arxiv.org/abs/1907.11692
它调整了超参数、扩大了训练语料,并简化了训练目标——
只保留MLM(掩码语言建模),去掉了「下一句预测」任务。
而Nathan Barry使用HuggingFace的开源库,加载RoBERTa的预训练权重、分词器以及Trainer类,对模型进行微调,数据集选用 WikiText。核心代码(完整代码见原文)大致如下:
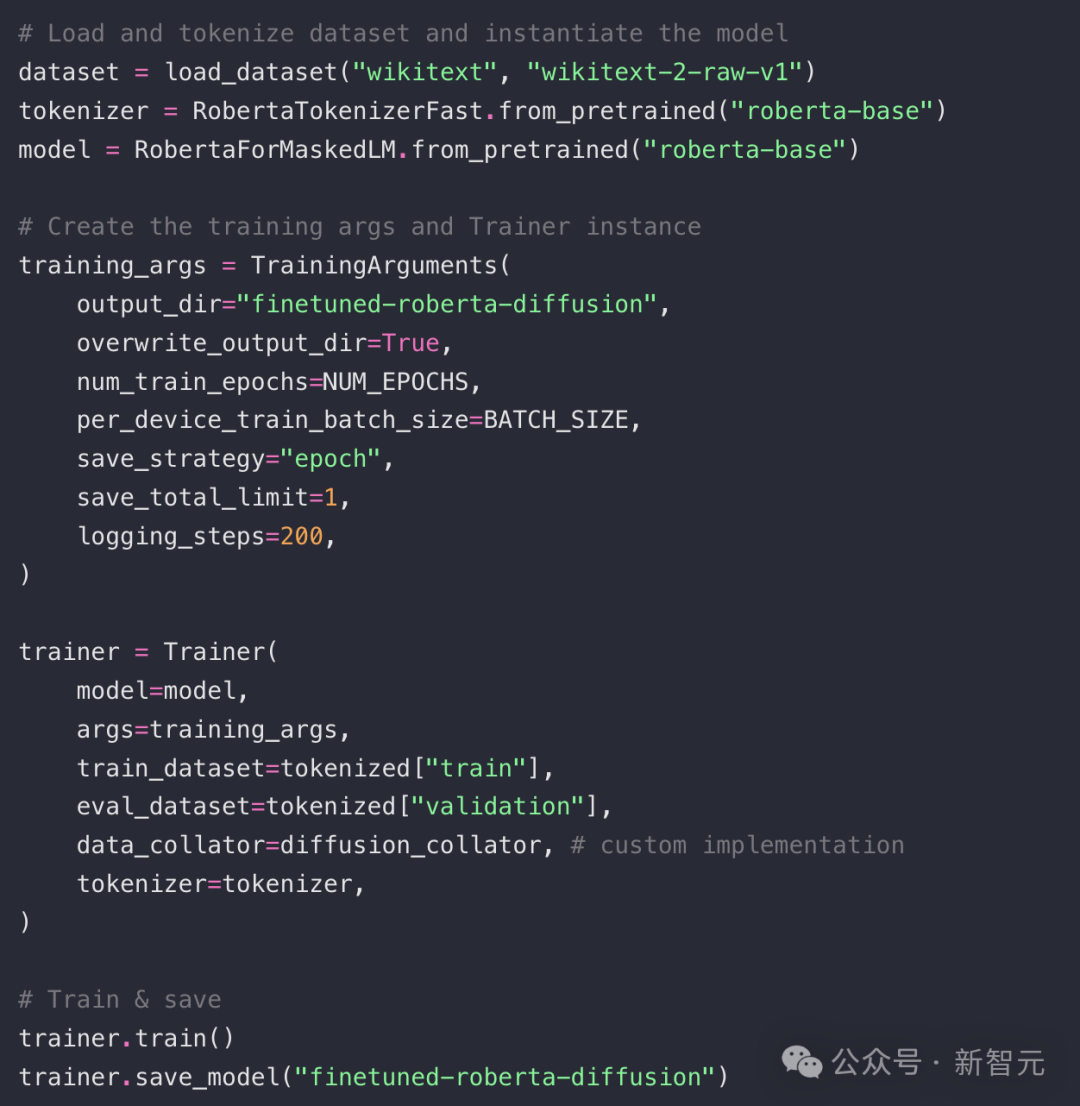
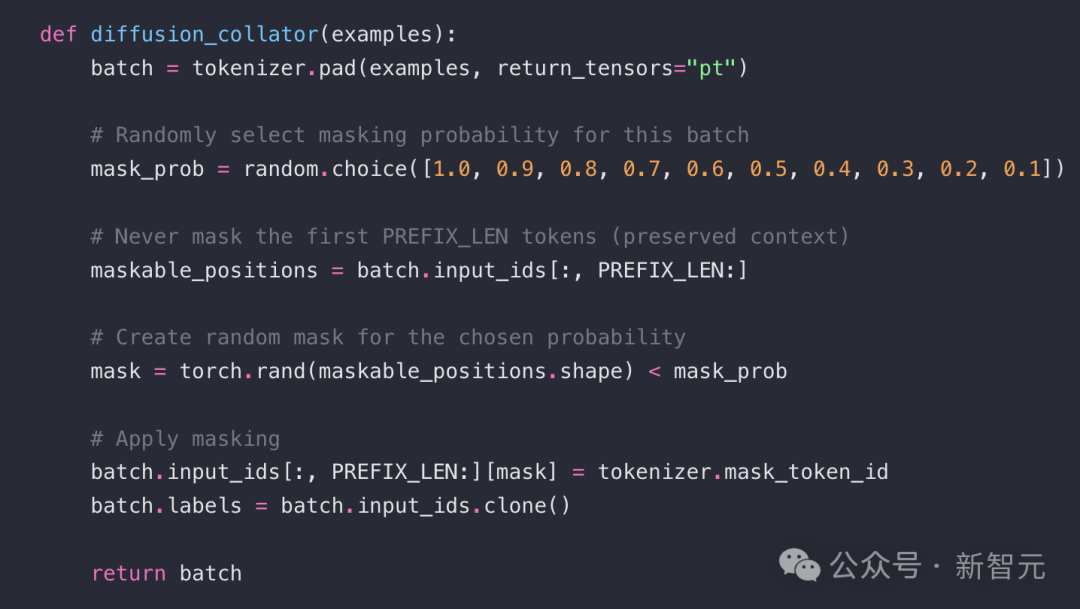
在当前实现中,设定了10个扩散步骤,每个训练批次随机采样一个遮盖比例p,从 [1.0, 0.9, ..., 0.1] 中选取,然后对该比例的Token进行掩码处理。这个逻辑封装在自定义的diffusion_collator 中:
在推理时,从一个长度为256的输入向量开始:前16个位置是提示词(prompt)的Token ID,后面240个全是 <MASK>。然后,逐步减少掩码比例,每一步都做预测、采样、重新掩码。流程如下:

