# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Context Pruning如何结合rerank,优化RAG上下文?
现如今,LLM的上下文窗口长度正在经历爆发式增长。
翻开LLM Leaderboard,可以发现顶级模型的上下文长度已经陆续突破了1M tokens,并且这个数字还在不断刷新。
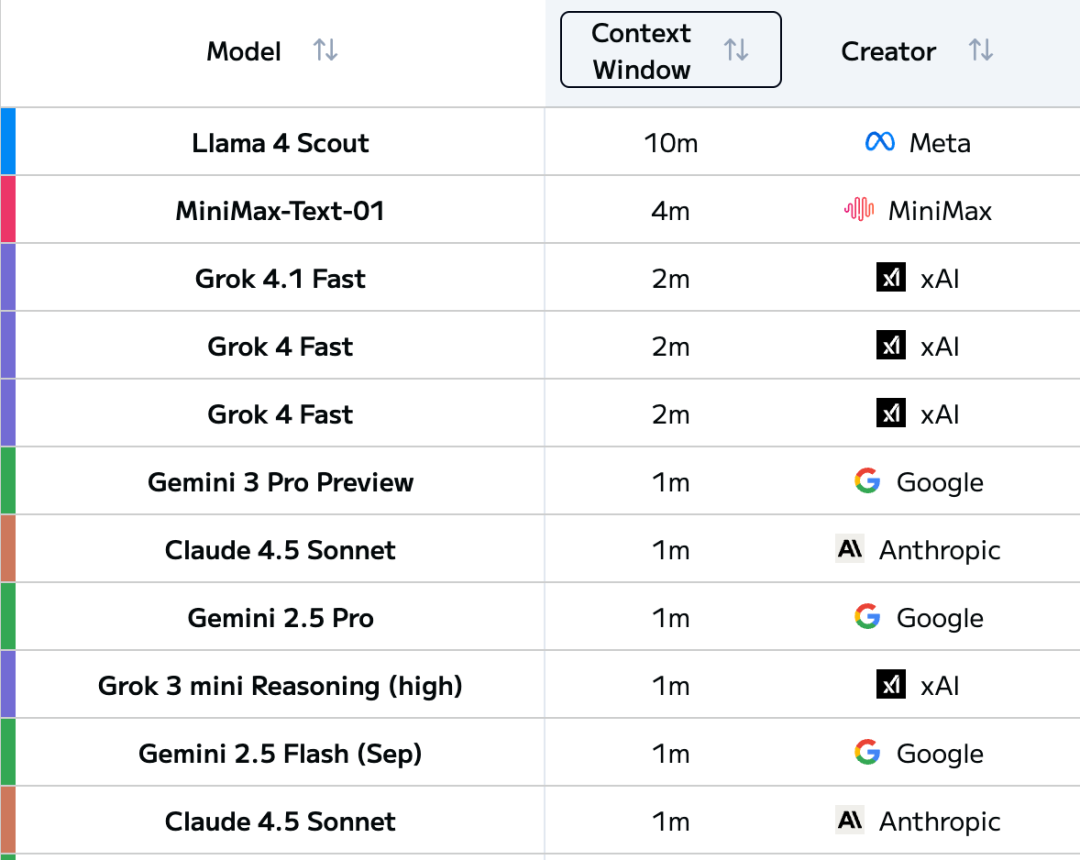
但问题也随之而来:模型能够支持长上下文,那我们就能随心所欲往里面塞内容,输入越多,模型输出效果越好吗?
