# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当你对下一步感到迷茫时,AI的答案可以不再只是文字,而是一段为你定制的视频。

你是否曾有过这样的经历——
看着网上「如何打温莎结」的图文教程,手里的领带却依然不听使唤;或者看完一段电影预告片,心里疯狂猜想:「下一秒,主角会做出什么惊人的举动?」
传统的AI模型可能会给你一段文字描述作为答案,但「听到」和「看到」之间的差距,有时就是学不会和秒懂之间的天堑。
今天,来自快手可灵团队和香港城市大学的研究者们,正在尝试打破这一界限。他们提出了一个全新的任务范式——「视频作为答案」,并发布了相应模型VANS。
这意味着,AI不仅能「想」到接下来会发生什么,还能直接「秀」给你看!
目前,强大的语言模型已经深入各行各业,但视频生成技术却大多局限于娱乐和内容创作。
这项研究的动机正在于此:视频天生就承载着语言难以精确描述的动态物理世界信息。
想象一下,仅用文字教人打领带有多困难?而一段视频演示则一目了然。
此前,学术界对于「下一事件预测」任务的研究,答案形式始终是文字。
而这项工作则开创性地提出了Video-Next Event Prediction任务,要求模型直接生成一段动态视频作为回答。
这一从「讲述」到「展示」的转变,解锁了更直观、更个性化的信息传递方式。

不过,想让AI生成一个「对的」视频,而不仅仅是一个「好看的」视频,挑战巨大。这要求模型必须:
1、理解输入的视频和问题。
2、推理出符合逻辑或因果关系的下一事件。
3、生成一个在视觉上连贯、且在语义上忠实于推理结果的视频。
一个简单的想法是「流水线」作业:先让一个视觉语言模型「思想家」写出文字描述,再让一个视频生成模型「艺术家」根据文字来创作。
但问题来了——「思想家」写出的描述可能语言上完美,但「艺术家」根本画不出来。
比如,「思想家」说「优雅地打一个复杂的领带结」,但「艺术家」缺乏相关素材,最终生成的内容可能四不像。
为了解决这个「语义到视觉的错位」难题,研究者们提出了VANS模型。

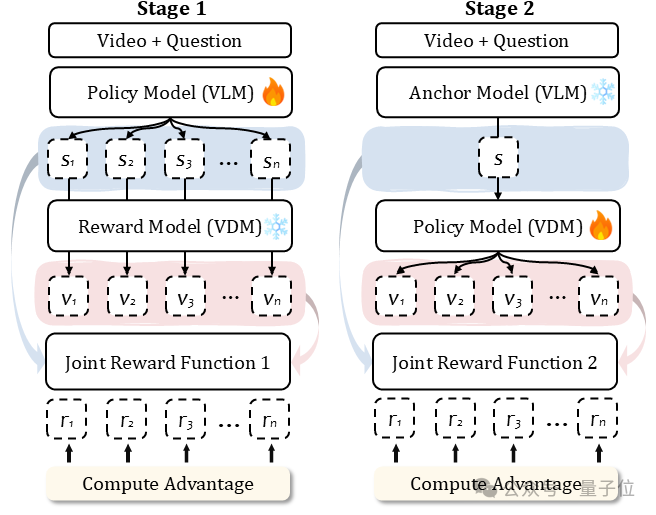
VANS模型由一个视觉语言模型和一个视频扩散模型构成,其核心创新在于通过联合分组相对策略优化算法对两者进行协同优化,而非简单的串接。
基本工作流程分两步。
1、感知与推理:输入视频首先被编码为视觉特征,与问题文本一同输入VLM。VLM的核心任务是进行思维链推理,最终生成一个描述下一事件的文本标题。
2、条件化生成:该文本标题与输入视频的低层级视觉特征(如通过VAE编码的帧序列)共同作为条件,输入VDM,以生成既符合语义又保持视觉连贯性的答案视频。
而VANS模型核心,是一种名为Joint-GRPO的强化学习策略。
传统的分别优化无法解决VLM与VDM之间的「语义-视觉错配」问题。
Joint-GRPO通过一个两阶段的强化学习流程,像一个「总导演」一样,对两个模型进行联合调教。
第一阶段:优化VLM,使其成为「视觉友好型编剧」
该阶段的目标,是让VLM生成的标题不仅准确,还要容易被VDM高质量地可视化。
为此,需要冻结VDM的参数,仅对VLM进行优化。对于VLM生成的每一个标题,都用当前的VDM将其生成视频,然后计算一个联合奖励:
1、文本奖励:评估生成标题与真实标题在语义上的相似度。
2、视频奖励:评估生成视频与真实视频在视觉上的相似度。
通过这个联合奖励的反向传播,VLM学会了如何「换位思考」,其生成的标题会主动规避那些难以可视化或容易导致歧义的语言,变得更加具体和可执行。
第二阶段:优化VDM,使其成为「精准的视觉执行者」
该阶段目标,则是让VDM生成的视频不仅能忠实反映标题内容,还能与输入视频的上下文保持高度一致。
为此,需要先冻结第一阶段优化好的VLM,将其作为「锚定模型」来生成高质量的参考标题。
随后,对VDM进行优化,其奖励函数包括:
1、视频奖励:确保生成视频本身的视觉质量和流畅度。
2、语义对齐奖励:强制要求生成视频的内容与VLM提供的锚定标题在语义上高度匹配。
这能防止VDM「偷懒」(例如简单地复制输入视频或生成无关内容),确保它严格地将文本描述中的动态事件转化为视觉现实。
简单来说,你可以把它想象成一位顶尖的导演体系:
「思想家」负责研读剧本,构思下一幕的情节;「艺术家」负责将构思可视化,拍成影片。
Joint-GRPO就是那位导演,他不仅会评判「思想家」的构思是否合理,还会看「艺术家」的成片是否精准呈现了构思。
通过这种联合的、双向的反馈,导演不断地调教两位专家,让他们配合得越来越默契。
最终,「思想家」学会写出更容易被可视化、且更准确的描述;而「艺术家」则学会了更忠实地根据描述和初始画面来生成视频。
两者从独立的个体,融合成了一个高效的创作团队。
这项技术绝不仅仅是实验室的玩具,它指向了两个极具潜力的应用方向:
程序性教学:你的随身生活助手

