# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文基于研究者的系统性综述,围绕“AI Scientist(AI科学家)”这一新的概念展开,核心线索是研究者的六阶段方法论与三阶段演进轨迹;您如果正搭建一个可验证、可协作、可扩展的研究自动化体系,这篇综述更像一张总路线图而非空洞口号,有不少思路可以借鉴。遗憾的是:截止研究者发文时间(10月31日),这篇综述并没有介绍微软最新的Kosmos(发布于11月),这是一个更系统的Scientist框架,每次运行平均执行 42,000 行代码并阅读 1,500 篇论文,AI Scientist领域的进展实在是太快了,远远超出人力所及的范围。但本综述引用的121篇代表性研究,系统覆盖了从 2022 到 2025 的主线工作(如 The AI Scientist v1/v2、DeepResearcher、Curie、AI-Researcher、Coscientist、BioPlanner 等),并结合相应基准(如 DS-1000、MLAgentBench、IdeaBench、WritingBench、SPOT、EXP-Bench)给出可落地的步骤与实例,论文:https://arxiv.org/pdf/2510.23045 项目主页:https://github.com/Mr-Tieguigui/Survey-for-AI-Scientist。 [1]

研究者提出一套统一的方法框架,将完整科研流程拆解为六个环节:文献综述、构思与假设、实验准备、实验执行、科学写作、论文生成,并据此梳理 2022–2025 年的系统与基准,您会发现分散的成果被纳入同一闭环。更关键的是,论文给出三阶段发展脉络——从“基础模块”到“闭环整合”,再到“可扩展、有效性与协作”的前沿,并点出双重趋势:一是更强的机器自治,二是更成熟的人机协作机制。
