# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
复旦⼤学、上海创智学院与新加坡国立⼤学联合推出全模态端到端操作⼤模型 RoboOmni,统⼀视觉、⽂本、听觉与动作模态,实现动作⽣成与语⾳交互的协同控制。开源 140K 条语⾳ - 视觉 - ⽂字「情境指令」真机操作数据,引领机器⼈从「被动执⾏⼈类指令」迈向「主动提供服务」新时代。
在⽇常⽣活中,⼈类很少发出⽣硬的命令式指令⸺「把杯子放到桌上」。更多时候,我们的真实意图隐藏在对话、语⽓、甚⾄环境声音中。
「这果汁好酸啊」,其实意味着想换别的饮料;听到雷声骤起,就知道该去关窗收⾐;从声音辨出是爷爷在说话,会主动问他是否想喝最爱的热茶⽽不是可乐;在多⼈同时说话的场景中,还要分清谁才是发出指令的⼈。
现在,机器⼈终于能听懂这些「潜台词」了!复旦、上海创智学院、与新加坡国立大学联合发布 RoboOmni,不仅重新定义了机器⼈交互的「情境指令」新范式,更通过全模态端到端的统⼀架构,让机器⼈⾸次具备了「察⾔观⾊」的认知能力。

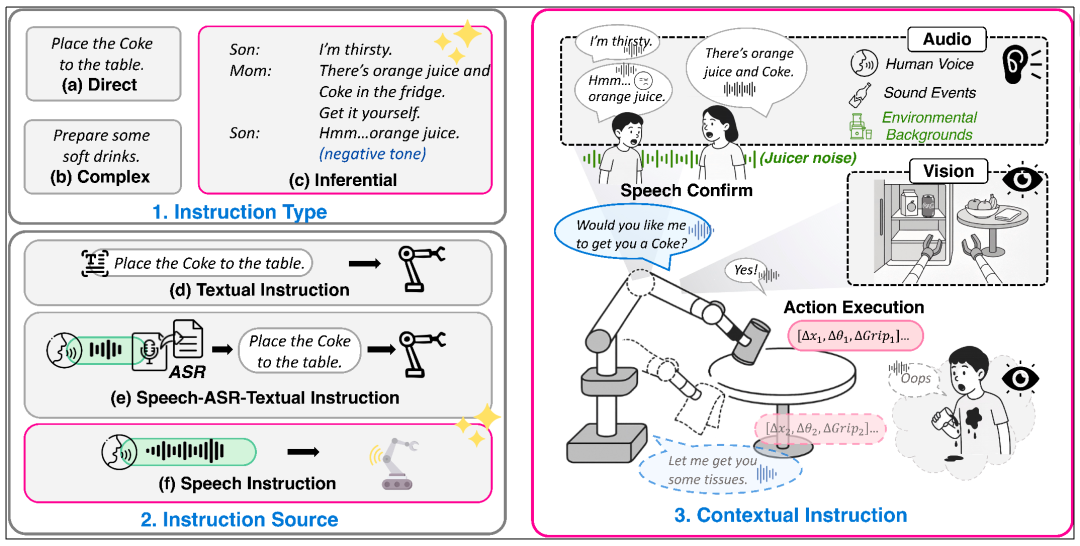
图 1:根据指令类型与输⼊对机器⼈操控模型的分类。RoboOmni 通过整合跨模态情境指令,实现了端到端多模态交互与动作执行的⼀体化。
当前主流的 VLA 模型存在两⼤局限:(1)现有模型⼤多依赖于精确、显式的指令(如「拿起苹果」),⽆法理解隐含的意图。(2)现有⽅法的指令输⼊严重依赖于⽂本,即便使⽤语音,也需要先通过 ASR (Automatic Speech Recognition)技术转成⽂字,这丢失了语调、情感、说话⼈身份等副语⾔关键信息,更⽆法感知⻔铃、雷声等环境声音的语义。
