# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在大语言模型(LLM)的研究浪潮中,绝大多数工作都聚焦于优化模型的输出分布 —— 扩大模型规模、强化分布学习、优化奖励信号…… 然而,如何将这些输出分布真正转化为高质量的生成结果 —— 即解码(decoding)阶段,却没有得到足够的重视。
北京大学林宙辰、王奕森团队的论文《Language Ranker: A Lightweight Ranking Framework for LLM Decoding》提出了一种全新的视角:将大模型的解码过程类比为推荐系统中的排序阶段(Ranking Stage)。这一视角揭示了现有解码方法的局限,并据此提出了高效、轻量的改进方案。

论文指出,LLM 可以被看作一种特殊的推荐系统,它把输入当作 “用户信息”,在庞大的候选响应空间中为每位用户挑选最合适的响应。
如下图所示,大模型的关键组件与推荐系统可一一对应:

图表 1 大模型的关键组件与推荐系统一一对应
通过将大模型的解码过程类比为推荐系统的排序阶段,我们能够更清晰地看到现有方法的局限。
在推荐系统中,排序层(Ranker)通常经过精心设计,结构复杂,用于在召回的候选项中进行细粒度优化;而在大模型中,主流的解码方法,如贪婪解码、束搜索(Beam Search)、自一致性(Self-consistency)等,大多仅依赖固定规则,缺乏学习能力,因而要么提升有限,要么只在少数任务(如数学问题)中有效。
与此同时,基于奖励模型的重排序方法虽然具备一定的学习能力,却存在明显的冗余。它们在排序阶段重新进行特征提取,相当于 “重复做了一遍特征工程”。这种重复造轮子的做法不仅计算成本高昂,而且在训练与推理中都带来巨大的资源浪费,严重限制了大模型在解码优化方向上的可扩展性与普适性。
针对上述局限,论文借鉴推荐系统的设计思路,提出了 Language Ranker 框架。其核心思想是:不再依赖庞大的奖励模型(Reward Model),而是直接复用主模型已提取的隐藏层特征,通过一个极小的学习模块完成候选响应的重排序。
该模块仅包含不到 0.5M 参数(比 GPT-2 还小 200 多倍),却在数学推理、代码生成、函数调用等多项任务上取得了接近甚至超越 7B 级奖励模型的性能。
如下图所示,Language Ranker 包含三步:
1. 候选召回:由主模型生成多条候选响应;
2. 特征提取:从模型中部(约底部 60% 层)提取最后一个 token 的隐藏状态,作为表示特征;
3. 候选排序:基于提取的特征,通过轻量 Transformer 或 MLP 计算相关性进行重排序。

图表 2 Language Ranker 框架
实验发现,这种 “共享特征工程” 的设计避免了传统奖励模型重复特征提取浪费,在保持高性能的同时,大幅降低了计算成本,实现了以最小代价获得接近最优结果。
此外,Language Ranker 还具备以下特性:
这些优势使得一个主模型可以灵活搭配多个 Ranker,甚至为不同用户定制个性化 Ranker,实现真正的个性化能力增强。

图表 3 一个 LLM 可以配备任意个 ranker,从而增强模型不同方面的能力,实现个性化
1. 主结果:不到 0.5 M 参数的 Ranker 媲美大规模奖励模型
在所有任务中,Language Ranker 仅需不到 0.5 M 参数,就能达到甚至超过大规模奖励模型(Reward Model)表现。例如:

