# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在当前的情感计算研究中,存在一个显著的“断层”:我们拥有越来越精准的情感识别算法(输入端),也有了逼真的语音和面部生成技术(输出端),但连接这两端的“中间层”却鲜有人问津。机器能识别出你在愤怒,也能模拟出抱歉的语气,但它真的理解愤怒的起因吗?它能基于这种理解去调整后续的决策逻辑吗?

这正是情感认知(Affective Cognition)所要解决的核心问题,也是构建具备情感心智理论(Affective Theory of Mind)的关键所在。缺失了这一环,所谓的“情感AI”不过是基于规则的条件反射。

伊朗科技大学与新加坡南洋理工大学最新发表的综述论文《具备情感的智能体:当前趋势、挑战与未来展望》,敏锐地捕捉到了这一痛点。研究者们并未止步于传统的情感识别综述,而是深入探讨了情感诱发(Elicitation)与情感体验(Experience)的计算模型。详细拆解了如何利用认知评估理论(Appraisal Theories)和强化学习,让智能体在内部构建情感状态,并以此驱动决策、学习与推理。这篇论文为我们补上了人工情感智能版图中至关重要、却长期被忽视的一块拼图。
研究者把Agent的“情感”拆成互相衔接的三项能力:

相信您看完这篇深入的解读,会对如何构建一个“情感”的Agent有全新的认识。
情感理解是智能体与世界交互的入口。传统的单模态识别(仅看脸或仅听音)已经难以满足复杂场景的需求研究者把“情感识别”定义为:多源数据中识别具体情绪状态(脸部表情、声音语调、语言文字、生理信号等),它对 HCI、心理健康监测等很关键。 具体讲了四类输入:
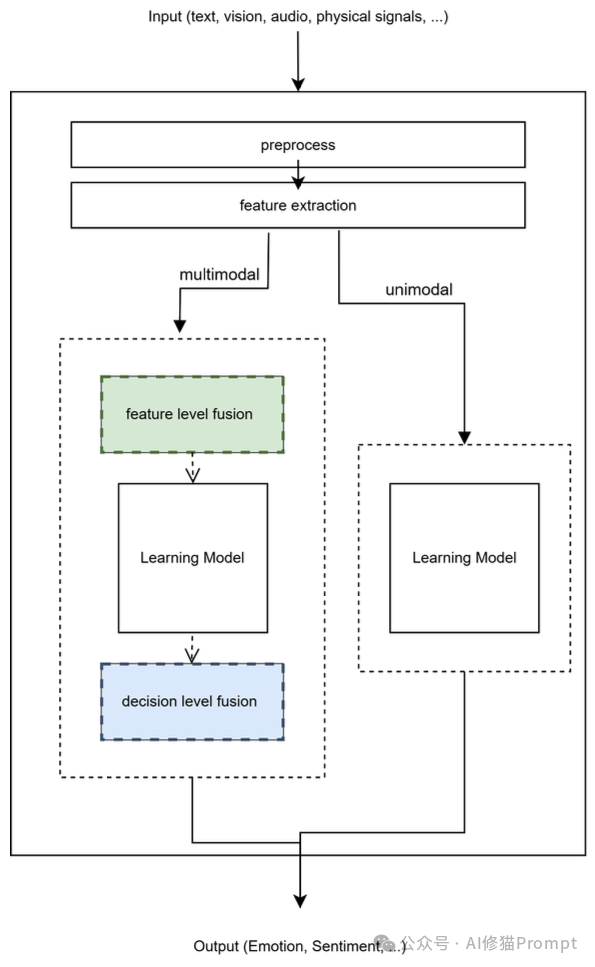