答案当然是否定的。
毕竟,往模型里塞进一百万个tokens,可能不仅大部分信息都没有用,导致浪费计算资源,还可能干扰模型的判断,导致生成质量下降。
如何精细化地管理和优化这些海量上下文,已经成为Context Engineering(上下文工程) 要解决的核心问题。
那么长上下文在什么情况下会出问题?针对长上下文导致的模型输出崩溃,我们有什么解决方案?本文将对此进行探讨。
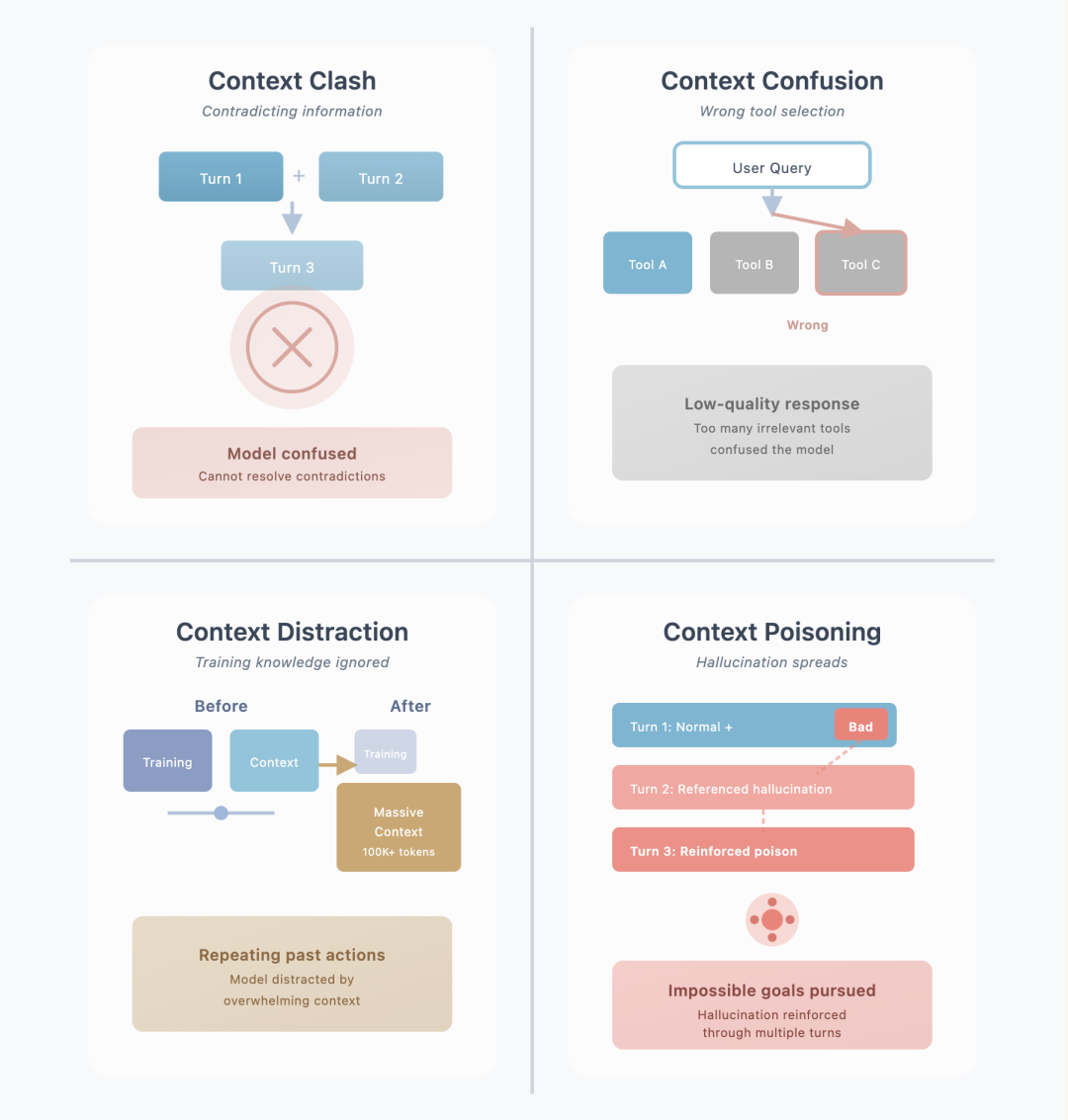
业界已经总结出了四种常见的长上下文失效的模式:
1. Context Clash(上下文冲突)
多轮对话中累积的信息相互矛盾。就像早上说"我喜欢苹果",中午说"我不喜欢水果",模型会confused:你到底喜不喜欢苹果?