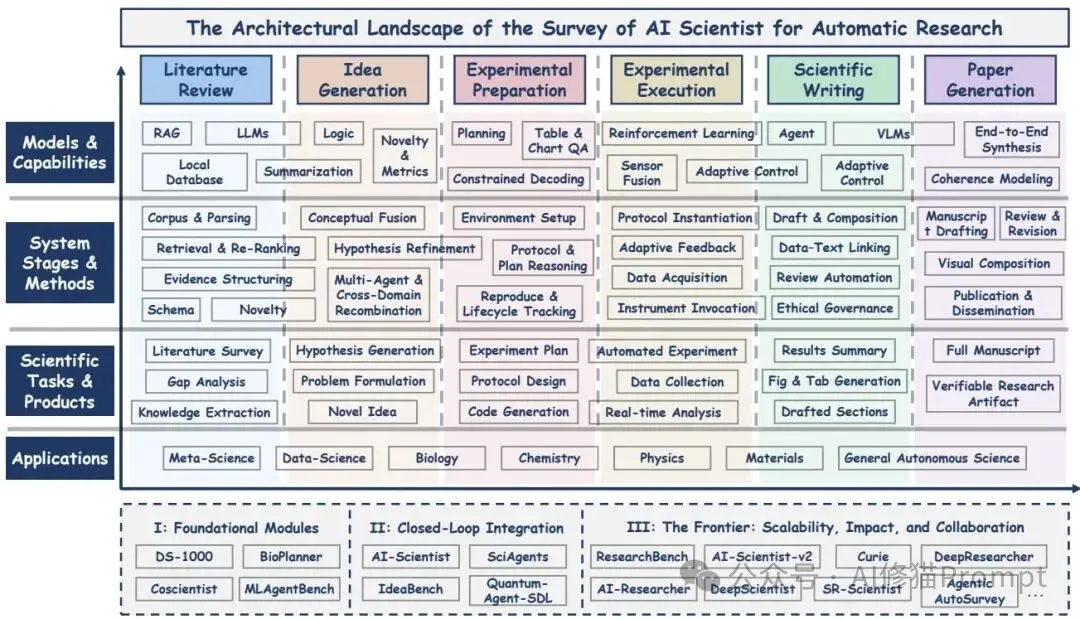
这张图把横轴的六个方法阶段与纵轴的四层抽象放在同一画布,并在底部附上历史演进小面板,您一眼就能把具体工作定位到“做了哪一段、处在哪一层”;我觉得,把体系图先立起来,再去填每个格子的能力与评测,会比单点优化更稳,尤其当您在多个学科场景之间迁移时。
这套闭环并不是口号,而是一条能被实现的流水线:先把非结构化文献转成可推理的结构,再在可追溯的语义层上衍生假设,随后跨数据与设备的执行管道接手,最后通过具备证据链接的写作与论文生成把结果沉淀下来。您可以把它理解为“知识—计划—执行—表述”的往返循环,过程中保留可审计的来源、参数与日志,以便复现实验与复核论断。
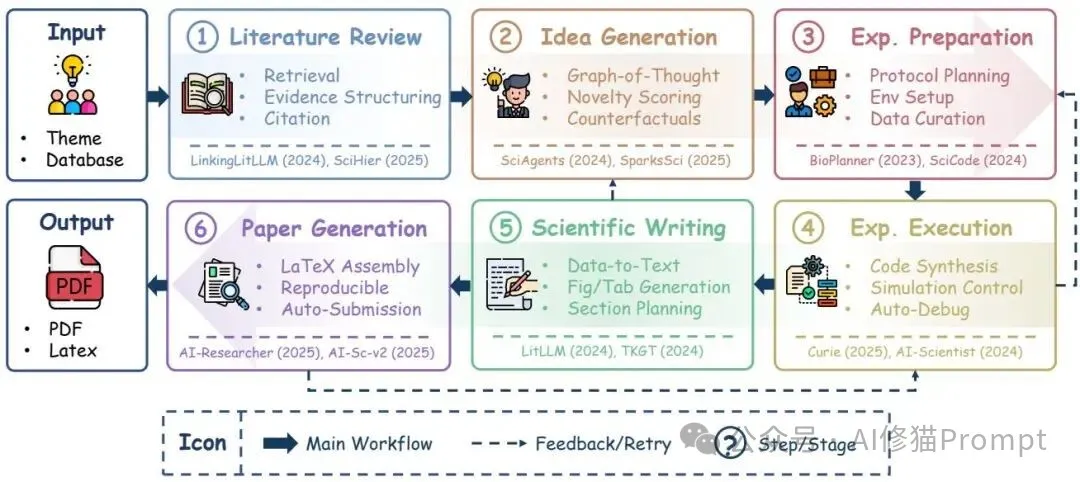
图示把“综述—构思—准备—执行—写作—论文”串成一个可反射的闭环,外圈保留自检与评估通道;您用它做实施蓝图时,别忘了把每一段的输入/输出契约写清楚,并把溯源与日志管道预埋进去,这会直接决定后续复现与审计的成本。
研究者把文献综述明确成五步流水线:语版式解析与语料构建(S2ORC、GROBID)、混合检索与重排序(BM25+SciBERT/SPECTER2、PaperQA/RAG)、证据结构化(信息抽取、知识图谱、T³与TKGT式表格对齐)、模式归纳与比较表生成(ArxivDIGESTTables)以及带新颖度分析的叙述综合(LitLLM、SCIMON)。您会看到,结果不是一段摘要,而是带来源锚点的图谱、表格与差异矩阵,反馈还能反向驱动二次检索与结构修正。
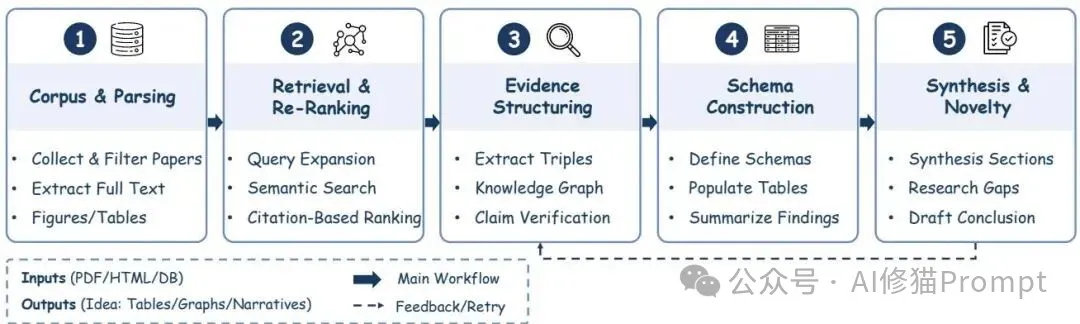
这张流程图把五个子阶段与反馈箭头画得很清楚:版面解析生成规范化语料,混合检索进入重排序,随后抽取—图谱—表格化,最后产出带新颖度标注的叙述;您可以按图就班地落地,每一步都保留证据—段落的可回溯链接。