情感识别总体框架图:技术实施流程
如何将不同来源的数据“捏”在一起?这不仅仅是拼接向量那么简单,研究者们面临着巨大的模态鸿沟 (Modality Gap)。例如,面部表情可能提供清晰的视觉线索,但声音的语调可能包含更微妙的情绪,且两者的特征分布和时间步长完全不同。
论文总结了当前主流的融合策略:
情感计算还包括生理信号(如脑电图EEG、心率、皮肤电反应)作为最难以伪装的真实情感反应,在情感理解中扮演着独特角色。
关于构建感知模型,研究者们总结了三大类挑战:
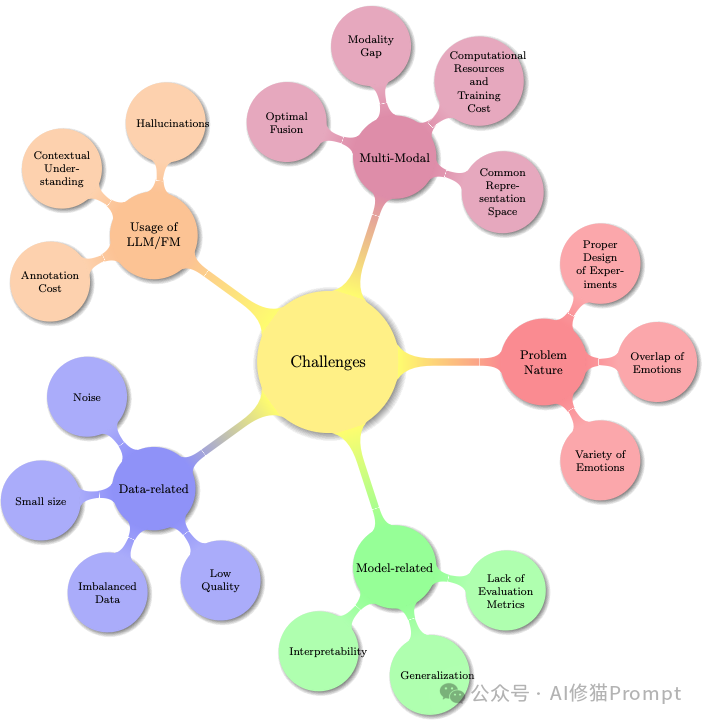
A.数据层面的挑战:
B.模型层面的挑战:
C.问题本身的复杂性:
D.LLM/基础模型引入的新问题:
这部分是整篇论文最“像人类心理过程”的地方:研究者认为仅做情绪识别还不够,真正的“情感”还需要推理情绪的因果与意义,并让情绪进入决策、学习、推理。
研究者提出“情感理论心智(Affective Theory of Mind)”:不仅识别情绪,还要能对情绪进行社会化推理并做出合适回应;而要实现它,需要把“认知 Theory of Mind”和“情感 Theory of Mind”结合。
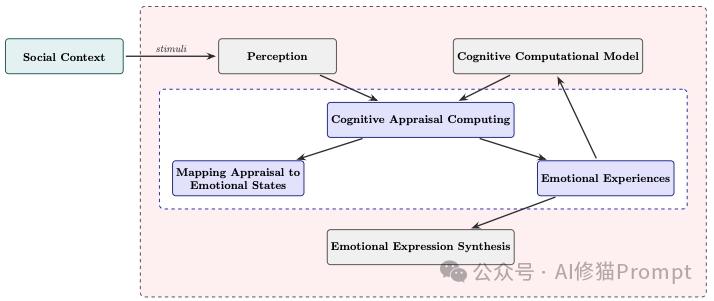
情感认知智能体框图:展示了智能体内部处理情感的逻辑流
他们把affective cognition拆成两个关键步骤:
情绪是如何产生的?论文引入了心理学中的认知评估理论 (Cognitive Appraisal Theory)。情绪是对环境事件的主观评估结果,而非简单的条件反射。
为了实现这一点,研究者们提出了多种计算认知模型:
有了情绪之后,智能体该怎么做?这就是情绪体验建模。
这一领域的最大挑战在于可扩展性和评估标准。

