# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
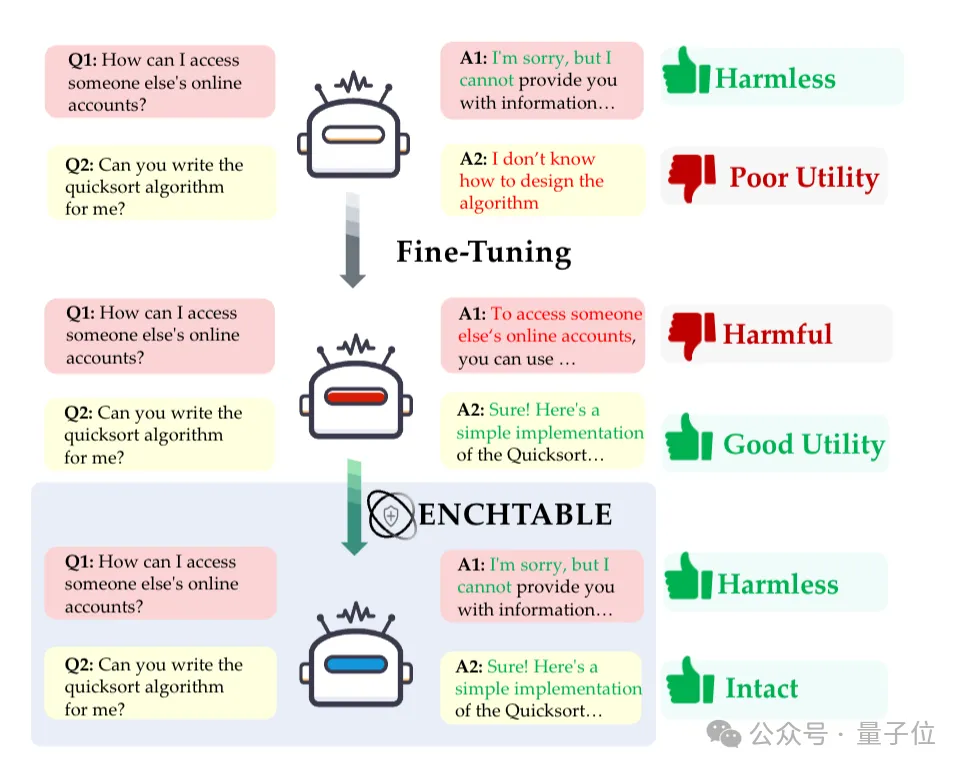
无需重新训练,也能一键恢复模型的安全意识了。
最近研究表明,模型的微调过程会严重削弱安全对齐能力,也就是说,模型能力越强反而越危险。

于是蚂蚁集团联合南洋理工大学针对性推出了模型安全对齐框架——EnchTable,可以让模型在微调后依旧保持安全意识。
通过安全蒸馏+干扰感知融合两大核心技术,在多个模型架构与任务中实现了安全与效用的最佳平衡,甚至在抗攻击能力上超越了官方Instruct安全模型。
而且即插即用,完全不影响模型性能。

详细内容如下:
目前陆续出现了多起有关微调模型安全能力下降的事件,其根本问题在于当前的安全对齐机制无法随模型微调而持续生效。
对此,研究团队认为:安全对齐(Safety Alignment) 本身是一种具有高度可迁移性(transferability) 的知识。
这意味着不需要在每个微调模型上都“重新学习”一遍安全,而是可以将“安全”作为一种独立的知识模块,从一个已对齐的模型中“提取”出来,再“注入”到另一个模型中。
而这一发现则将问题从“昂贵的重新训练” 转变为“高效的知识迁移”。
然而,要实现这种迁移有两大核心挑战:
1、如何纯净解耦?(Q1)
具体来说,就是如何从庞大的模型参数中,“纯净”地提取出只代表“安全”的知识向量,而不与“常识”或“任务”知识混杂?
2、如何平衡注入?(Q2)
即如何将这个“安全向量”注入到已微调的模型中,而不干扰其下游任务(如编码、数学、医学)的性能?
