# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
想象你在准备早餐:你不会先写一份详细到「左手抓鸡蛋、右手拿碗、手腕旋转 45 度敲击蛋壳」这样的清单,也不会只有一个笼统的计划叫「做个早餐」,然后不知所措。
人类大脑会自然地在煎培根、鸡蛋和敲开鸡蛋这样不同决策粒度间无缝切换,粗粒度的高层规划和细粒度的具体动作融为一体,但目前的 AI 智能体很难做到这一点。
最近,来自 DeepWisdom 的研究员在论文中指出,当前主流智能体框架都被固定的决策粒度束缚住了。ReAct 智能体只会一步步执行细粒度动作,缺乏全局规划;而带规划器(Planner)的智能体虽然能制定高层计划,但规划和执行被硬生生分成两个模块,难以动态调整和优化。
这个问题的根源在哪?论文给出了一个颠覆性的答案:规划和行动本质上是同一件事,只是粒度不同而已。
基于这个洞察,他们提出了 ReCode(Recursive Code Generation),一个用递归代码生成来统一规划与执行的智能体新范式。与 ReAct 这类固定粒度的范式不同,ReCode 让智能体能够在不同粒度间自由切换,从而展现出更强的适应性和潜力。

实验结果也印证了这一点:相比 ReAct,ReCode 在三个环境上的平均性能从 47.4% 提升到 60.8%,推理成本降低 79%,训练时所需样本数减少到原来的 27%。
这项工作在推特上获得了约 20 万的浏览量,引发了学术界和工业界的广泛关注。

让我们先看看现有方案为什么不够好。

基于 LLM 的智能体决策范式比较(a)ReAct 智能体在固定、细粒度的观察-动作循环中运行。 (b)具有规划器的智能体在高级规划器和低级执行器之间强制实施严格的分离,限制了适应性。 (c)ReCode 智能体在代码表示中统一计划和动作。策略递归地将高层计划细化到基本的动作序列,从而实现决策粒度的流畅控制。
ReAct 智能体采用观察-推理-行动循环,每次只能执行一个原始动作,就像导航时每次只能决定向左走 3 米,却无法思考去机场这样的高层目标。这种方式在复杂长期任务中很快就会迷失方向。
以一个简单的家务任务为例。如果要求智能体找到两个闹钟并放入梳妆台,ReAct 智能体需要执行几十步操作:去书桌 1、检查书桌 1、打开抽屉、拿起闹钟 1、去梳妆台、放下闹钟 1、去书桌 2……每一步都要重新推理和决策。这不仅效率低下,而且容易在长链条中出错。更关键的是,它无法形成找到第一个闹钟后该继续寻找第二个这样的宏观认知。
规划-执行分离的智能体则走向另一个极端。它们先用规划器生成完整计划,再用执行器按部就班地执行。问题是,这两个模块说着不同的语言,规划器输出自然语言描述,执行器需要具体动作指令。一旦计划出错,整个系统就卡住了,且规划器很难从执行反馈中学习。
更深层的问题在于,这类方法往往依赖预定义的计划模板或固定的分解策略。比如 AdaPlanner 会预先编写 Python 动作序列然后迭代修改,这种方式虽然增加了规划能力,但仍然受限于模板的表达能力。当遇到训练时未见过的任务类型,或者需要更细粒度或更粗粒度的控制时,系统就难以适应。
论文中强调,这种规划与行动之间的强硬分离,损害了动态适应性并限制了泛化能力。智能体需要的是能在不同抽象层次间自由切换的能力,而不是被困在某个固定层级。就像人类解决问题时,会根据任务复杂度自然调整思考粒度,有时直接行动,有时先制定计划,有时在执行中动态调整,这种灵活性才是智能决策的本质。
面对这个困境,论文提出了一个关键洞察:规划和行动本质上不是两种不同的认知过程,而是同一件事在不同粒度上的体现。
这个想法其实很符合直觉。当「准备早餐」时,这是一个高层次的行动;当「向锅中倒油」时,这是一个低层次的行动。它们的区别不在于性质,而在于抽象程度。既然如此,为什么要用两套完全不同的系统来处理它们呢?
基于这个洞察,ReCode 提出了一个优雅的解决方案:用统一的代码表征来表示所有决策,无论粒度粗细。高层计划表示为占位符函数,低层动作表示为可执行函数,然后通过递归机制将前者逐步分解为后者。