无论是烹饪、折纸、修理家电,还是打领带,当你卡在某个步骤时,只需拍下你当前的进度并提问:「下一步该怎么做?」VANS不仅能推断出你的下一步动作,还能生成一段从你当前状态开始的、无缝衔接的教学视频。
它看到了你锅里正在炒的菜、你手里半成品的领带,因此给出的指导是定制化的,而不是千篇一律的教科书步骤。
多未来预测:开启未来的无限可能
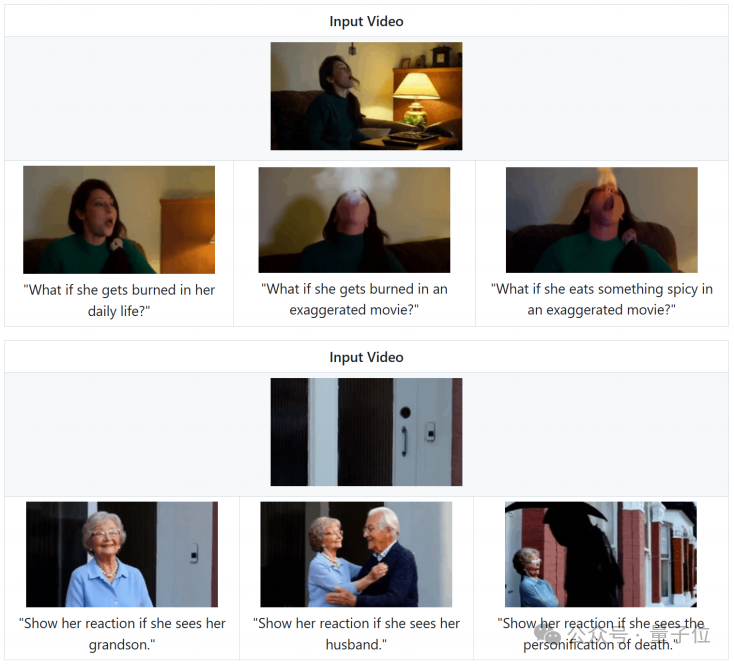
这或许是更富想象力的一点。给定一段视频,你可以提出各种「如果」式的问题:
VANS能够基于不同的假设,推理并生成出多种合理的未来视频。这为创意写作、互动娱乐、甚至自动驾驶的极端情况模拟,打开了无限的可能性。
全面的实验评估表明,VANS模型在程序性教学与未来预测两大基准测试中,其性能全面超越了现有的统一模型(如Omni-Video等)及级pipeline基线。
在衡量事件预测准确性的核心指标ROUGE-L上,VANS相比最强的统一模型取得了近三倍的性能提升。
在衡量生成视频语义忠实度的CLIP-T指标上,VANS同样大幅领先。
这充分证明,通过Joint-GRPO实现的专业化分工与协同优化,有效解决了统一模型在「理解」与「生成」能力上的权衡困境,实现了两者性能的同步飞跃。
同时,在衡量视频质量的FVD指标上,VANS也达到了最低(最好)的分数,证实了其生成视频具有更高的视觉逼真度与流畅性。

定性结果生动地展现了VANS在细粒度语义理解与可视化上的优势。
对于一个烹饪任务——「展示烤帕尔玛奶酪鸡的下一步」,统一模型及级联基线常常产生语义或视觉上的错误。
例如,它们可能错误地预测步骤(如「倒入酱汁」而非「撒芝士」),或即使预测对了「加入芝士」这一动作,在可视化时也可能表现为「倾倒液状芝士」或「放置整片芝士」,与真实烹饪场景中「撒下碎芝士」的细粒度动作不符。
相比之下,团队的VANS模型则成功展现了其精准的推理与对齐能力。
它不仅正确推断出「撒上grated cheese(碎芝士)」这一关键步骤,并且生成的视频精准地呈现了一只手持容器、另一只手进行「撒」这个动作的逼真画面。
这一案例证明,Joint-GRPO成功地将VLM的语义推理与VDM的视觉生成在细粒度动作层面进行了对齐,使得模型不再是生成模糊的「概念视频」,而是精确的「操作指南」。

这项名为Video-as-Answer的研究,将视频生成技术从娱乐的边界推向了更具实用价值的广阔天地。
通过让AI学会「用视频说话」,团队获得了一种更强大、更直观的与机器和知识交互的方式。
下一次当你对下一步感到迷茫时,你收到的答案,或许就是一段为你量身定制的未来。
Project Page:https://video-as-answer.github.io/Github:https://github.com/KlingTeam/VANSarXiv:https://arxiv.org/abs/2511.16669
文章来自于微信公众号 “量子位”,作者 “量子位”



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