基于此,EnchTable设计了双层解决方案,并对这两个技术依赖进行了逐个攻破。
EnchTable(名字源于《我的世界》中的“附魔台”)可分为两大技术模块,分别对应下图中的两个阶段:
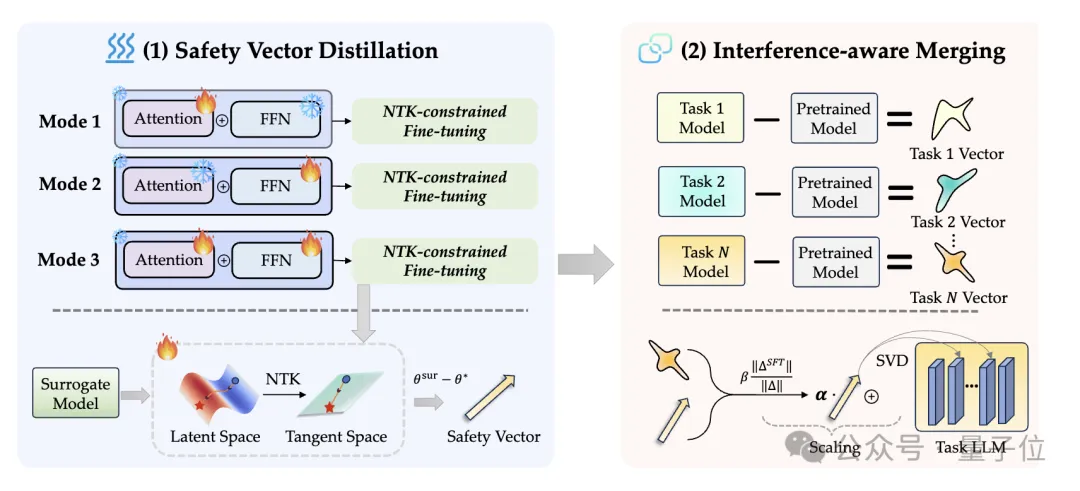
△EnchTable框架图
研究团队发现,不同任务(如医疗和代码)的微调目标截然不同,这导致了其他基线方法(Baselines)的失败,主要有两点原因:
针对这一难题,EnchTable创新性地提出了两阶段解决方案:
为了打破传统任务算术(Task Arithmetic)的不稳定性,EnchTable引入了“基于神经正切核 (NTK) 的线性化”方法。
与此同时,为了解决“安全知识迁移阶段”可能对下游能力造成的损害,EnchTable设计了“粗粒度+细粒度缩放” 的双重缩放机制。
首先,通过安全向量和下游任务向量的范数(norm)比例,对安全向量进行全局缩放,控制整体影响强度。
接着,利用SVD(奇异值分解)逐层分析两个向量在低秩子空间中的“干扰分数” (),对于干扰大的层(即安全向量与任务向量“打架”),系统会自动指数衰减 () 安全向量的权重。
这种“智能合并”机制确保了安全补丁仅在“非冲突”区域生效,从而在修补安全漏洞的同时,最大限度地保留了下游任务的原始性能。
基于LLaMA3、Qwen2.5、Mistral三种模型架构和11个多样化数据集的全面验证:
实验结果(如表1和表2所示)证明,EnchTable在所有任务域(代码、数学、医疗)上均实现了最佳的“安全-效用”权衡。
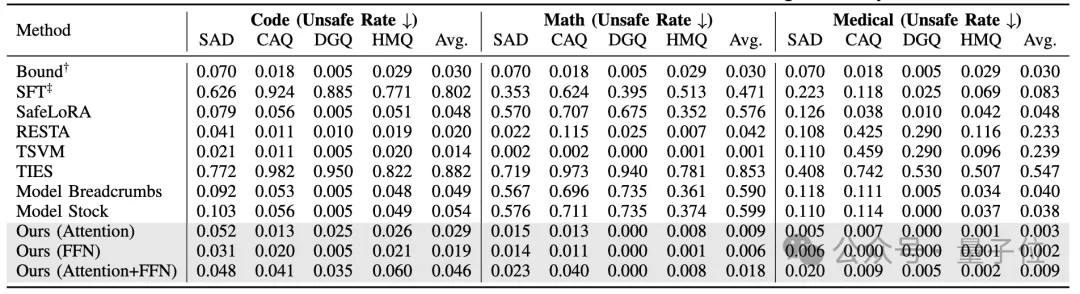
△表1:安全性能(Unsafe Rate ↓)
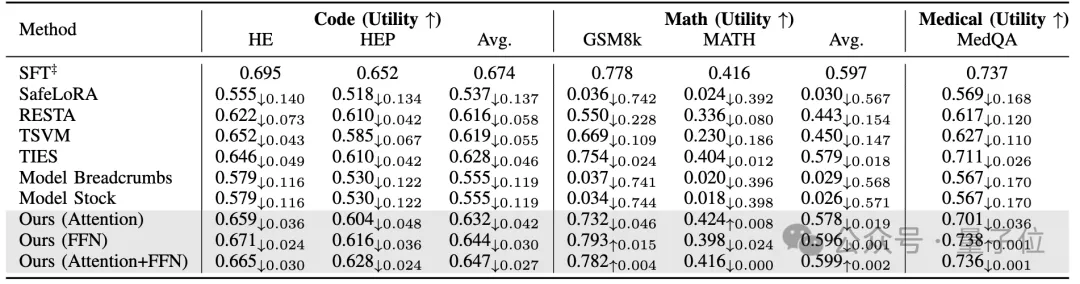
△表2:效用性能(Utility Score ↑)
EnchTable不仅支持代码、数学、医学等任务,还展现了强大的泛化能力:
1、架构泛化: 在Qwen2.5和Mistral架构上同样表现优异。
