# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
6B小模型,首日下载量高达50万次,上线不到两天直接把HuggingFace两个榜单都冲了个第一。

它就是阿里通义的全新图像模型:Z-Image。
说它“出道即猛”不算夸张,参数虽小,但是出图质量甚至不输同期发布的FLUX.2,在画质、文本、推理等方面属于是SOTA级别。
先来看看官方给出的效果,Z-Image在语义知识上有点本事,对各国名胜古迹那完全是“老熟人级别”,轻松roll出世界名著:

在文本渲染上也同样顶得住,像下面这种包含公式+中英文混排的复杂黑板内容,也能给到相当稳定的输出效果:

网友已经开始玩梗了:“Z-Image最大的特点:能跑在我电脑上……关键是它不烧卡啊兄弟们。”(同期发布的FLUX.2真·欲哭无泪了)

模型表现到底如何,咱接着往下看~
咱先来说说Z-Image这个模型的来头。
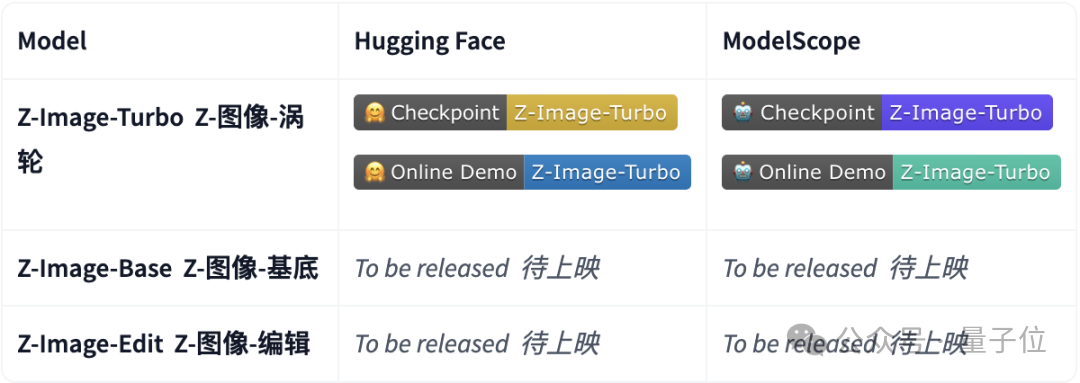
Z-Image是一个6B参数的高效图像生成基础模型,目前主要有三个版本:
1.Z-Image-Turbo(已开源):当前已公开的主要版本,参数量约为6B,在写实风格图像生成、中英文文本精准渲染等方面表现较好,性能接近或超过当前主流开源模型。
2.Z-Image-Edit(未开源):基于Z-Image基础模型专门针对图像编辑任务进行微调的版本,可上传图片并通过自然语言指令进行精确修改,例如更换背景、调整服饰、添加或移动元素等。
3.Z-Image-Base(未开源):未经过蒸馏压缩的完整基础模型,保留了最完整的生成能力和参数容量,该版本主要面向开发者与研究者开放。
咱直接来实测一把,看看Z-Image的生效果到底能不能打!
官方说Z-Image在真实感、构图、美学、中英文渲染、语义理解都很强,那咱直接来点硬菜。
先来试试美学和真实感处理,最近《怪奇物语5》火得不行,我直接让它整了个“颠倒世界”的写实街景,要求有变异生物、咕噜咕噜的光点、氛围感拉满那种~

你别说,从图片效果看,树干和藤蔓被红蓝生物光点覆盖,街道里雾气弥漫,整体效果已经有了很强的电影级真实感,感觉下一秒“魔狗”就跑来抓人了。
但街景不够看纹理细节,咱再拉高难度——来个特写写真级肖像看看模型有没有“塌房”:


从出图效果看,皮肤纹理自然、光线柔和均匀,五官细节清晰不失真,整体质感已经接近专业影棚级的写实肖像照。
咱再来试试Z-Image的大招——文字处理能力。
既然NanoBanana2前几天靠旅游攻略海报炸了一波,那我也让Z-Image来一张老北京旅游攻略:

先说优点,如果不细看,一级标题都没有太大的文字问题,色彩、风格和排版都挺有插画海报内味儿。
但小字就不太行了,“港湾”“故宫”这种越小越容易变形的字,模型还是有点hold不住,看得出来文字能力还在进步区间啊~
不过Z-Image主打的不仅是图像渲染,还有语义理解能力。
这次我想考考它的“常识推理”,让它用科普漫画解释“为什么上下文越长,AI的回答反而可能变差”,看看这模型肚子里的知识储备咋样:

首先值得表扬的是,AI确实看懂的题目要让他干什么,漫画形式+科普内容的理解是到位的,并且强调出了AI之所以没办法很好处理过长的上下文内容的原因。
但还是暴露一些小bug,一是文字变形问题,二是可能受限于图像尺寸的原因,科普原理解释的还是太浅,也能理解。
咱再来看看网友们用Z-Image玩出了哪些有意思的玩法:
有网友直接整出了复古电影质感大片,高级绿、高级蓝加梦幻纹理,画面里那种“银幕颗粒感”都给你安排得明明白白!

还有网友玩起了“微观迷你世界”,雪盖屋顶、小人滑冰、灯光点点,是那种看一眼就想当成桌面壁纸的程度:

再看下面这位网友,直接让Z-Image化身摄影界的“生物专家”,生成了显微镜级别下的昆虫特写。

666,这细节都能直接拿去做科普杂志封面了。
咱转过头再来聊聊Z-Image背后的技术逻辑。
Z-Image之所以能跑那么快,得益于架构优化与模型蒸馏技术的结合,让它在不牺牲高质量的前提下,大幅减少计算量。
先从架构说起。
我们传统图像模型常采用双流设计,文本和图像分别处理,然后通过跨注意力机制融合,这会造成参数冗余和计算浪费,导致推理时间长、显存占用高。
Z-Image则换了条更干脆的路子,用的是可扩展的单流DiT(S3-DiT)架构,把文本token、视觉语义token和图像的VAE token直接串成一条统一序列,让模型一次前向就能把所有模态读完。
路径变短、融合更省事,自然跑得更快:

再说加速的另一半——蒸馏。
扩散模型本来就慢,正常要跑20~50步,每一步都要重新算噪声,画质好但时间代价大。
Z-Image是基础版的“提纯模型”,通过Decoupled-DMD把大模型的能力蒸出来,同时把加速所需的CFG Augmentation(加速核心)和保证质量的Distribution Matching(质量稳定)分开优化。
最后做到只需要8次函数评估就能生成一张高清图:

简单说,就是把原来的长流程压成了极短流程,让速度和质量不再是互相牵制。
正是这种“聪明少干活”的设计,让Z-Image在开源模型里跑出了SOTA水平的速度,同时写实质量和中英文本渲染都保持得很稳。
阿里这次上线开源Z-Image的时间也挺“巧”,和FLUX.2一前一后,但看榜单结果,显然不是“谁先发谁赢”这种简单逻辑啊…
目前Z-Image已在魔塔上线,感兴趣的朋友可以试试~
开源地址:https://huggingface.co/Tongyi-MAI/Z-Image-Turbo
生成地址:https://modelscope.cn/aigc/imageGeneration
文章来自于“量子位”,作者 “梦瑶”。


【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】kimi-free-api是一个提供长文本大模型逆向API的开渔免费技术。它支持高速流式输出、智能体对话、联网搜索、长文档解读、图像OCR、多轮对话,零配置部署,多路token支持,自动清理会话痕迹等原大模型支持的相关功能。
项目地址:https://github.com/LLM-Red-Team/kimi-free-api?tab=readme-ov-file
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