2. Context Confusion(上下文混淆)
上下文中无关信息过多,导致模型在工具调用时选错。类似工具箱里塞满了各种工具,找个螺丝刀反而眼花缭乱。
3. Context Distraction(上下文分心)
海量上下文信息压制了模型的训练知识。就像桌上的教科书被一米高的漫画堆淹没,学生注意力全被吸引走了。
4. Context Poisoning(上下文中毒)
错误信息在多轮对话中不断被引用和强化。第一次说错一个事实,后续对话又基于这个错误继续编造,越走越偏。
针对这些长上下文问题,主要有六种管理策略:RAG(检索增强生成)、Tool Loadout(工具装载)、Context Quarantine(上下文隔离)、Context Pruning(上下文剪枝)、Context Summarization(上下文摘要)、Context Offloading(上下文卸载)。
在这些策略中,Context Pruning尤其关键,因为它直接作用于信息输入环节。
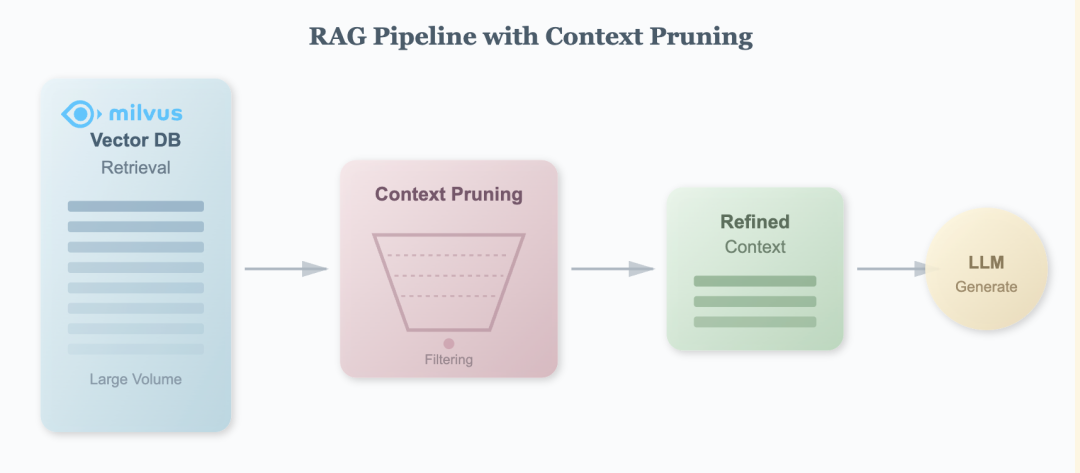
在RAG系统里,我们从向量数据库检索回来大量文档,其中大部分是无效或者低相关度信息。而Context Pruning就是要在检索之后、生成之前,精准地过滤掉无关内容。从而带来生成质量提升、计算成本降低、上下文窗口利用率更高。
也是因此,Context Pruning质量,往往会成为RAG优化的核心环节。
研究Context Pruning的时候,我发现了两个有意思的宝藏开源模型:Provence和XProvence,来自Naver AI Lab的工作。

Provence的核心功能很简单:给它一个问题和一段检索回来的文档,它会帮你筛选出真正相关的句子,把无关的内容过滤掉。
这样既加快了LLM生成速度,又减少了噪声干扰。而且它是即插即用的,可以配合任何LLM或检索系统使用。
Provence有几个让我印象深刻的特点。
第一是它会整体理解文档。不像有些方法单独看每个句子,Provence会把所有句子放在一起看。
这很重要,因为文档里经常有"它""这个"这样的指代词,单独看一句话可能不知道在说什么,但放在上下文里就清楚了。这样可以显著提高剪枝的准确性。
第二是它会自己判断该留几句话。不需要你告诉它"给我留5句话"或"留10句话",它会根据具体情况决定。有些问题可能一句话就够了,有些可能需要好几句,Provence都能自动处理。
第三是效率很高。一方面它是个轻量级模型,比调用大型LLM快多了;另一方面它把剪枝和重排序(Reranking)合在一起做了,基本不增加额外成本。
第四是它有跨语言版本。XProvence是Provence的跨语言版本,它是另外单独训练的一个模型,支持多种语言,包括中文、英文、韩文等。训练模式大致和Provence一样,只是数据集不同。
实现上,Provence采用了比较巧妙的设计。它的输入很简单:把问题和文档拼起来,一起送进模型。这种 Cross-Encoder 架构,让模型能同时看到问题和文档的全貌,理解它们之间的关联。