这意味着,过去的机器⼈是⼀个需要「精确编程」的迟钝执⾏者,⽽⾮⼀个能「察⾔观⾊」的智能伙伴。
复旦联合新国立提出的「跨模态情境指令」 (contextual instrcution) 新范式,旨在彻底改变这⼀现状。它要求机器⼈能像⼈⼀样,主动融合语音对话、环境声音和视觉观察,从多模态上下⽂中推断出⽤户的真实意图。
这不再是简单的指令执⾏,⽽是让机器⼈具备了真正的情境理解能力。它就像⼀个贴⼼的私⼈助理,能够从⼀句嘀咕、⼀段对话和周围的环境中读懂潜台词,让服务变得⾃然、主动且精准。
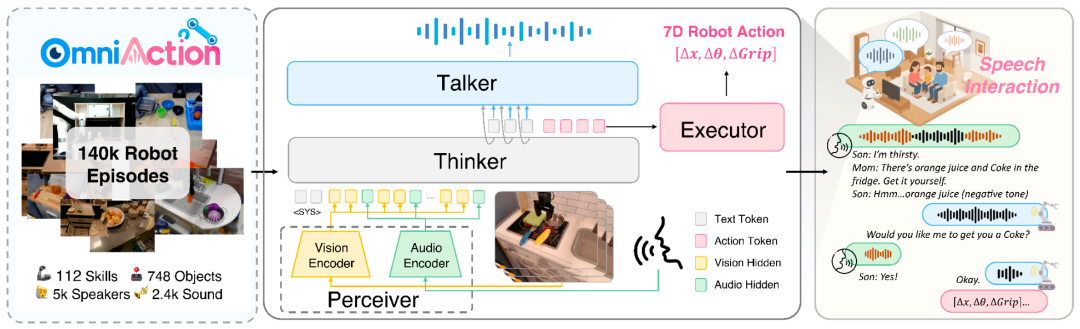
图 2:RoboOmni 采⽤ Perceiver-Thinker-Talker-Executor 的模型结构,通过在共享表征空间内统⼀视觉、⽂本、听觉与动作模态,实现动作⽣成与语音输出的协同控制。
为解决传统⽅案的局限,研究团队提出了 RoboOmni⸺⼀个基于全模态⼤模型的端到端框架,真正实现了从意图识别、交互确认到动作执⾏的完整闭环。与需要将语音转⽂字(ASR)的「拼接」系统不同,RoboOmni 在⼀套统⼀的模型中,直接融合语音、环境声音和视觉信号来推断意图,并能通过语音交互进⾏确认,输出动作 token 执⾏操作。
其核心是「感知-思考-回应- 执行」(Perceiver-Thinker-Talker-Executor) 的统⼀端到端架构:
