# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
斯坦福和MIT的研究团队推出了一种新的AI智能体推理框架ReCAP,在长上下文任务中全面超越了现有的主流框架ReAct,性能提升显著。ReCAP通过独特的递归树结构和三大机制,解决了大语言模型在复杂任务中常见的目标漂移、上下文断层和成本爆炸等问题。在多项基准测试中,ReCAP均取得了大幅领先的成绩,展现出强大的通用性和稳定性。尽管计算成本略有增加,但其在关键任务中的表现使其成为极具潜力的新一代通用推理架构。
自2022年ReAct框架提出以来,AI智能体推理领域便进入了百家争鸣的时代,各种复杂架构如雨后春笋般涌现。
然而,这些架构大多昙花一现,因其复杂的结构导致在更换评测基准时需要大幅修改示例,表现远不如ReAct稳定泛用,这也使得ReAct在过去三年中,成为了该领域事实上的主流与标杆。
但是,我们真的不能再做得更好了吗?
面对大模型在长上下文任务中走几步就忘的短期记忆顽疾,业界是否只能止步于此?
来自斯坦福大学与MIT的研究团队给出了肯定答案,正式发布的AI Agent推理新框架——ReCAP(递归上下文感知推理与规划),从真正意义上统一了序列推理和层级推理,在多种任务中全面战胜了ReAct,且继承了ReAct示例简单、高通用性,和即插即用的优势。

论文链接:https://arxiv.org/pdf/2510.23822
在严格遵循 pass@1(一次通过)的评测原则下,ReCAP在长序列具身任务Robotouille上相比ReAct基线取得了84.2%(同步)和112.5%(异步)的巨大性能提升。
团队指出,当今大语言模型在执行复杂任务时普遍有三种问题:

简单说,LLM就像一个短期记忆型天才,而主流推理框架各有局限:

ReCAP的核心在于将一个有记忆、有反馈的递归树结构作为模型的工作记忆区,其三大机制环环相扣:
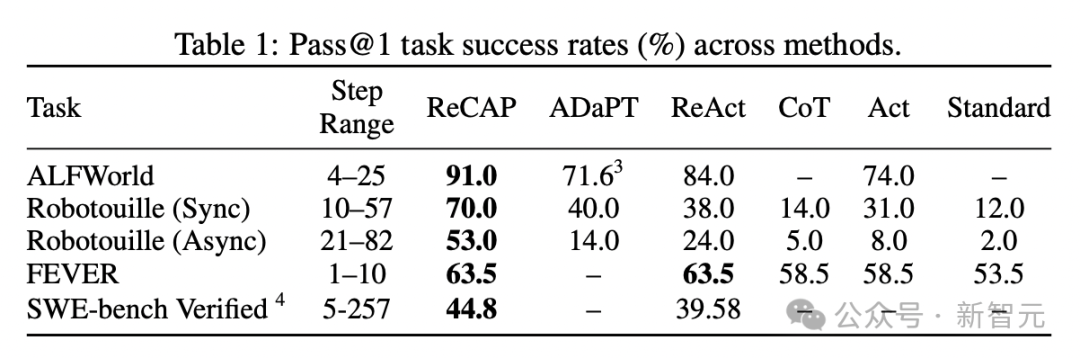
团队在多个典型长上下文推理基准上验证了ReCAP的效果。结果令人瞩目:
值得注意的是,团队在实验中始终秉持pass@1的实验原则,即不使用样本层面的重试、多数投票或者束搜索。这意味着ReCAP能在真实多步环境中,更好地保持目标一致性与执行连贯性——不仅「想得对」,还能「做得稳」。
ReCAP是除ReAct之外,又一个能够在具身推理、以及代码编辑这两种截然不同的任务上都取得稳健表现的通用推理架构。
论文中排除了THREAD、Reflexion等其他基线,因其在实验设置中难以稳定复现或与 pass@1 协议不兼容,这进一步凸显了ReCAP作为新一代通用推理基线的潜力。
任何强大的能力都伴随着成本。团队对此进行了透明分析:ReCAP的总计算成本约为ReAct的三倍。这主要来自于其核心的计划前瞻分解机制所额外需要的LLM调用。
然而,考虑到其在关键任务上带来的性能巨幅提升与目标一致性,这种成本的增加在对准确性要求高的实际应用中是可以接受的。这为开发者提供了一个清晰的性价比权衡选项。
从人类思维到图灵机,递归始终是智能的底层逻辑。ReCAP的提出,可视为AI迈向通用推理系统的关键一步。
其潜力远不止于论文所验证的任务范畴。任何依赖复杂决策回路与长期上下文记忆的大型任务,都是ReCAP的理想应用场景。
例如在深度研究中自主遍历文献、整合多源信息并生成洞察报告;或在复杂软件工程中管理庞大代码库与依赖关系,推进需多步验证的系统项目。
长远来看,ReCAP的递归规划能力可以与空间智能相结合,解决更为复杂的现实世界问题。李飞飞教授近日指出,空间智能——即理解、推理并与三维世界交互的能力,是AI的下一个前沿。
ReCAP可以为具身智能机器人规划复杂的长期任务序列,而空间智能模型则负责处理实时感知与动作控制,二者结合实现机器人在动态环境中的自主规划与可靠执行。
随着代码的开源,一个更擅长长期规划、稳健执行的AI时代或许即将到来。
共同一作 Zhenyu Zhang, Tianyi Chen, Weiran Xu 均为斯坦福大学工程学院计算机系硕士研究生
Alex Pentland教授,麻省理工学院媒体实验室 创始人之一,美国国家工程院院士,Toshiba Professor at MIT,斯坦福大学 HAI Fellow。
Jiaxin Pei博士,斯坦福大学博士后研究员,研究兴趣集中在大语言模型、人机交互、Agentic AI,即将前往得克萨斯大学奥斯汀分校任教。
参考资料:
https://arxiv.org/pdf/2510.23822
文章来自于“新智元”,作者 “LRST”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
