# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
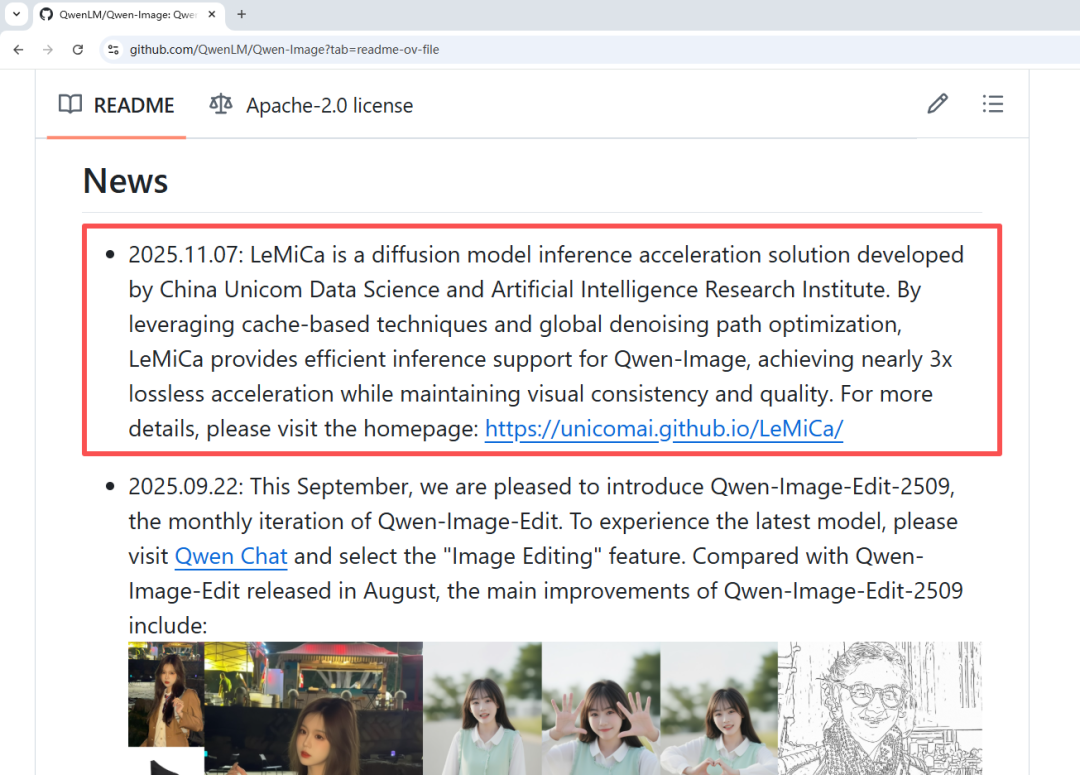
当前,视频生成模型性能正在快速提升,尤其是基于Transformer架构的DiT模型,在视频生成领域的表现已经逐渐接近真实拍摄效果。然而,这些扩散模型也面临一个共同的瓶颈:推理时间长、算力成本高、生成速度难以提升。随着视频生成长度持续增加、分辨率不断提高,这个瓶颈正在成为影响视频创作体验的主要障碍之一。
来自中国联通数据科学与人工智能研究院的研究团队提出了一个全新的思路 :LeMiCa(Lexicographic Minimax Path Caching)——一种无需训练、全局最优建模的缓存加速框架,能在保持画质与一致性的同时,实现高效的推理加速。LeMiCa解决的是一个长期被“局部贪心决策”束缚的老问题:扩散模型是否存在一种真正“全局一致、误差可控、速度极快”的缓存加速路径?研究答案是:有。并且比想象中简单得多。
这项研究已经成功入选 NeurIPS 2025 Spotlight。

论文标题:
LeMiCa: Lexicographic Minimax Path Caching for Efficient Diffusion-Based Video Generation