这部分并非随意脑暴,流程被拆成“概念融合与趋势外推—知识约束的精炼—多代理协作—可行性与新颖度评估”,对应到 MOOSE-Chem、HypER 的溯源蒸馏、Scideator/Nova 的多角色对话,以及 GraphEval、IdeaBench/AI Idea Bench 2025/LiveIdeaBench 的量化评估。您可能会问,怎么避免“天马行空”?答案是用本体/知识图与可证据回溯约束生成,再用不确定性与反事实模拟去筛掉不稳健的假设。
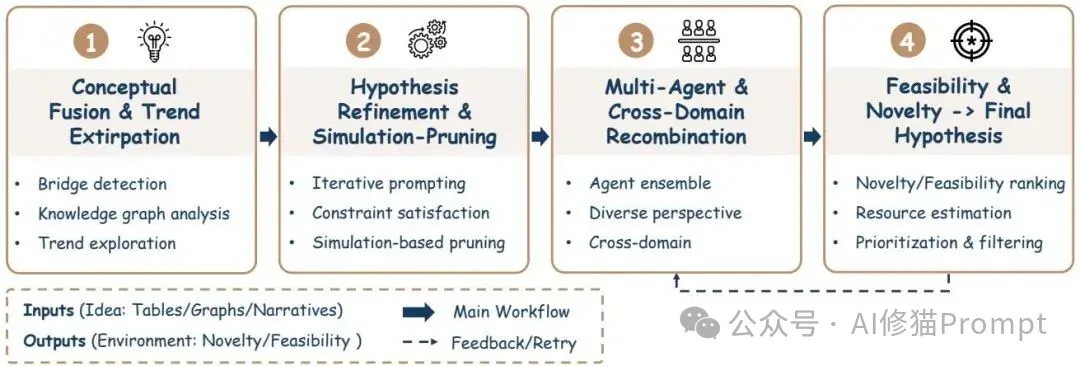
图中把概念融合、趋势外推、协同脑暴与评分优选串为一个闭环,您可以把“假设池”当作带来源与评分标签的中间产物,后续任何修订都回写到该池;不过,评分要和可行性/新颖度分开看,免得把“有创意但不可测”的点误选出来。
我觉得很多失败并非出在执行本身,而是出在“准备不稳”;这里的四步法是:实验表述(变量、指标与信息增益视角的目标化,TableBench、Chain-of-Table、ChartQA/ChartX 等多模态理解助力)、环境与仪器就绪(DSBench、BLADE、InfiAgent-DABench、DAgent 的数据与工具编排,AutomataTikZ、Text2Chart31 的可视化预注册)、协议实现与计划推理(MM-Agent、DiscoveryBench、DS-Agent 强调中间检查点与可回滚)、可复现与全生命周期追踪(环境快照、参数沿革、跨代理一致性评估)。这样,您拿到的是一套可部署、可校核的执行骨架。
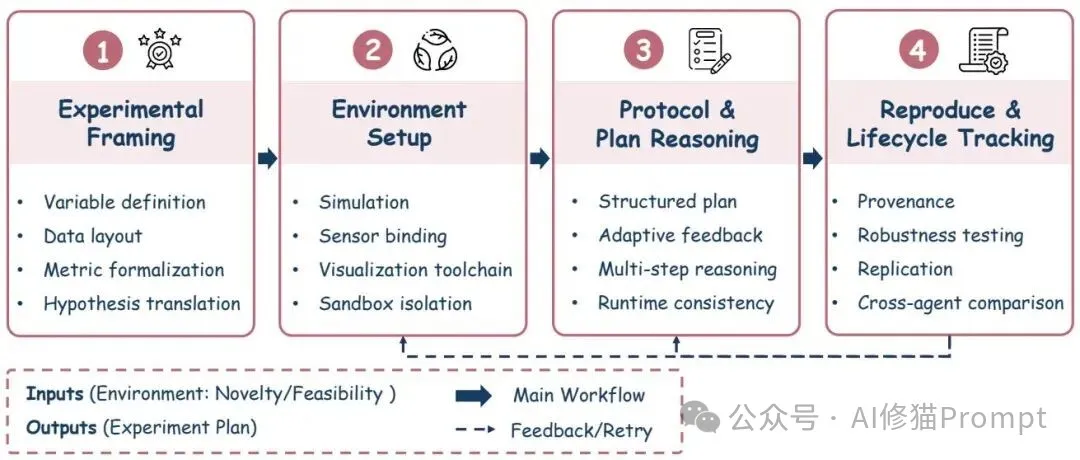