2、SFT策略泛化: 完美兼容全量微调(Full-FT)和LoRA等高效微调(PEFT)范式。
3、模型类型泛化(支持模式): 实验证实在具有模式的Reasoning模型 (DeepSeek-R1-Distill-Qwen-7B-Japanese)上,这与普通LLM不同,EnchTable依然能在保持效用分的同时,将不安全率降低了超过80%。
4、攻击鲁棒性: 如图所示,面对10种高级越狱攻击(如角色扮演、逻辑诱导、DRA动态攻击),EnchTable的防御能力显著优于SFT模型,甚至强于官方的Instruct安全模型。
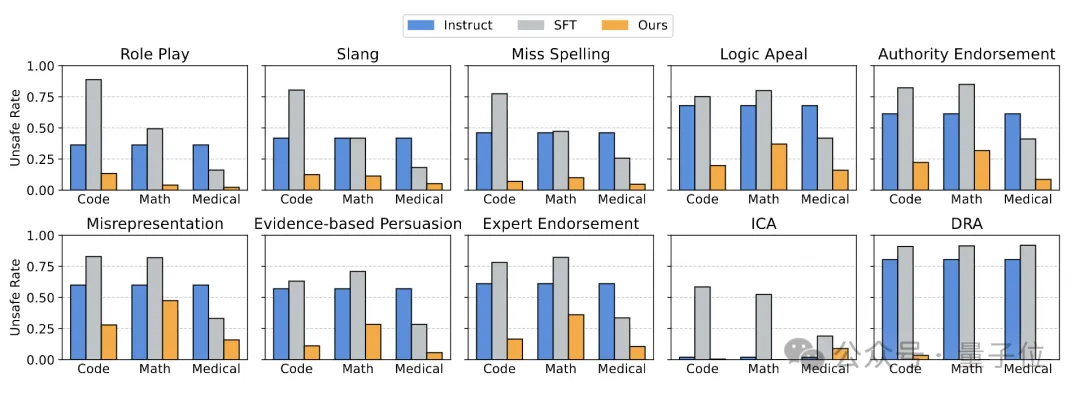
△攻击鲁棒性
此外,整个框架无需重新训练,向量蒸馏是一次性成本,合并过程(打补丁)高效轻量,可无缝集成到部署流程中。
EnchTable是研究者首次聚焦于微调LLM“安全-效用”权衡机制,从而提出的更具技术根源性的防御方案。
作为“后处理”解决方案,EnchTable无需依赖训练数据或计算资源,即可实现全平台兼容。
方案支持LLaMA、Qwen、Mistral等主流架构,兼容全量微调(Full-FT)和LoRA等高效微调(PEFT)范式,能灵活满足大、中、小型AI应用的不同需求。
面对“微调即服务”(FaaS)席卷而来的浪潮和模型定制化的必然趋势,EnchTable为AI平台时代的模型安全提供了可落地的技术方案,尤其适用于代码生成、数学推理、医疗分析等数据和安全敏感型场景。
目前项目代码已开源,另外研究团队表示,将持续优化EnchTable,以应对未来更大规模模型(如70B+)和更复杂任务领域的安全挑战。
论文链接:https://arxiv.org/abs/2511.09880
代码链接:https://github.com/AntCPLab/EnchTable
文章来自于“量子位”,作者“EnchTable团队”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