论文链接:
https://arxiv.org/abs/2511.00090
项目主页:
https://unicomai.github.io/LeMiCa
代码地址:
https://github.com/UnicomAI/LeMiCa
当前主流的缓存加速方法(如TeaCache)采用了“局部贪心”策略:如果相邻时间步之间的变化很小,就选择复用缓存。然而,这种“走一步看一步”的策略忽视了扩散模型的重要特性——早期步骤对生成结果有较高的敏感性,微小的误差可能在后期被不断放大,影响最终画质。同时,许多现有方法需要引入在线判别机制,这会引入额外的计算负担,使得生成过程依然缓慢。
LeMiCa的核心思想是:
“缓存加速并不是局部决策问题,而是一个全局路径优化问题。”
研究团队发现,扩散模型的生成过程其实可以抽象成一个带权有向无环图(DAG) 。每个节点代表一个时间步,每条边代表在两个时间步之间“跳过计算、复用缓存”的行为,边的权重则对应缓存导致的全局误差。这样,缓存策略可以很自然的转化为在DAG中搜索最优路径的问题。
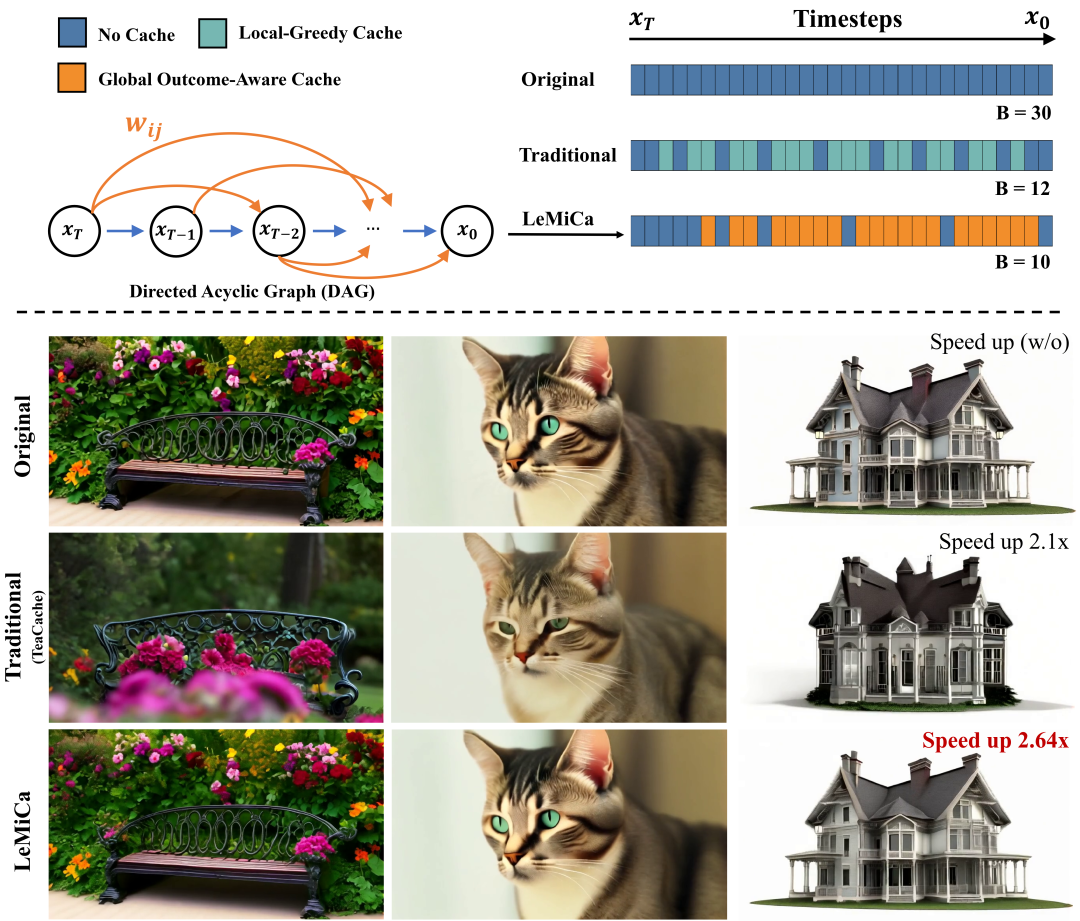