对应的简化代码如下:
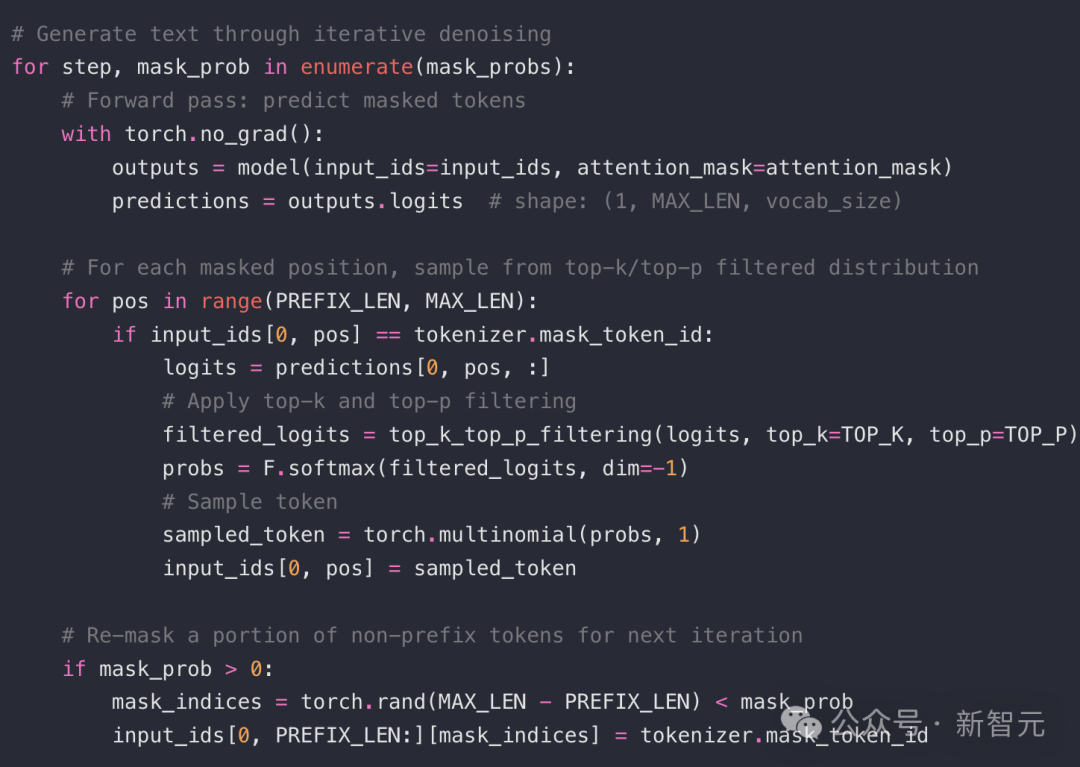
在H200显卡上,经过30分钟训练后,模型基于如下提示词生成了如下文本:
...dominion over Europe beginning about the early 19th. There conflict took place on the island, between British and Irish Ireland. British officials administered British Ireland, a Celtic empire under the control of the Irish nationalist authorities, defined as a dominion of Britain. As the newly Fortic states acquired independent and powerful status, many former English colonies played their part in this new, British @-@ controlled colonial system. Following this period the Non @-@ Parliamentaryist Party won its influence in Britain in 1890, led by the support of settlers from the Irish colonies. Looking inwards, Sinclair, Lewis questioned, and debated the need to describe " The New Britain "
提示词为:Following their victory in the French and Indian War, Britain began to assert greater...
生成的文本看起来出奇地连贯!其中大部分「怪异之处」, Nathan Barry归因于WikiText数据集本身的格式化问题——比如标点符号前后带空格,连字符「-」被处理成了@-@等。