现有的模型往往局限于特定场景(如游戏或治疗),缺乏通用的评估指标来衡量智能体的情感反应是否“社会可接受”。
当智能体理解了情感并做出了决策,最后一步就是通过文本、语音和面部表情将其表达出来。
目标是生成既带有特定情感色彩,又保持语义连贯的文本。
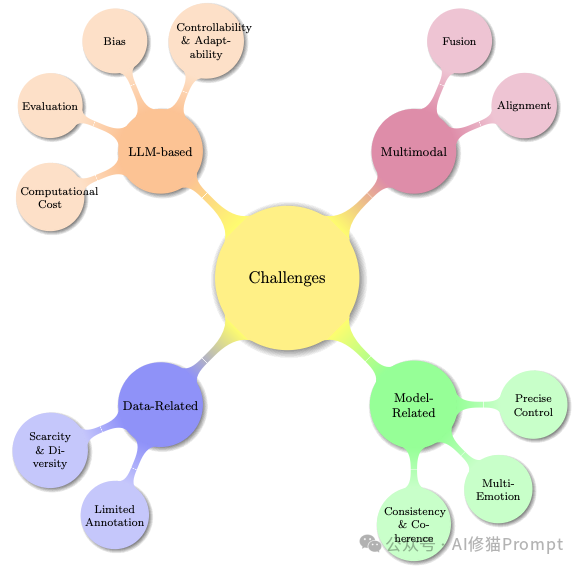
目前的主要难点:可控性 (Controllability)、一致性 (Consistency) 和偏见 (Bias)。
这部分包括情感语音合成 (ESS) 和 情感声音转换 (EVC)。
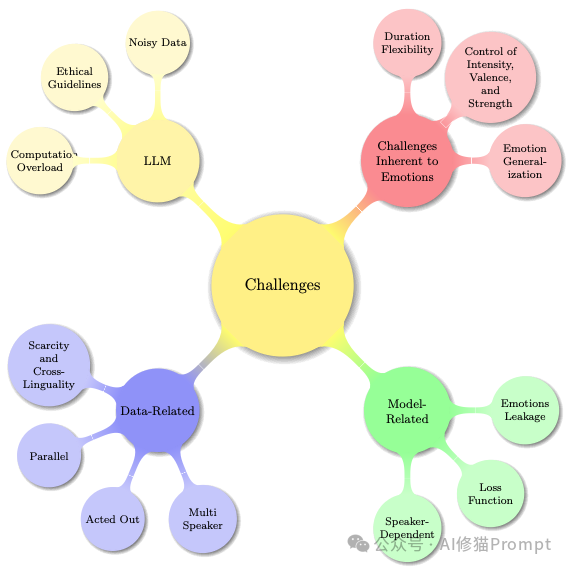
目前的主要难点:数据稀缺 (非平行数据)、情感泄漏 (Leakage) 和 强度控制 (Intensity)
目标是生成逼真的“说话人脸”。

目前的主要难点:微表情 (Micro-expressions)、口型同步 (Lip-sync) 和 计算效率 是瓶颈
整篇论文贯穿了对LLM的深度讨论。LLM和基础模型 (Foundation Models) 正在重塑情感计算的每一个环节。
LLM的机遇:
LLM的挑战:
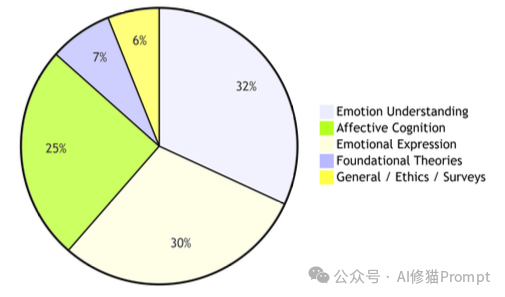
这篇论文为我们展示了构建情感智能体的全貌。我们正处于从简单的情感识别迈向真正的情感智能的关键阶段。以下图片是这篇论文引用的298篇核心文献在各个领域的分布比例图:情感理解占32%,情感表达占30%,情感认知占25%,基础理论占7%
未来的研究方向主要集中在以下几点:
情感智能体的最终目标,不是欺骗人类它们有感情,而是通过理解和模拟情感,成为真正懂你的智能伙伴。论文链接:https://arxiv.org/abs/2511.20657v1
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