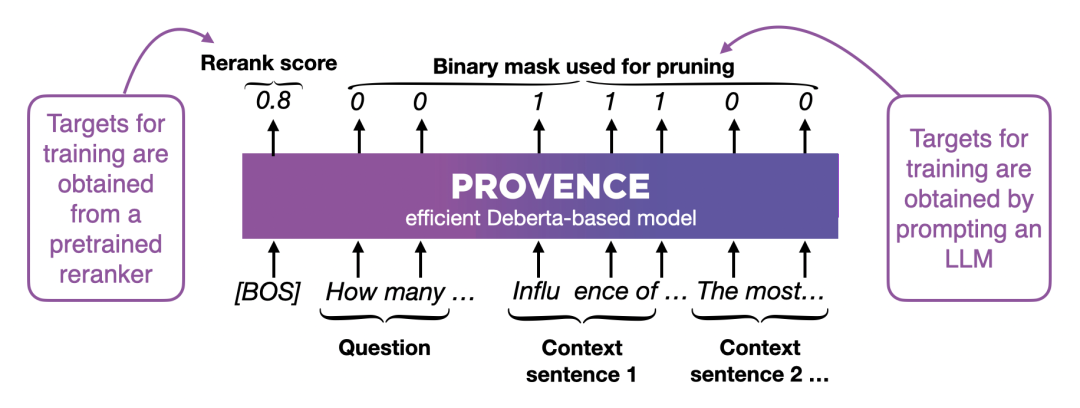
此外,Provence是基于DeBERTa训练微调的,作为一个轻量级的Encoder模型,训练时它同可以时做两件事:
1. 给整个文档打分(Rerank score)- 判断这段文档和问题的相关程度,比如0.8分表示相关度很高
2. 给每个词打标签(Binary mask)- 用0和1标记每个词是否相关,1表示相关要保留,0表示无关可以删掉
这样训练出来的模型,既能判断文档相关性,又能精准地做句子剪枝:推理时,Provence会给每个词打分,然后按句子聚合:如果一个句子里标记为1(相关)的词比标记为0(无关)的词多,就保留这个句子,否则就删掉。通过调整阈值,就能控制剪枝的激进程度。
最重要的是,Provence复用了重排序的能力,所以在RAG流程中几乎是零成本加入的。
前面我们介绍了Provence的设计原理和技术特点,那么它在实际应用中的表现如何?与其他模型相比有何优劣?为了回答这些问题,我们设计了一套完整的定量评估实验,对比其他模型在真实场景下的剪枝质量。
实验有两个核心目标:
1.定量评估Context Pruning的效果:通过标准指标(Precision、Recall、F1)量化模型的剪枝质量
2.测试域外泛化能力(Out-of-Domain):评估模型在与训练数据分布不同的场景下的鲁棒性
为此,我们选择了三个代表性的模型进行对比:
naver/provence-reranker-debertav3-v1)naver/XProvence)opensearch-project/opensearch-semantic-highlighter-v1),同样基于BERT架构训练的剪枝模型数据集选择:我们选择WikiText-2作为测试集。这是一个基于维基百科文章的数据集,文章结构多样,答案往往分散在多个句子中,语义关联也比较复杂。
更重要的是,它与模型通常的训练数据存在较大的分布差异,同时又很接近日常业务场景——这正是我们想要的out-of-domain测试环境。
问题生成与标注:为了确保out-of-domain的效果,我们使用GPT-4o-mini从WikiText-2原始语料中自动生成问答对。每个样本包含三个部分:
这种构造方式天然形成了一个Context Pruning任务:模型需要根据问题,从完整文档中识别出真正相关的句子。答案句子作为"正样本"(应保留),其他句子作为"负样本"(应剪枝),这样我们就可以通过Precision、Recall、F1等指标量化评估模型的剪枝准确性。
更重要的是,这样生成的问题不会出现在任何模型的训练数据中,能够真实反映模型的泛化能力。我们一共生成了300个样本,涵盖简单事实类、多跳推理类、复杂分析类等不同类型的问题,尽可能贴近实际应用场景。
实验流程:
参数优化:使用Grid Search对每个模型进行超参数优化。测试不同的超参数组合,最终选择F1最优的配置。
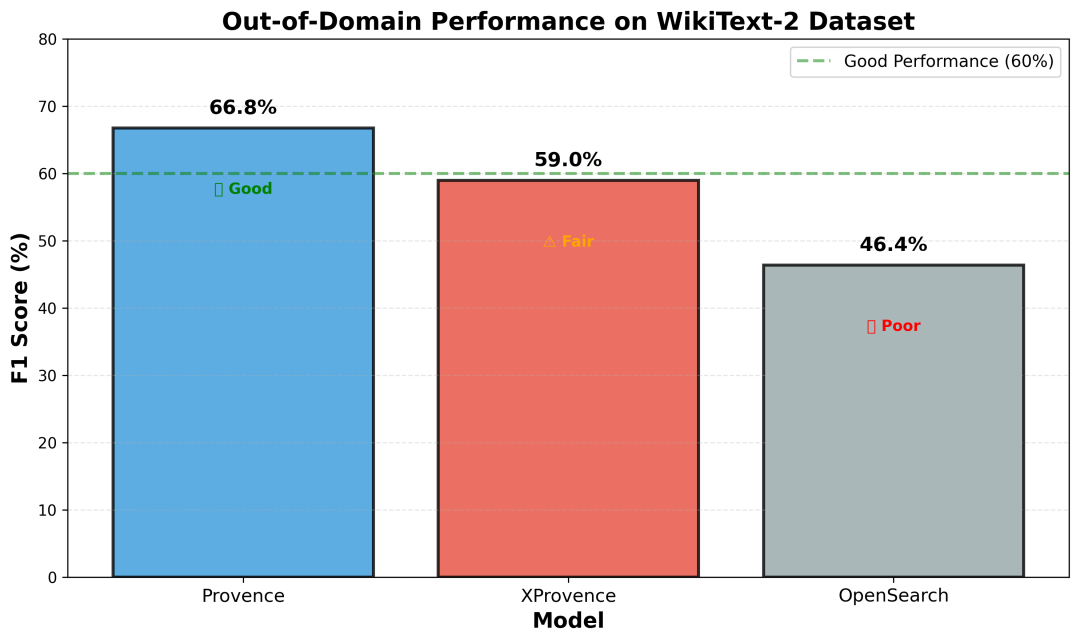