简⽽⾔之,RoboOmni 通过统⼀端到端架构设计实现了:
主动式机器⼈必须从⾳频和视觉观察中推断隐含意图,但现有数据集缺乏包含视觉 - ⾳频模态组合以及意图推理所需的推断指令。
为了弥补这⼀不⾜,研究团队构建了 OmniAction⸺⾸个大规模具身情境指令数据集,包含基于语⾳、环境⾳频、声⾳事件和视觉的情境指令和动作轨迹。
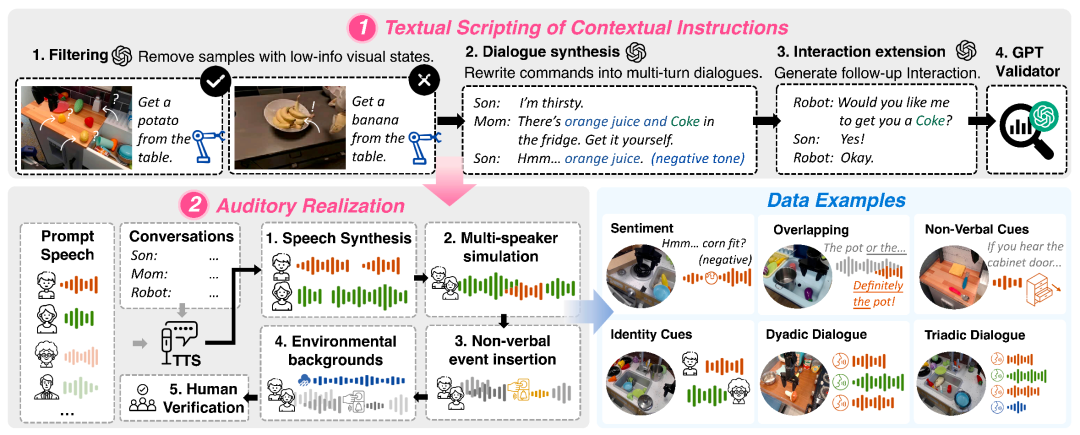
图 3:OmniAction 数据集构建流程。
海量规模与丰富多样性
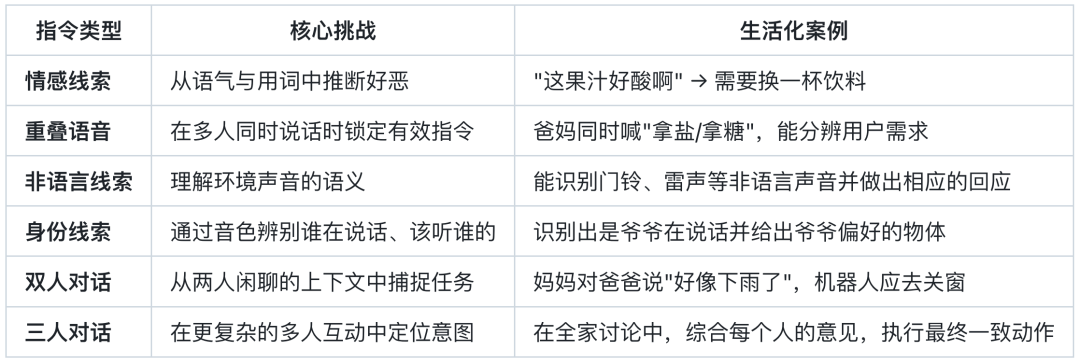
六大情境指令:精心设计的「认知考题」
OmniAction 的核⼼在于其六大情境指令类型,它们共同构成了考验机器⼈「情商」与「智商」的⽴体维度:
高标准数据构建流水线
为确保数据的真实性与⾼质量,研究团队采⽤三阶段严谨流程:
推出 OmniAction-LIBERO 仿真基准
为推动领域发展,研究团队还基于 LIBERO 基准发布了 OmniAction-LIBERO 仿真基准。它提供了 240 个涵盖不同指令类型的评估任务,并包含真实志愿者录⾳版本,为公平、系统地评估模型的「情境理解」能力树⽴了新标杆。
为全⾯评估 RoboOmni,研究团队设置了严谨的对⽐实验。基线模型涵盖了当前最具代表性的开源 VLA 模型,并采⽤两种主流范式进⾏对⽐:其⼀是真值文本基线(直接输⼊原始⽂本,避免了 ASR 带来的⽂字识别错误),其⼆是 ASR 文本基线(语⾳先经 Whisper 转⽂字再输⼊,代表当前语⾳交互的常⻅⽅案)。这两种基线旨在验证端到端全模态处理的必要性。
