

前端大神Cheng Lou新项目火了!支持AI助手一键接入
前端大神Cheng Lou新项目火了!支持AI助手一键接入Cheng Lou:React 核心团队成员,参与 ReactJS 的早期开发;主导了 ReasonML(后来演变为 ReScript)的开发;目前在 Midjourney 工作,参与 AI 图像生成平台的开发。
来自主题: AI资讯
8011 点击 2026-03-30 15:32
Cheng Lou:React 核心团队成员,参与 ReactJS 的早期开发;主导了 ReasonML(后来演变为 ReScript)的开发;目前在 Midjourney 工作,参与 AI 图像生成平台的开发。
新鲜出炉的龙虾来了!
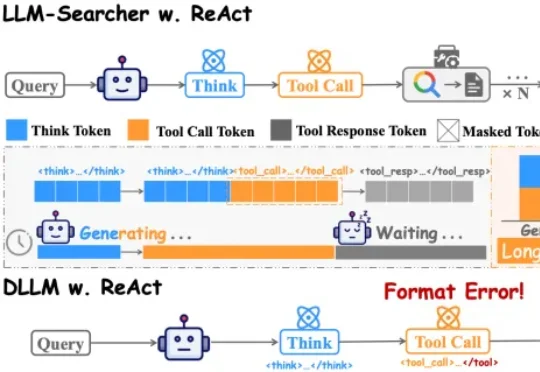
中国人民大学团队在论文DLLM-Searcher中,第一次让扩散大语言模型(dLLM)学会了这种“一心二用”的本事。目前主流的搜索Agent,不管是Search-R1还是R1Searcher,用的都是ReAct框架。这个框架的执行流程是严格串行的:
我们正处在一个AI Agent(智能体)爆发的时代。从简单的ReAct循环到复杂的Multi-Agent Swarm(多智能体蜂群),新的架构层出不穷。但在这些眼花缭乱的名词背后,开发者的工作往往更像是一门“玄学”,我们凭直觉调整提示词,凭经验增加Agent的数量,却很难说清楚为什么某个架构在特定任务上表现更好。
想象你在准备早餐:你不会先写一份详细到「左手抓鸡蛋、右手拿碗、手腕旋转 45 度敲击蛋壳」这样的清单,也不会只有一个笼统的计划叫「做个早餐」,然后不知所措。

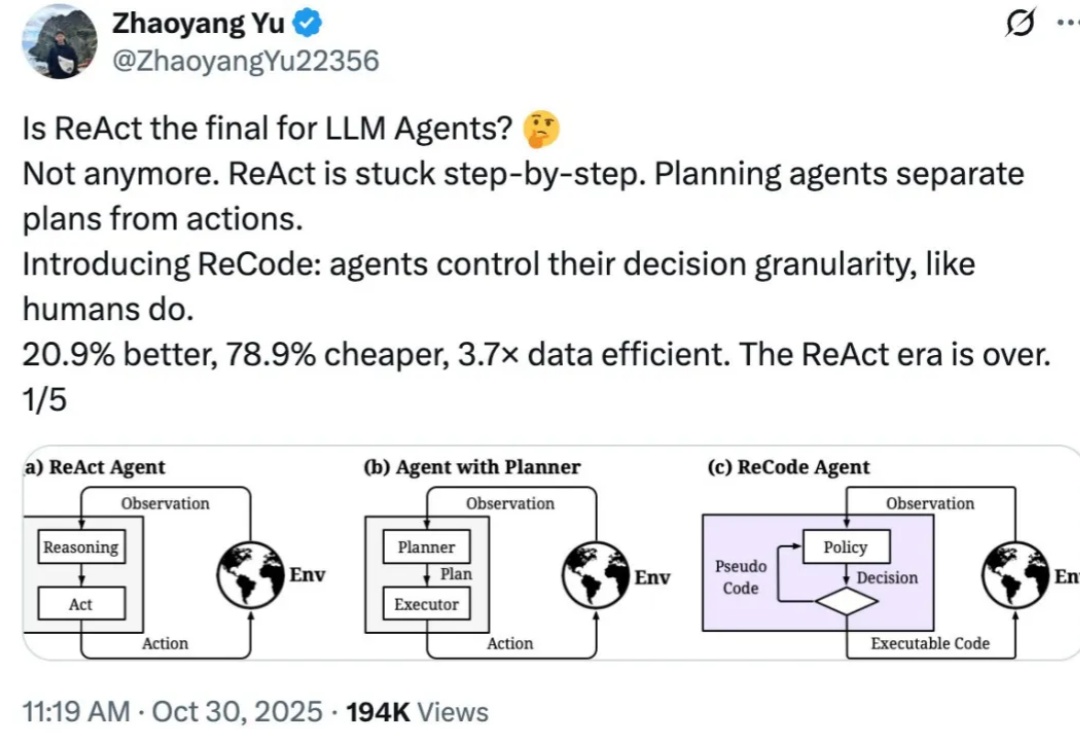
斯坦福和MIT的研究团队推出了一种新的AI智能体推理框架ReCAP,在长上下文任务中全面超越了现有的主流框架ReAct,性能提升显著。ReCAP通过独特的递归树结构和三大机制,解决了大语言模型在复杂任务中常见的目标漂移、上下文断层和成本爆炸等问题。

随着大语言模型与开发工具链的深度融合,命令行终端正被重塑为开发者的AI协作界面。本文以 Google gemini-cli 为范本,通过源码解构,系统性分析其 Agent 内核、ReAct 工作流、工具调用与上下文管理等核心模块的实现原理。为希望构建终端 Agent 的开发者,提供工程实现的系统化参考。

静态编排 VS 动态编排,谁是多agent系统最优解?通常来说,面对简单问题,采用react模式的单一agent就能搞定。可遇到复杂问题,单一agent就会立刻出现包括但不限于以下问题:串行执行效率低:无法同时完成并行的子步骤(如 “同时爬取 A、B 两个网站的数据”)。

通义DeepResearch团队 投稿 量子位 | 公众号 QbitAI 阿里开源旗下首个深度研究Agent模型通义DeepResearch! 相比于基于基础模型的ReAct Agent和闭源Deep
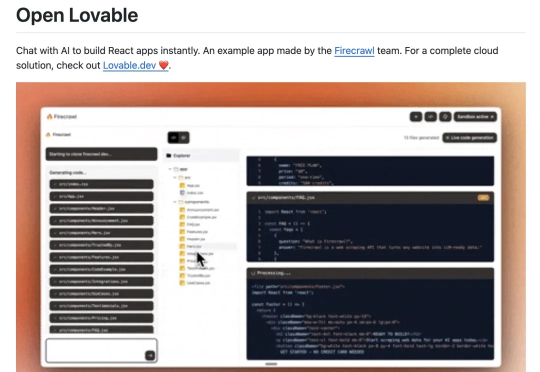
大家好,我是 AI牛马! 作为一个常年和代码打交道的技术博主,最头疼的就是接到“把这个老项目重构成 React”的需求。手动扒页面、抠样式、改交互……动不动就耗上几天。直到在 GitHub 发现 Open Lovable 这个神器,我才知道:原来克隆网站,AI 真的能比人快 10 倍!