从实验结果来看,三个模型的表现存在明显差异。
Provence表现最好,F1达到66.76%。Precision(69.53%)和Recall(64.19%)相对平衡,显示出良好的域外泛化能力。最优参数为threshold=0.6,alpha=0.051,说明模型输出的分数分布较为合理,阈值设置也相对直观。
XProvence的F1为58.97%,略微有些高召回(75.52%)、低精确度(48.37%)的特征。这种"宁可错选不可漏选"的策略在某些场景下具有优势,比如医疗、法律等对信息完整性要求高的领域。但同时也会引入更多的误判,降低精确度。好在XProvence支持多语言,它可以弥补Provence在除了英文以外场景的不足。
OpenSearch的F1为46.37%(Precision 62.35%,Recall 36.98%),在三个模型中相对较弱,显著低于Provence和XProvence,说明在out-of-domain场景下,模型输出的分数校准和泛化能力还有提升空间。
顺带提一下,Context Pruning与一个新兴的搜索系统功能——Semantic Highlight(语义高亮),他们在技术本质上是同一件事。
可能说到Highlight,大家可能更熟悉Elasticsearch里的传统Highlight功能——它基于关键词匹配,用<em>标签高亮查询词出现的位置。但这种方式很机械,只能匹配字面相同的词。
而Semantic Highlight则完全不同,它基于语义理解,通过深度学习模型判断文本片段与查询的语义相关性,即使没有相同关键词也能准确识别相关内容。
仔细想想,Context Pruning与Semantic Highlight的本质都是:
基于query和context的语义匹配,找出最相关的部分,排除掉不相关的部分。

因此,它们本质上是同一个技术在不同场景下的应用。
这意味着同一个模型可以服务多个场景,提高了技术的可复用性。
而伴随着Semantic Highlight逐渐成为一个新兴的功能需求,Milvus团队正在规划内置Semantic Highlight功能。
目前当Milvus提供向量检索时,用户反馈检索返回大量chunk后,难以快速识别哪些句子真正有用。而借助提供基于模型的Semantic Highlight功能,能够与向量检索pipeline无缝融合。
这样Milvus将演进为集成检索、重排序、上下文剪枝的智能检索归因平台,覆盖RAG优化、搜索高亮、文档摘要等多个场景。
Context Engineering作为一个新兴方向,还有很多探索空间。
无论是在算法优化、跨领域泛化,还是在与RAG pipeline的更深度整合方面,都值得进一步研究。Milvus团队也会持续关注这个方向,并提供相应的功能支持。
相关链接:
作者介绍

张晨
Zilliz Algorithm Engineer
文章来自于“Zilliz”,作者 “张晨”。



【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