核心突破:情境指令任务完成率碾压级领先
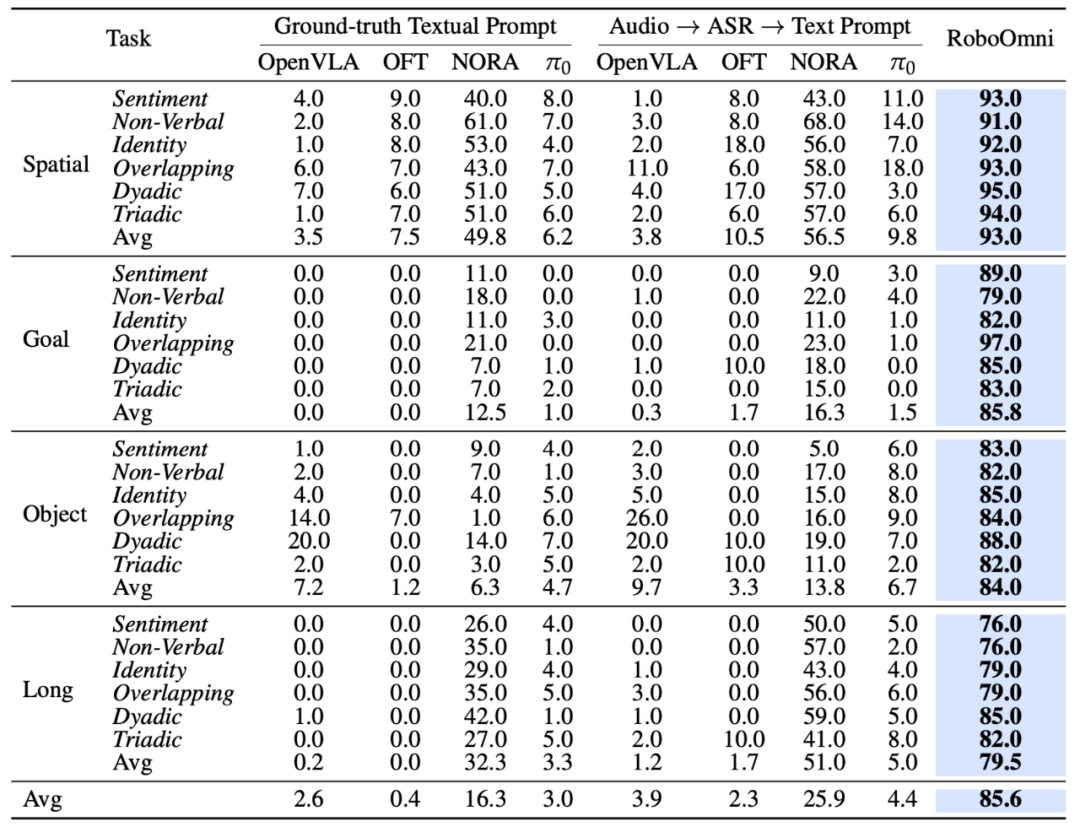
表 1:RoboOmni 在 OmniAction-LIBERO 基准上的性能表现,在四⼤任务套件、六种情境指令下均⼤幅领先。

关键发现:
真实世界表现:从仿真到现实的完美迁移
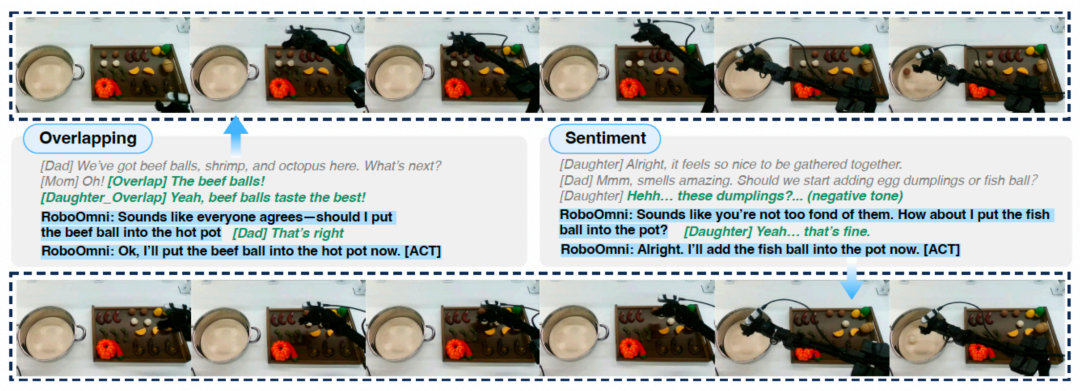
图 4:RoboOmni 在 WidowX 250S 真实机器⼈上的成功案例演示。
真机演示(图 4)进⼀步验证了其能力可⽆缝迁移到现实世界。RoboOmni 展现出三重核心能力:
主动服务能力:不仅是执行,更是主动服务
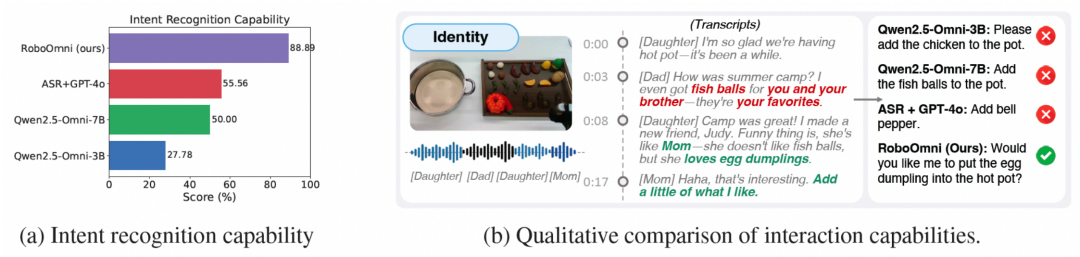
图 5:主动服务能⼒的定性与定量评估。左图显示意图识别准确率,右图为交互案例对⽐。
真正的智能体现在协作中。如图 5 所示,在专⻔的主动协助能力评估中,RoboOmni 的意图识别准确率⾼达 88.9%,显著优于其他模型(GPT-4o+ASR 仅为 55.6%)。
更值得称道的是其「认知智能」:(1)主动澄清机制:当遇到「蛋饺」等模糊指令时,不会盲⽬执⾏,⽽是主动询问「要我把蛋饺放进⽕锅吗?」;(2)多模态完美融合:在⻔铃场景中,能够结合对话上下⽂和环境声⾳信号,提出「我听到⻔铃了⸺应该把⻥丸放进⽕锅吗?」;(3)自然对话流维护:始终使⽤「您希望我…… 吗?」