这幅图强调把变量、指标与可视化预注册放到执行之前,并把数据后端、工具接口与可视化管线统一到同一编排层;您要做的,就是把“可回滚的中间检查点”和“环境快照”变成默认机制,而不是出了问题再补救的止损手段。
执行被进一步拆成四步:协议实例化(BioPlanner 的自然语言到协议、Curie 的因果约束结构)、工具与设备调用(自驱动实验室、ORGANA、AutoLabs 这类多代理化学平台,乃至大科学装置的多阶段控制)、自适应执行与反馈(EXP-Bench、Curie 的误差界与再计划、Coscientist 在化学配比中的闭环迭代)、数据采集与校验(多模态记录、统计与符号双重校核、运行时分析模块)。不过,线性脚本在这里会吃亏,带自检与再执行的循环才更稳妥,尤其当传感器与外设的噪声都不受您控制时。
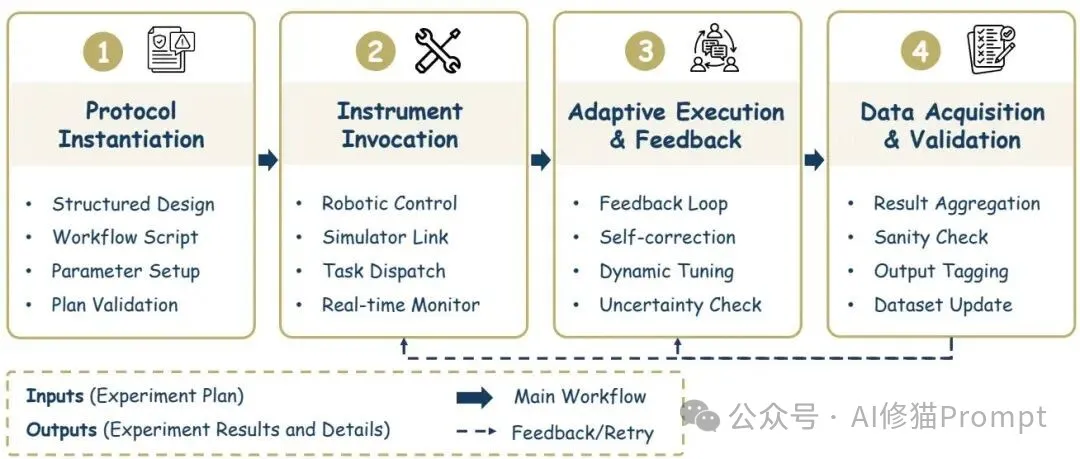
图里把设备调用与反馈回路并列展示,您可以按误差界、数据质量与复现分数三条线触发再计划;虽然代价看似更高,但把“失败的中间状态”完整记录下来,反而能降低总成本,因为复盘与再现的时间会明显缩短。
写作不是把结果“润色一下”就好,研究者给出五个部件:结构化起稿(段落—章节一致性、检索对齐)、数据—文本联动与多模态呈现(跨表格/图形的锚点与交叉引用)、类同行评审的自动化质检(结构化意见与可解释评分)、伦理合规与署名治理(披露模型与提示词、贡献分层)、端到端出版优化(WritingBench、SPOT 这类面向事实、引文与体例的一体评测)。您会看到,图表标题、段落主张与证据路径都能被联动校核,而不是“写完再补充参考文献”。
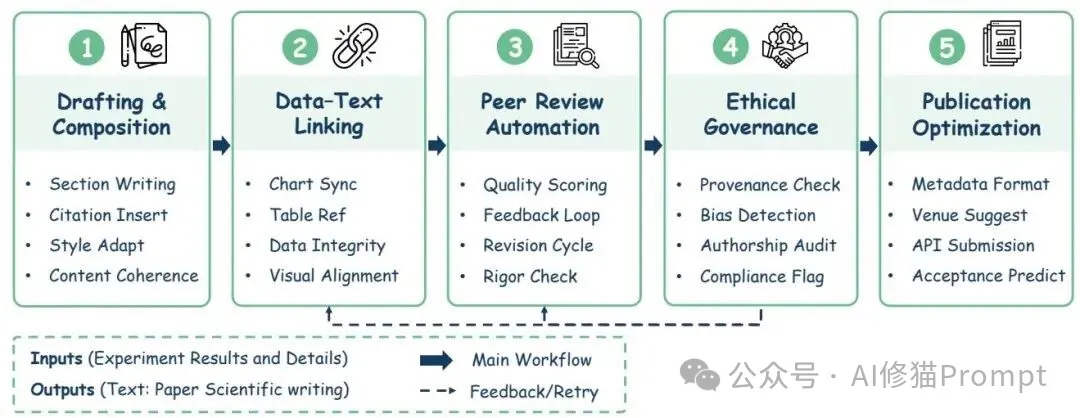
图中的前向箭头表示内容生成通路,回路表示评审与治理反馈返回起稿阶段;您若在本地编辑器集成此链路,建议把“来源锚点与可视化对象”的绑定做成强约束,避免文本、图表与表格在反复改动后出现对不上的问题。