数据显示,GPT-2在输出连贯性和生成速度方面略胜一筹(约9秒对比13秒)。
但RoBERTa Diffusion未经优化,如此效果,已令人惊喜。
这次的概念验证无疑非常成功——若能结合AR-Diffusion、跳跃步扩散等新兴技术并深度优化,生成质量与推理速度都将获得飞跃提升。
通过实验证明,以RoBERTa为代表的掩码语言模型(原本专为填空任务设计),将变比率掩码重构为离散扩散过程,完全可以转型为全功能生成引擎。
通过渐进式植入<MASK>标记污染文本,并训练模型在递增的掩码强度下迭代去噪,标准MLM目标成功地转化为渐进式文本生成流程。
值得注意的是,即使不调整模型架构,仅对训练目标进行微调后的RoBERTa就能生成视觉连贯的文本。
这有力印证了一个重要洞见:本质上,BERT系模型就是在固定掩码率上训练的文本扩散模型。
Karpathy点赞了Nathan Barry的短文:
帖子虽短,却解释了文本(离散)扩散模型可以有多简单。
……
许多扩散模型的论文看起来颇为晦涩,但若抛开数学形式的外壳,最终得到的往往是简洁的基础算法。
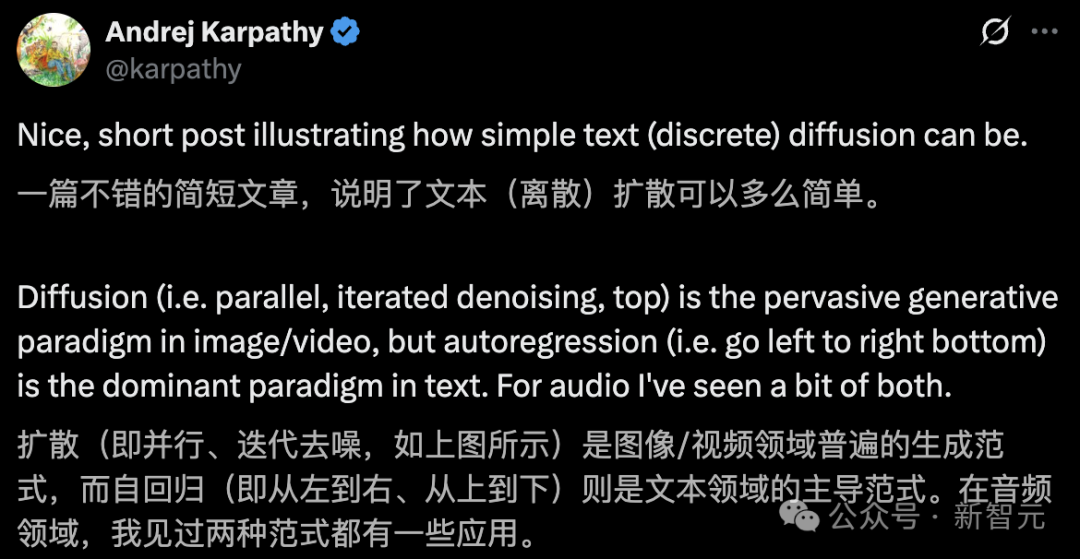
例如在连续空间中更接近流匹配的方法,或是像这样的离散空间方案,其本质还是经典的Transformer架构,只不过采用了双向注意力机制——
根据噪声调度计划,在「token画布」上迭代重采样和重复掩码处理所有token,直至最终步生成完整样本。
自回归生成的过程,就像是在Token画布上不断.append(token) ,每次只参考左侧已有的上下文;
而扩散式生成,则是在整个Token画布上反复.setitem(idx, token) ,每次都依赖双向注意力进行刷新更新。
从整个大语言模型(LLM)技术栈的角度来看,生成领域仍大有可为,存在着优化与创新的空间。
今年更早的时候,在2025 I/O大会上,谷歌DeepMind发布了一项实验性的扩展语言模型——Gemini Diffusion。

在速度上,扩散语言模型优势明显。以至于有网友预测:文本扩展模型就是每个人视而不见的下一步,因为训练成本太高了!

而「蓝色巨人」IBM的作家也断言,随着下一代AI浮现,扩散模型要挑战GPT。

参考资料:
https://nathan.rs/posts/roberta-diffusion/
https://x.com/karpathy/status/1980347971935068380
https://x.com/yacinelearning/status/1980351871413022901
文章来自于“新智元”,作者 “KingHZ”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