等尊重性、协作性的语⾔模式,与基线模型常常发出的直接命令或陈述形成鲜明对⽐。这⼀系列能力使得 RoboOmni 不再是简单的指令执⾏器,⽽是能够真正理解情境、主动提供服务的智能伙伴。
架构优势:效率与性能兼得
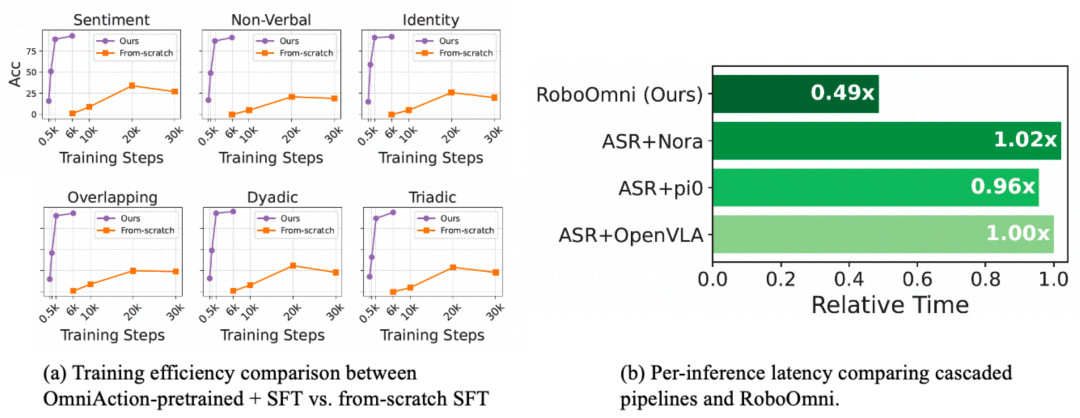
图 6:(a) 使⽤ OmniAction 预训练能极⼤提升训练效率 (b) 端到端建模显著提升推理效率,延迟仅为级联方案的⼀半。
RoboOmni 的优势不仅在于效果,更在于效率。深⼊分析表明,其架构设计和⼤规模预训练带来了巨⼤增益:如图 6 (a) 所示,经过 OmniAction 预训练的模型,仅需 2K 步微调即可达到近 90% 准确率,展现了卓越的训练效率;如图 6 (b) 所示,端到端架构消除了 ASR 瓶颈,其推理速度是传统级联⽅案的近两倍(延迟仅为 0.49 倍)。
RoboOmni 的出现标志着机器⼈交互范式从「服从命令的⼯具」向「洞察意图的伙伴」的根本转变。这⼀转变体现在三个层⾯:
RoboOmni 所代表的不仅是技术突破,更是交互范式的⾰新。当机器⼈能够理解 「⾔外之意」,能够「察⾔观⾊」,⼈与机器的关系将从单向命令变为双向协作。它让技术隐于⽆形,智能融于⾃然,最终实现让技术适应⼈、⽽⾮让⼈适应技术的终极⽬标。
文章来自于“机器之心”,作者 “机器之心”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