在 The AI Scientist v1/v2、AI-Researcher 这类系统里,论文生成被分解为起稿、图表与表格生成/嵌入、评审与修订代理、传播与发布,且每步都与前述产物打通;你知道吗,很多系统直接把实验日志—到—LaTeX 的转换、图表自动生成与交叉引用做成流水线,Scientist-Bench 也开始评估这种端到端的连贯性。虽然自动化更强,但研究者强调溯源与审计优先,避免“黑箱稿件”流入文献体系。
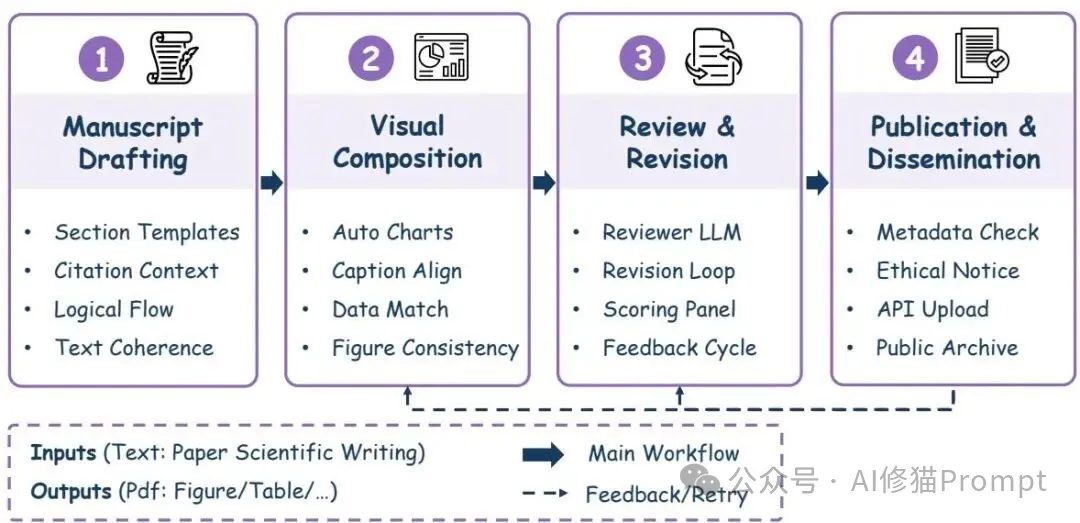
这幅图把论文生成拆成四段并标注前向与回路箭头,实操里您可以把图表生成与评审代理做成“循环对话”,直到事实一致性、引用完整性与体例合规同时满足,再一次性冻结为可投递的定稿包。
历史脉络被清晰地划分为三段:2022–2023 年的“基础模块”(DS-1000、BioPlanner、Coscientist、MLAgentBench 等把准备与执行的硬骨头啃下来)、2024 年的“闭环整合”(The AI Scientist v1 把各段串成端到端论文生成)、到 2025 年前沿的“可扩展、有效性与协作”(DeepResearcher 的真实网页强化、DeepScientist 的长程目标驱动、freephdlabor 的深度人机协作)。结果是,自治更强,但与人的协作也更细腻。
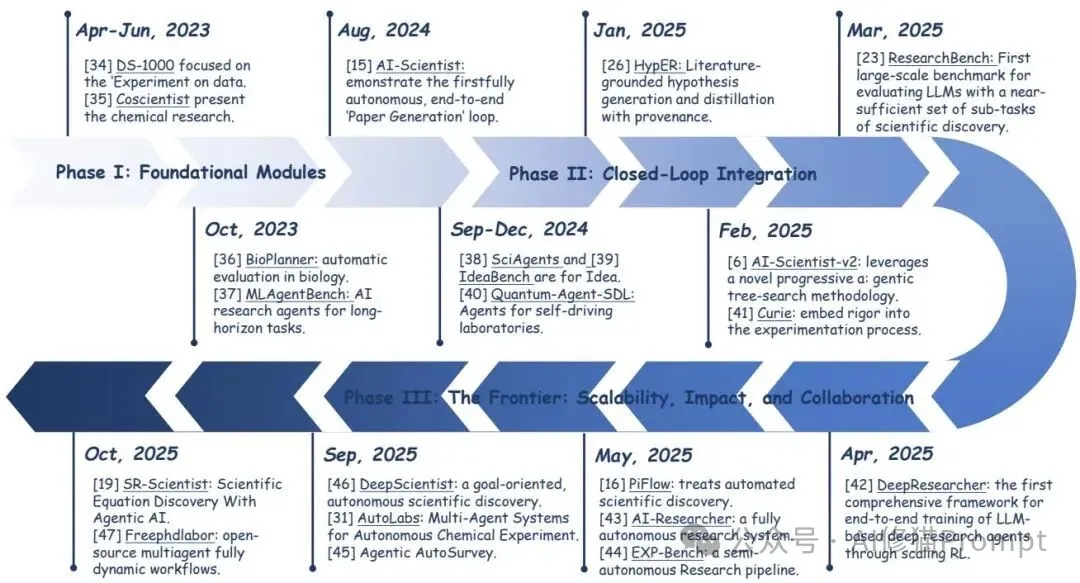
时间线图把代表性工作放在三段轨迹上,向上的箭头对应自治与整合度的提升;我建议您在做路线规划时,把自家系统定位到这条时间线上,明确下一步是在“闭环强化”,还是在“协作与规模”上做结构性投入。