为了准确评估缓存的影响,LeMiCa提出了一种全新的误差度量方法,通过离线构建静态DAG来量化缓存对最终生成视频结果的影响。DAG的构成部分主要有:1)节点:每个时间步;2)边:可能的缓存区间;3)边权重:缓存-复用引发的全局重建误差。具体来说,对于DAG中节点i到j的边权被定义为:


代表了从时间步i 到时间步j 启用缓存复用机制时所带来的全局误差,这个全局误差可以通过加速前后输出图像之间的L1 损失来量化。
在图构建过程中,我们会对每个时间步进行节点抽象。DAG中的每一条边代表在时间步i到j之间跳过若干步计算、直接复用缓存的行为。为避免图过于庞大,LeMiCa依据“距离越长,缓存误差越大”的先验知识,设置了最大跳跃长度,从而只保留合理的缓存段以减少搜索复杂度。最终,为了保证鲁棒性和泛化性,LeMiCa仅使用少量样本(prompt和seed)离线生成多个DAG并进行融合,最终得到一个静态的、跨任务可复用的全局误差图。
字典序极小化路径优化(Lexicographic Minimax Path):在构建好静态误差图之后,LeMiCa 将缓存调度问题形式化为:在固定预算 B 下,从起点到终点寻找一条最优路径。由于传统的“最短路径”或“局部最优”算法不具备线性可加性,导致最短路径算法不再适用,LeMiCa采用了字典序极小化准则来进行路径搜索。这种优化方式不追求误差总和最小,而是逐层比较路径中各段缓存的误差值,确保:

通过字典序比较,LeMiCa避免了“看似整体误差低但中间崩坏”的路径:
若路径A的最大误差 < 路径B的最大误差 → A 更优
若最大误差相同 → 比较第二大依次类推
联通元景大模型研究团队在多个主流视频生成模型中验证了LeMiCa的性能。从结果中可以看到该方法在保留加速前后的视觉一致性具有显著优势,这也正是全局路径视角下的图优化所带来的增益。
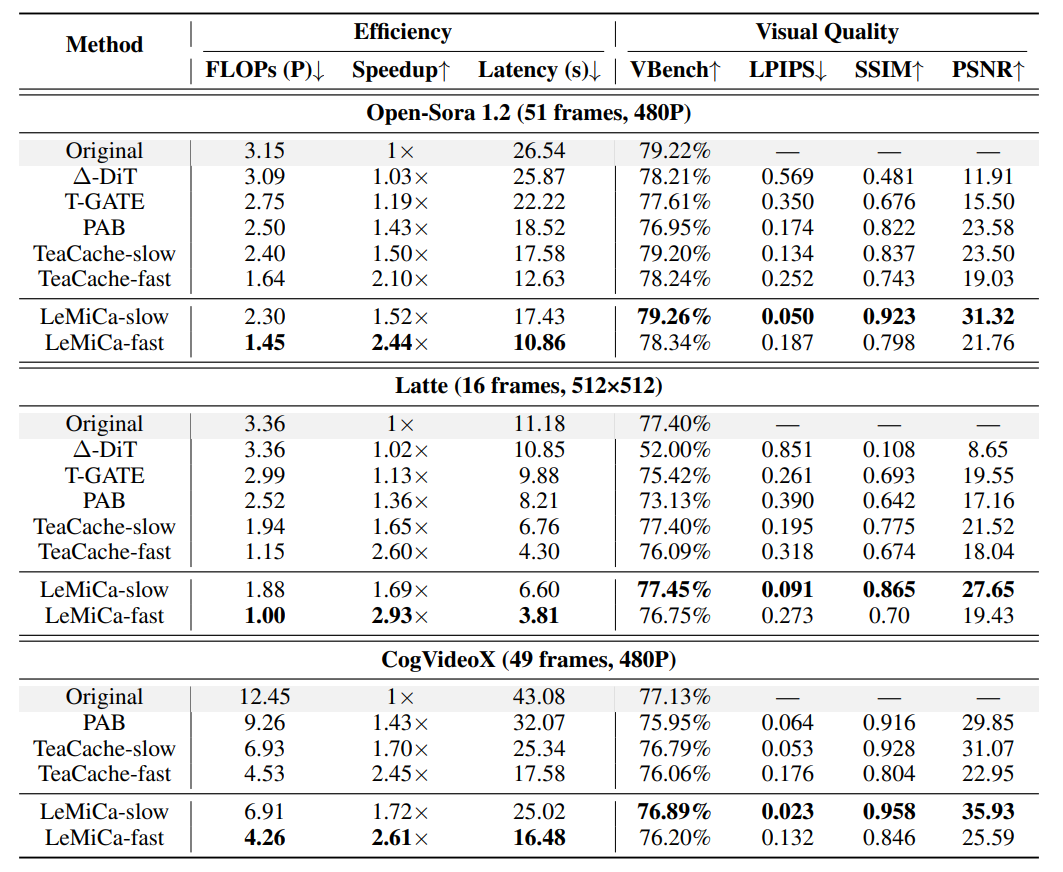
从视觉效果上看,LeMiCa生成的视频在结构风格保持、内容一致性方面都显著提升。

即使在高倍加速推理下,也几乎看不出明显退化。

从结果中可以看出,LeMiCa对比其他主流方法,存在以下明显优势:
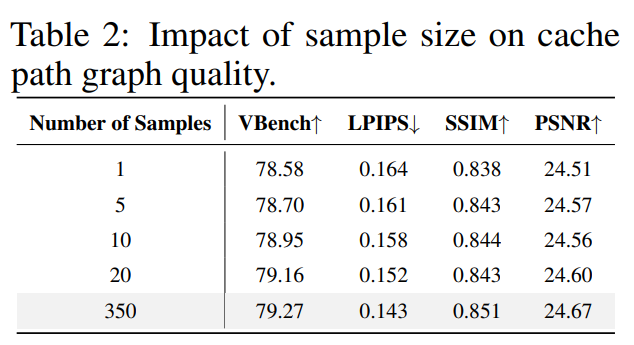
极少样本建立DAG:LeMiCa仅凭少量样本即可构建高质量缓存路径,单样本已具强性能,20个样本即达到性能饱和,体现了静态缓存策略的高效与稳健。
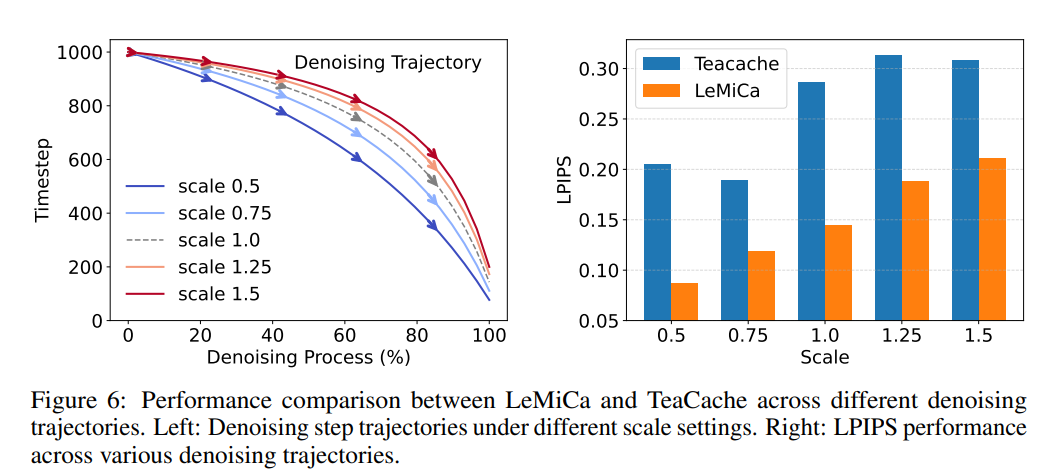
加速路径的鲁棒性:即使改变采样调度中的轨迹缩放参数得到不同的去噪轨迹,LeMiCa仍有较好的效果,体现了良好的路径鲁棒性。
文生图模型兼容:由于LeMiCa本质上是一个用于扩散模型缓存加速的框架,因此其也适用于文生图模型。我们拿最新的QWen-Image模型进行了实验,得到了同样出色的加速效果:

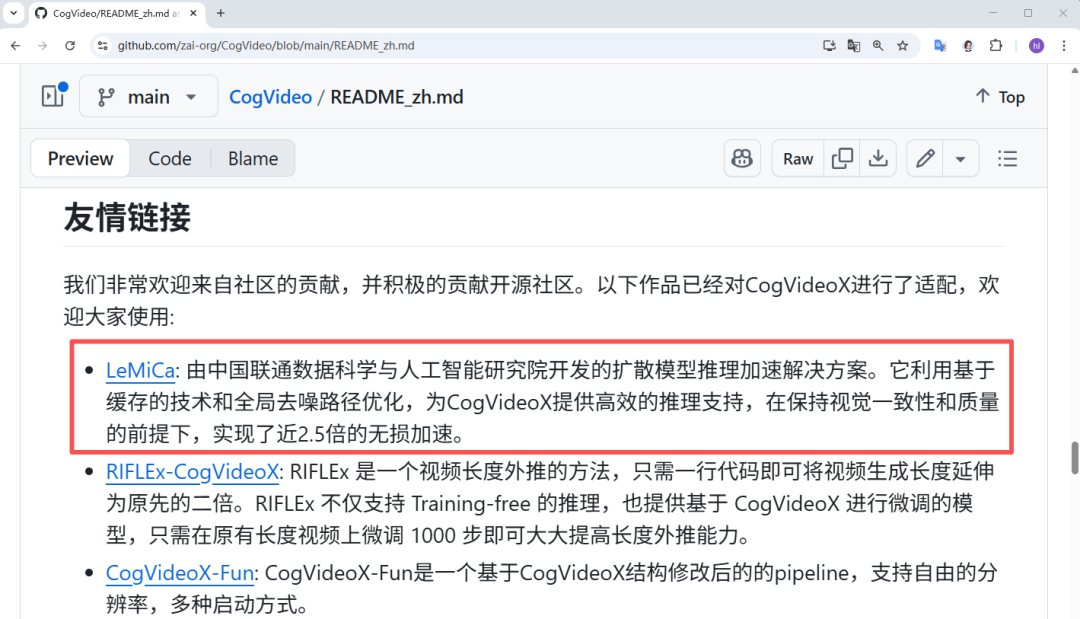
LeMiCa得到了顶级多模态模型研发团队阿里通义千问和智谱AI的认可,分别在其官方主页上对LeMiCa进行权威推荐!
LeMiCa以全局优化视角重新定义了扩散视频生成的加速问题。它突破了传统“局部贪心”式缓存策略的局限,将缓存调度建模为有向无环图(DAG)上的全局路径搜索问题。作为一种通用的免训练加速框架,LeMiCa为视频生成带来了“又快又稳”的新范式,联通元景大模型团队希望以此为基石,为业界关于扩散模型的加速和复杂场景生成提供新的思考角度。
文章来自于“机器之心”,作者 “高焕霖和陈平”。



【开源免费】kimi-free-api是一个提供长文本大模型逆向API的开渔免费技术。它支持高速流式输出、智能体对话、联网搜索、长文档解读、图像OCR、多轮对话,零配置部署,多路token支持,自动清理会话痕迹等原大模型支持的相关功能。
项目地址:https://github.com/LLM-Red-Team/kimi-free-api?tab=readme-ov-file
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