图表 4 Language Ranker 在数学、代码、工具调用任务上的表现
2. 速度与资源效率:CPU 也能训练的 Ranker
在 MBPP 任务上,Language Ranker 即使用 CPU 也仅需 67 秒即可训练完成,而即使是 GPT-2 级别的奖励模型也需要超过 1 小时。
Ranker 具备 CPU 可训练性,意味着它可以在边缘设备上独立更新,支持个性化的持续学习。
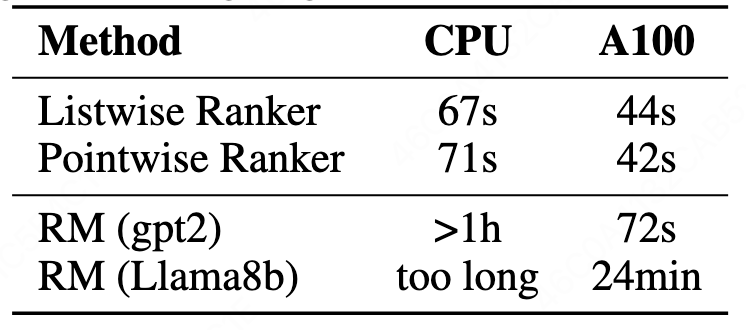
图表 5 CPU 可训练
3. 迁移泛化:跨任务与跨模型皆可适配
单个 Ranker 即可跨任务工作,显著降低模型管理与部署成本。此外,一个主模型还可以配备多个 Ranker,展现出方法突出的覆盖性与灵活性。
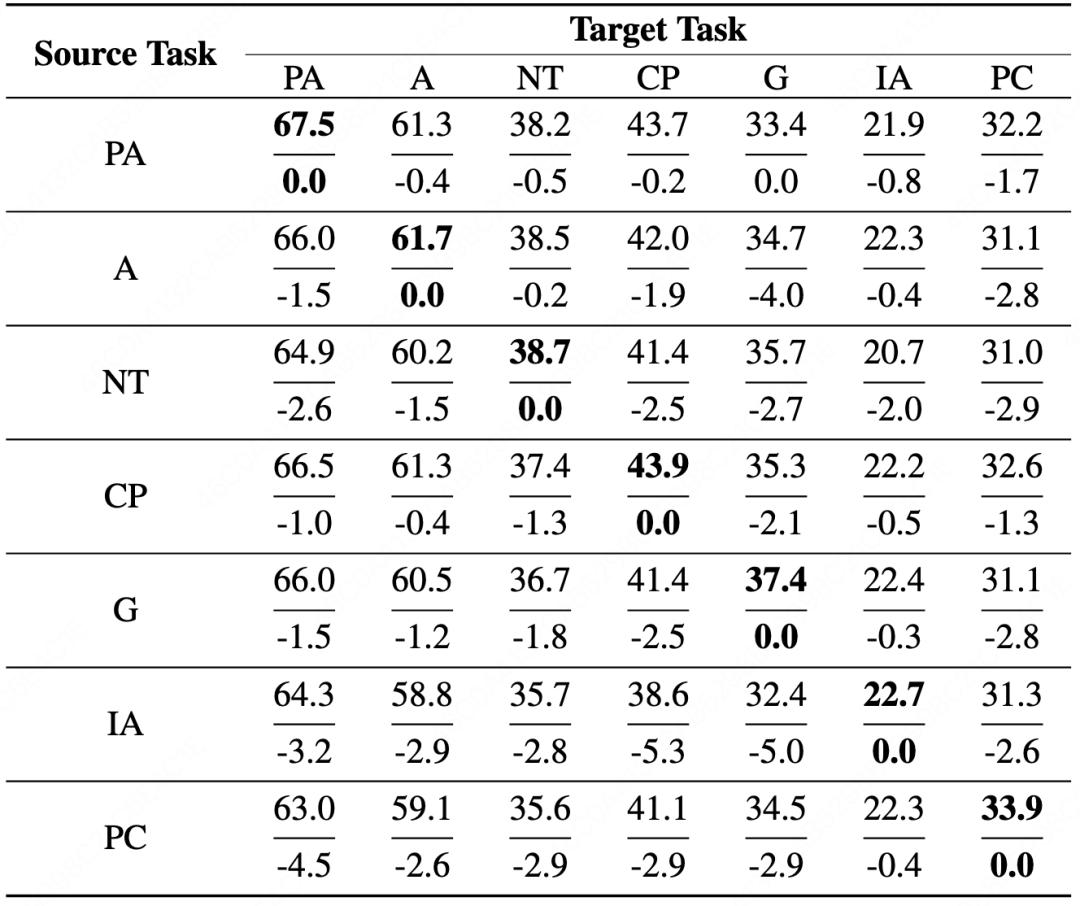
图表 6 跨领域泛化性分析

图表 7 跨任务泛化性分析
4.Ranker Scaling Law:采样越多,性能越强

图表 8 Ranker Scaling Law
随着候选响应数量从 1 增加至 100,Language Ranker 在三项任务上均持续提升:
这展现出本文方法同样遵循规模定律,称之为 Ranker Scaling Law,即更多采样可带来稳定性能增益。
Language Ranker 以 “推荐系统视角” 重新定义了大语言模型的解码过程,提出了一种轻量、高效且通用的排序框架。它摒弃了传统奖励模型高昂的计算代价,通过共享主模型的隐藏层特征,仅以不到 0.5M 参数实现与数千倍规模奖励模型相当的性能。该方法无需额外训练主模型,也能在 CPU 上快速完成学习,显著降低推理与部署门槛。实验结果显示,Language Ranker 在数学、代码生成、函数调用和指令跟随等多任务中均取得优异表现,并在跨任务、跨模型迁移中保持稳定泛化能力。更重要的是,这一框架天然支持个性化扩展:同一主模型可搭配不同 Ranker,以满足多样化场景需求。展望未来,Language Ranker 不仅是解码阶段优化的新范式,更是迈向个性化智能体的重要一步。它让我们看到,大模型的智能边界不止于参数规模,更在于如何高效地 “选出” 最优答案,为构建高效、灵活、可持续演化的语言智能系统提供了新的方向。
文章来自于“机器之心”,作者 “机器之心”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
