# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
终于有人要给大模型安“脖子”了!
在最新的论文Thinking in 360°: Humanoid Visual Search in the Wild中,来自纽约大学的研究团队让大模型能够环顾四周,进行360度的全方位思考。

他们通过定义一套全新的数据集和基础测试H*,让模型可以在火车站、购物中心等真实环境中,进行像人类一样的视觉搜索。

谢赛宁(也参与了这篇论文)在转发中,直接表示:这不就是给模型安了个脖子吗?

这是怎么回事?
整体而言,研究团队首先提出了一项在360度空间中实现人类主动空间推理的新任务——
类人视觉搜索(Humanoid Visual Search),这项任务能让类人智能体在全景图像构建的沉浸式环境中,通过自主旋转头部搜索目标物体或路径。
为进一步评估智能体在视觉拥挤的真实场景中的搜索能力,研究团队还构建了全新的针对性基准测试 ——H*Bench。
这一基准突破了传统测试多聚焦简单家庭场景的局限,涵盖交通枢纽、大型零售场所、城市街道、公共机构等真实世界复杂环境,对智能体的高级视觉 -空间推理能力提出了更严苛的考验。
该研究的推进,为视觉空间推理从 “脱离身体的被动范式” 向 “具身的主动范式” 转型奠定了重要基础。
接下来,我们具体来看。
在论文的开头,研究提出了一个非常直觉的问题——如何开发出既能像人类一样高效,又能绕过硬件限制在复杂现实场景中进行主动视觉搜索的具身智能体?
众所周知,相比于脑袋、手腕、身体各处“长眼”的机器人,人类仅凭转动脖子和眼睛,就能高效地搜索360°范围内的视觉信息,从而完成视觉搜索任务(比如在地铁站中寻找下一个出口)。

而现在的大模型,不但只能处理单张、静态、低分辨率的图像,而且在后续的操作中,也局限于将图像放大、裁剪的计算操作。
这就意味着与生物视觉相比,大模型既无法改变初始视角以获取视野以外的信息,同时也由于缺乏物理实体,不能移步换景,将视觉推理和物理行动结合起来。
基于此,研究提出了类人视觉搜索(Humanoid Visual Search,HVS)将主动的头部转动融入智能体在复杂环境中的视觉推理,其具备以下特性:
具体地,类人视觉搜索进一步将研究聚焦于以下两类搜索问题:
类人物体搜索(Humanoid Object Search,HOS):定位并将视线聚焦于目标物体,作为操作的先决条件。在基准中,难度根据初始可见度比率分为简单、中等和困难三个等级。

类人路径搜索(Humanoid Path Search,HPS):识别通往目的地的可通行路径并调整身体朝向,作为移动的先决条件。在基准中,难度分为四个级别,由场景中文本线索的存在以及视觉/文本线索与实际路径方向的一致性决定。

为了将搜索问题形式化,研究将其构建为一个多模态的推理任务。
简单来说,多模态大模型通过一个策略网络来实现工具使用与头部旋转,其将时间步、当前观测、语言指令和历史状态作为输入,输出文本思维链和动作。
值得一提的是,由于人类的推理是间歇性的,仅在关键决策点才会被调用,所以研究仅利用在决策点采集的单个360°全景图构建闭环搜索环境,而无需使用3D模拟器或硬件。
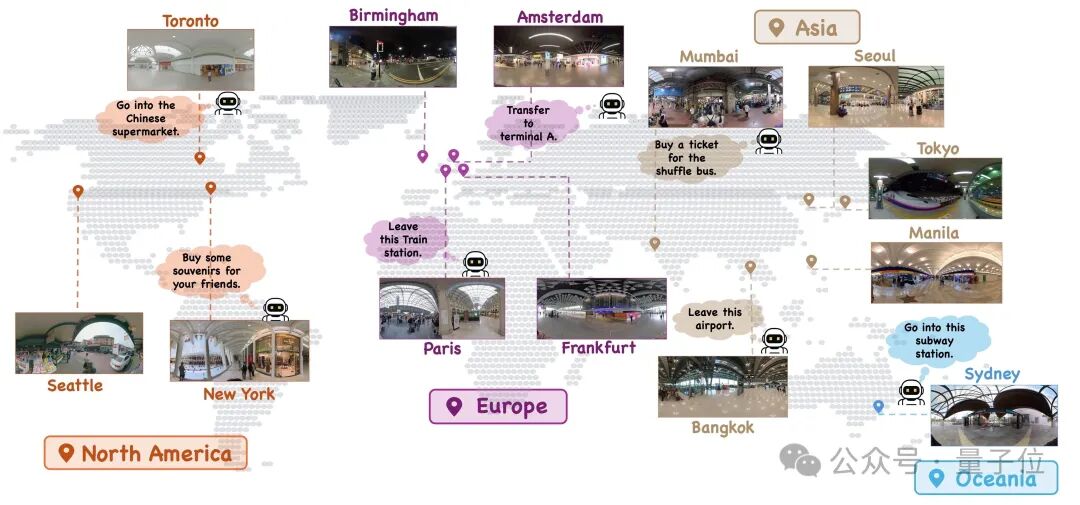
知道了找什么,去哪,和怎么走之后,为了找到最佳的测试环境,研究又构建了一个数据集、基准测试和基线——H*,旨在实现真实360度环境中类人的视觉搜索。