通用系统方面,The AI Scientist v1/v2、AI-Researcher 与 Curie 分别在端到端闭环、可回溯记忆图与因果化实验控制上树立了不同侧重;而在化学与材料,Coscientist、A-Lab、Robotic AI Chemist、AutoLabs 借助自驱动实验室实践闭环;在生物/医药,BioPlanner、LLM4GRN、层次化表示的协议设计处理高噪复杂流程;在物理与工程,Agentic Physics Experiments、SR-Scientist、AI Feynman、Quantum-Agent-SDL 把符号回归、规则发现与大型装置控制推到台前。
您可能更关心“怎么量化”,文献把评估拆成环节化与端到端两层:环节上有 IdeaBench、GraphEval、DSBench、BLADE、InfiAgent-DABench、EXP-Bench、CharXiv 等;端到端侧重写作与发布完整性,有 WritingBench、SPOT 与 Scientist-Bench;另外,多数系统引入可复现要素(环境确定性、哈希化数据/模型、细粒度来源链路)与不确定性表达,让评分更贴近真实科研场景而非“单次跑分”。
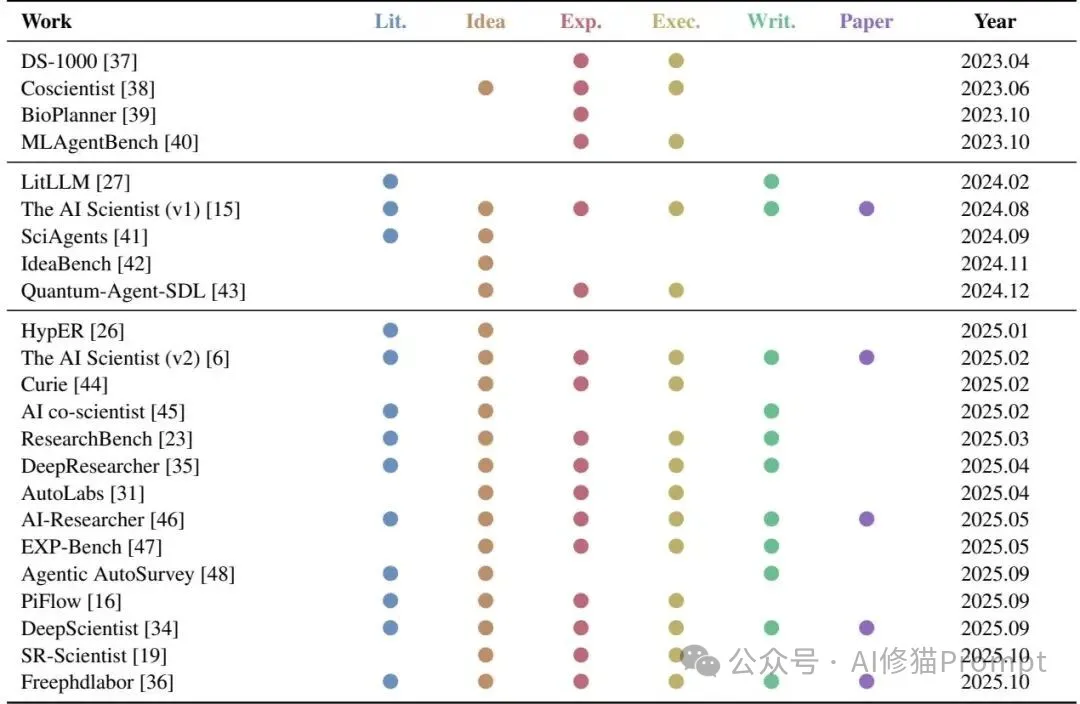
这张矩阵以“六阶段”为列、以代表性工作为行,标注每项覆盖的能力段并附上年份,您可以据此挑选评测子集构成内测套件;不过,别把这个表当终点,它更像是“能力缺口雷达”,帮助您识别下一个该补的短板。
起步建议是三段式:一套可靠的文献—知识结构化底座(版式解析、混合检索、抽取与表格/图谱归一、差异/新颖度分析);一条规范的准备—执行—追踪骨架(变量—指标—计划、数据/工具编排、运行时校验与回滚、环境快照与日志);一套写作—评审—合规的发布通道(起稿到图表联动、自动评审循环、披露与署名治理)。不过,您别急着“一把梭”,先用一个可控子域做灰度,如 DS-1000 的数据科学任务或一条化学合成链路。
