何恺明团队发布像素空间文生图模型MiniT2I
何恺明团队发布像素空间文生图模型MiniT2I文本生成图像的领域早已经是一片红海,看上去已经卷无可卷了。
来自主题: AI技术研报
8655 点击 2026-06-22 16:53
 搜索
搜索
文本生成图像的领域早已经是一片红海,看上去已经卷无可卷了。

来自西湖大学和香港中文大学(深圳)的团队沿着这一思路提出 Drifting Preference Optimization(DrPO),把漂移场用于单步文生图模型的偏好后训练。在 DrPO 中,奖励只负责对候选图像排序,不参与反向传播。具体而言,针对同一个文本提示词,当前模型生成一组候选图像。高分样本在特征空间中产生吸引,低分样本产生排斥,并结合参考模型约束给出模型的更新方向。
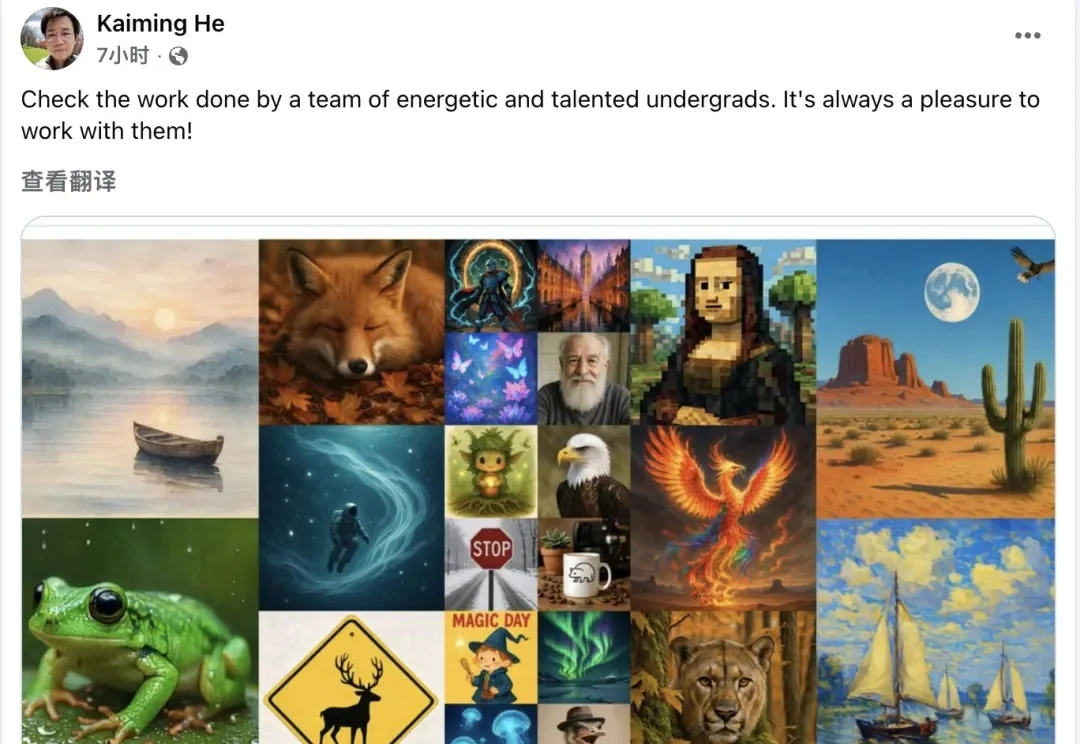
全员本科生! 刚刚,何恺明携本科生“军团”又放出一篇新论文。
文生图的"慢思考",到底有没有用?

近年来,文生图模型的能力快速提升。从 Stable Diffusion 到 FLUX、Qwen-Image,扩散模型已经能够生成高质量图像,也能处理越来越复杂的文本提示。

2K 图像 210ms 解码,4K 细节直接生成,传统「解码 + 超分」流水线可能要被重写了。

UiT 架构探路者,底牌还没亮。

近日,字节跳动智能创作部门(Intelligent Creation Lab)提出新作 DreamLite,一个主干网络仅有 0.39B 参数的轻量级统一扩散模型,在单一网络内同时支持文生图(Text-to-Image) 和图像编辑(Text-guided Image Editing)两个任务,是目前已知首个实现这一能力的端侧模型。

用强化学习(RL)优化文生图模型的 prompt following 能力,是一条被广泛验证的路径 —— 让模型根据 prompt 用不同随机种子生成多张图片,通过 reward model 计算 reward,再利用相关 RL 算法优化模型。

过去两年,图像生成模型在质感和审美上一路狂飙,但大多仍是 “直接出图” 的范式。