具体来说,H包含约3000个带标注的任务实例,这些实例来源于多样化的高分辨率全景视频。
研究通过为每个任务实例设置四个不同的起始方向来初始化智能体,总共获得了12000个搜索回合。
H*Bench 的数据来源于全球大都市地区(纽约、巴黎、阿姆斯特丹、法兰克福)自行采集的素材以及开放平台(YouTube和360+x数据集),从而提供了广泛的地理覆盖范围。

具体的场景主要包含6个主要类别——零售环境、交通枢纽、城市街道、公共机构、办公室和娱乐场所。

此外,由于多模态大模型是在静态、非具身的互联网数据上训练的,它们本质上缺乏拟人化视觉搜索所需的空间常识和主动 3D 规划能力。

因此,研究又通过上面pipeline将多模态大模型转化为有效的视觉搜索智能体:
在部署环节,研究基于Qwen2.5-VL-3B-Instruct模型展开上述pipeline,
测试表明,经训练后,Qwen2.5-VL-3B-Instruc在目标搜索(14.83%→47.38%)和路径搜索(6.44%→24.94%)上的搜索准确率均有所提高。

其中,路径搜索的上限较低,表明其难度在于需要复杂的空间常识。
而在其他多模态大模型的测试中, 谷歌的Gemini 2.5 Pro是整体表现最强的模型,在HOS任务中达到31.96%,在HPS任务中达到33%。
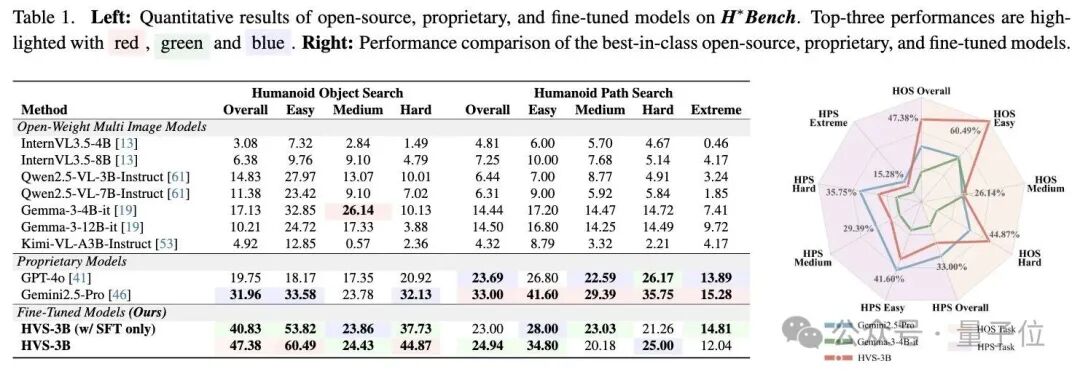
此外,研究发现,更大的模型尺寸并不一定能保证更好的性能。
无论是Gemma-3还是Qwen2.5-VL系列,较小的4B/3B模型在HOS任务中均超越了其较大的12B/7B对应模型,并在 HPS 任务中表现持平。
通过分析错误类型,研究发现
总的来说,研究通过引入H*Bench基准和利用后训练技术,探讨了由 MLLM 驱动的in wild类人视觉搜索。
研究表明尽管后训练能够有效地提高低级感知-运动能力(例如视觉定位和探索),但它也暴露了高级推理方面的根本瓶颈,这些推理需要物理、空间和社会常识。
这篇研究出自纽约大学的李一鸣团队,在推文中,他感谢了谢赛宁和chen feng的指导。

李一鸣目前在英伟达就职,担任研究科学家,与Marco Pavone教授合作,研究物理人工智能和自动驾驶。

他于2025年在纽约大学取得博士学位,师从chen feng教授,研究机器人感知。
值得一提的是,在他的简介中,他还表明自己将于2026年入职清华大学人工智能学院,担任助理教授。

参考链接
[1]https://yimingli-page.github.io/
[2]https://x.com/YimingLi9702/status/1993676992303268142
[3]https://x.com/sainingxie/status/1993776740154610084?s=20
[4]https://arxiv.org/pdf/2511.20351
文章来自于“量子位”,作者 “henry”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