场景是材料筛选:您用文献综述管道在特定体系上生成知识图与比较表,构思阶段在趋势外推与本体约束下得到候选合成路线;准备阶段将变量与可测指标对齐到自驱动实验室,预注册必要的谱图与曲线;执行阶段走 AutoLabs/ORGANA 的多代理架构做配方与校准,实时基于误差界再计划;写作阶段把谱图、表格与叙述自动交叉锚定,并生成披露清单。
目标是复现与改进某个 ML 论文实验:综述阶段用 PaperQA 与 RAG 拉取相关证据并构表,构思阶段利用多代理角色拆解潜在改进点;准备阶段用 DAgent 的模式连接到结构化数据后端并约定 SQL 报告模板;执行阶段对照 DSBench/BLADE 的运行时检查点做自适应超参更新;写作阶段依 WritingBench 与 SPOT 做一致性核对与规范化投递。
研究者在开放问题中给出四条主线:从“可复现设计”走向“可验证科学”(环境确定性、可加密溯源、自动审计代理);把不确定性当作一等公民(并行假设、贝叶斯式推理、知道何时建议追加数据或征求人类判断);通过模块化与可组合架构跨域迁移(具备清晰 I/O 契约的能力因子化工具箱);以及深化人机协作与伦理治理(角色化协作协议、透明署名与风险分级执行)。这些并非画饼,而是下一代系统能否进入主流科研流程的前提。
如果您现在就要动手,建议按“底座—骨架—通道”的三层化建设,底座解决证据与结构化,骨架保障准备—执行—追踪稳定,通道确保写作—评审—合规闭环;虽然一步到位很诱人,但分域试点—跨域扩展—规模化协同可能更稳,过程中务必保留来源链、参数谱系与自动化检查表,把系统变成可被信任的科研合作者,而不是一次性的脚本堆栈。
[1]: https://github.com/Mr-Tieguigui/Survey-for-AI-Scientist。
文章来自于“Al修猫Prompt”,作者“Al修猫Prompt”。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