ReCode 流程图(a)任务指令通过基于规则的文本转代码方法转换为初始占位符函数。 (b)系统以深度优先的方式遍历树,自动执行当前节点的代码,并在遇到时将占位符函数扩展到叶子节点。 (c)基于 LLM 的扩展操作具有清晰的上下文。仅提供当前函数签名和可用变量,没有任何树结构或执行历史。
具体来说,ReCode 的工作流程是这样的:
首先,系统将任务指令转换为一个根占位符函数 solve(instruction, observation),其中由 instruction 变量保存任务指令,observation 变量保存环境观察。
接下来,智能体开始展开这个函数。它会生成一段代码,这段代码可能包含:
find_and_take('alarmclock', locations);run('go to desk 1')。关键在于,智能体可以自由混合这两种元素。如果某个步骤很明确(比如已经知道要去梳妆台),就直接写原始动作;如果某个步骤还需要细化(比如怎么找到闹钟),就写一个占位符函数。
然后,系统开始执行生成的代码。遇到原始动作就直接执行,遇到占位符函数就递归(recursively)调用智能体,让它为这个子任务生成新的代码。这个过程一直持续到所有占位符都被展开为原始动作。
从技术实现角度,ReCode 还做了一些精巧的设计。比如通过统一的变量命名空间来传递上下文信息,让子任务可以访问父任务建立的状态;通过设置最大递归深度来防止无限循环;通过纠正机制来处理代码生成错误。
这些设计共同构成了一个既灵活又可控的智能体框架,真正实现了从固定粒度到自适应粒度的跨越。
ReCode 的设计不只是理论上的优雅,通过实验验证,它主要带来了三个方面的提升。
推理性能的提升
论文在三个复杂决策环境上做了充分测试,在 ALFWorld 的未见过任务上,ReCode 达到 96.27% 的成功率,远超 ReAct 的 64.18% 和 CodeAct 的 85.07%。在 WebShop 环境中,也比最佳基线 ADaPT 提升了 21.9%。平均而言,ReCode 的表现比最佳基线高出 10.5 个百分点,相对提升达到 20.9%。
传统的智能体范式要么困在细粒度的步步推理中,要么被固定的规划模板限制。ReCode 则根据任务复杂度灵活调整:简单任务直接执行,复杂任务层层分解。

三个环境在少样本推理设置下的平均奖励表格根据使用模型分为三个部分:GPT-4o mini、Gemini 2.5 Flash 和 DeepSeek-V3.1。每个部分的最优和次优结果分别用粗体和下划线标记。
成本效率的提升
Token 成本对 LLM 智能体也是关键因素。一条 ReCode 轨迹的平均成本比 ReAct 低 78.9%,比 CodeAct 低 84.4%。完成同样任务,ReCode 的花费不到对手的四分之一。这种成本优势源于层次分解带来的结构化探索。ReAct 需要在每一步都详细推理,生成大量中间文本;而 ReCode 用少量高层决策就能完成复杂任务,大幅减少了 token 消耗。
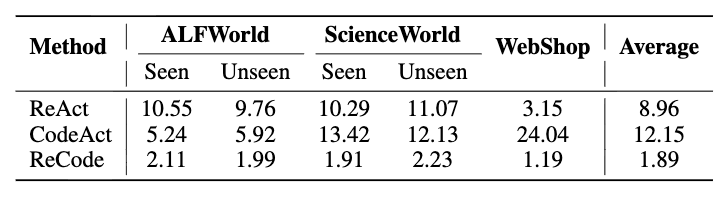
GPT-4o mini 在所有基准环境中的平均成本(× 1e-3 美元)。所有成本计算均参照 GPT-4o mini 的官方 API 定价。
训练效率的提升在 ScienceWorld 环境中,ReCode 只用 3500 个训练样本就达到 88.5% 奖励,而 ReAct 需要 12833 个样本(3.7 倍)才能达到相似的性能。
更细致的实验显示,在使用前 10% 的数据时,ReCode 仅用 688 个样本达到 44.87% 的性能,ReAct 用 3094 个样本(4.5 倍)只达到 34.05%。ReCode 的轨迹是完整决策树,这种递归结构天然产生层次化训练数据,而 ReAct 方法的轨迹则是扁平动作序列。
在 ReCode 中,从高层规划到子任务分解再到原始动作,每一层都是独立训练样本。模型在 ReCode 上进行训练,不仅学会执行,还学会规划和分解,掌握了可迁移的任务结构。
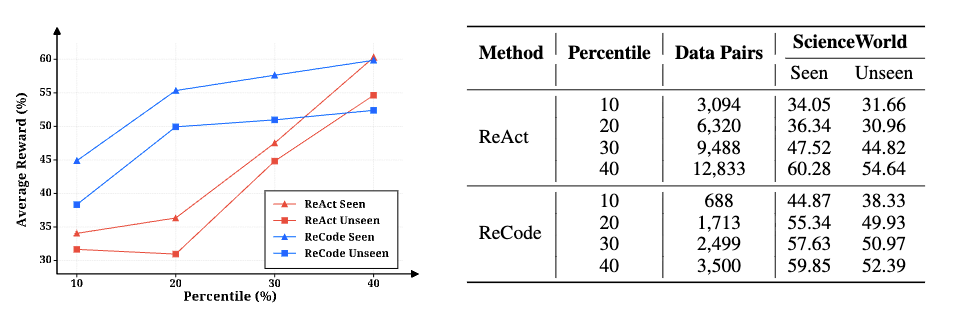
左图:ReCode(蓝色)和 ReAct(红色)在 ScienceWorld 不同过滤百分位数下的 SFT 性能。已见任务的性能用三角形表示,未见任务的性能用正方形表示。右图:训练数据统计和对应 ScienceWorld 性能的 ReAct 和 ReCode。表格列出了数据对的数量以及每种方法在不同过滤百分位数下的平均奖励。
ReCode 不只是推理范式的创新,更为智能体学习开辟了新路径。其递归结构产生的层次化数据天然适合训练,让模型从 3.7 倍少的样本中学到更多。但 ReCode 的效果高度依赖基础模型其生成所需格式代码的能力。
未来研究可以探索的方向有很多:通过专门的预训练目标让模型理解递归分解逻辑、用强化学习奖励高效的层次化规划、引入自动课程学习让模型逐步掌握复杂分解。这些方向都指向一个核心:让智能体不仅会用框架,更能通过学习不断优化自己的规划策略。ReCode 证明了打破规划和行动边界的可行性,接下来是让这种能力真正成为可学习、可进化的。
文章来自于“机器之心”,作者 “于兆洋”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
