# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
“问题,是用旧思维制造的;它不可能靠同一套思维被解决。”
作为“机械式理性主义”批判者的爱因斯坦,多次强调:科学突破不是线性推理
的自然延伸。
在解释相对论为何颠覆牛顿体系时,他的逻辑就是:停止在旧体系里“修修补补”,直接换了一套理解世界的坐标系。
而在通往 AGI 的道路上,Scaling Law+ Transformer路线是不是也走到头了?是不是也得换一套方法论呢?
当地时间12月4日下午,谷歌研究员的一篇论文在现场引来了超多AI爱好者的围观。
甚至,被业界专家视为“为AGI发展提供了新框架”,一位人士评价为:这篇论文将成为逐步推动实现AGI的5~10篇论文中的一篇。

这位网友点评道:在今天上午NeurIPS 大会,强化学习之父 Richard Sutton 再次提醒,我们需要持续学习才能实现通用人工智能。

而下午谷歌的这篇论文《Nest learning》,为持续学习提供了新思路。
过去两年,AI 的进化速度越来越快,但一个核心问题始终没有被真正解决:模型能学会,却很难真正“记住”。你给它再多上下文,只要对话结束,这些经验就像从未发生过。
最近,来自谷歌的研究员提出了一条全新的技术路径,试图从底层打破这一限制——他们把这条路线称为 Nested Learning(嵌套学习),并基于它构建了全新的连续体记忆系统 CMS 与 HOPE 架构。

这中架构与此前的“训练→推理”的框架不同,而是一次试图重写模型如何获得记忆、如何积累知识的尝试。如果这条路成立,AI 将第一次具备真正意义上的“长期学习能力”。

深度学习本质上是上下文压缩:现有方法(如Transformer)通过注意力机制压缩上下文流,导致信息丢失。
而 NL 则显式建模多级压缩,实现“联想记忆”。
谷歌研究员 Ali Behrouz(论文一作)上来抛出了自己的问题发现:
今天的大模型有两种知识来源。
一类来自预训练,知识被固化在参数里,像是长期记忆;另一类来自推理时的上下文,是临时可用的信息。但问题恰恰出在这里——上下文一旦消失,模型对这些新知识的记忆也随之消失。
研究团队用一个非常形象的医学类比来描述这种状态:顺行性遗忘症(anterograde amnesia)。这种病人可以记住过去,也能短暂记住现在,但无法把短期记忆转化为长期记忆。也就是:人会不断地“重新体验当下”,却无法真正记住新东西
而对当前主流大模型来说,病状就是:它们“看得见”,却“存不住”。这带来的直接后果是:
研究员的问题很直接:能不能让模型在推理阶段学到的东西,被真正“写进”模型本身?
这项研究最重要的突破,不是提出某个新模块,而是重新定义了架构、注意力和优化器的本质。
他们提出一个核心抽象:
几乎所有深度学习结构,都可以被看作是一种“关联记忆系统”。
所谓关联记忆,本质就是在学习 Key → Value 的映射关系。
这些都属于“关联”。他们进一步发现:
进一步往下推,他们得出了一个更激进的结论:
梯度下降本身,也是一种关联记忆。
模型用当前参数状态作为“输入”,生成梯度作为“输出”,再用这个输出更新自己。这是一种高度自指的学习系统。模型在用自己,训练自己。
当他们把“动量”(Momentum term)也纳入这个体系时,发现动量其实就是一种对历史梯度的压缩记忆。这让架构、优化器、注意力、内外记忆第一次被统一到同一个理论框架下。
当前 Transformer 只有两种极端记忆方式:
中间地带是空的。这意味着模型要么“极短记忆”,要么“永久固化”,完全缺少类似人类那样的中期记忆结构。

为了解决这个问题,他们提出了一个关键设计:
不再只有一个固定的 MLP,而是引入多个、不同更新频率的 MLP 模块。
例如:
这样一来,模型内部就形成了一个真正意义上的:
并存的连续记忆系统。这正是他们后来称为 Continuum Memory (连续记忆) 的核心思想。
总结一下,CMS 把传统“长期/短期记忆”观点泛化为连续体记忆:记忆不是二元分离,而是连续谱,从瞬时(高频)到永久(低频)。形式公示如下:
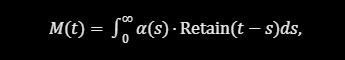
其中,α 是保留权重,Retain是衰减函数。CMS 使用多级嵌套优化维护这个积分,支持无限历史追踪而无爆炸性增长。

论文通过NL 范式提出三个互补的技术创新,每个都直接应用于持续学习和长上下文任务。深度优化器、自修改模型Titans、连续记忆系统CMS+Hope架构。
首先,是深度优化器。
传统优化器(如Adam、SGD with Momentum)可视为联想记忆模块,通过梯度下降压缩梯度上下文流。具体地,Adam 的更新规则类似于Hebbian学习(“同时激活的神经元加强连接”),但仅用点积相似度(dot-product similarity)计算,导致记忆效率低(忽略样本间关系)。


技术细节:Deep Memory Optimizers 内层使用RNN或Transformer压缩长梯度序列,支持“深度记忆”(deep memory),如多层嵌套以捕捉梯度依赖。
比如用高级学习规则,将点积替换为非线性相似度,提升了优化在噪声数据下的鲁棒性。再比如将优化器重构为嵌套优化,还提出了更experssive的优化器变体等,更多细节,大家可以自行翻阅论文。
在实验的基准优化任务中,Deep Optimizers 收敛更快 15-20%,并减少 30% 的遗忘率(通过模拟持续优化)。
其次,基于上述理论,谷歌团队提出了一个Self-Modifying Titans:自修改序列模型Titans。
NL 允许模型“学习如何学习”,即内层优化直接修改外层参数,实现自改进(self-improvement)。
技术细节方面,架构上
外层是标准RNN/Transformer,外层参数 θ
通过内层“元优化器”(meta-optimizer)更新。
自修改机制
:使用NL 的上下文流追踪历史更新,允许模型动态调整架构(比如:添加/删除层)。这类似于“Titans”——可进化的大型模型。
实验发现,在少样本泛化(few-shot learning)中,自修改模型适应新任务时,性能提升 10-25%,无需重训整个模型。
第三项,则是HOPE架构。
第二和第三项,我们放到下一部分单独聊。
自修改序列模型Titans
Titans 作为一个基础序列模型,本质是:
这不是谷歌团队拍脑袋拼出来的模块,而是从“记忆优化”这个数学目标自然推导出的结构。
接着,他们又做了一次更激进的升级,构建了:自反省 Titan(Self-referential Titan)
在这个版本中:
再加上前面的多频率 MLP 连续记忆系统,最终形成了完整的:
HOPE 架构
这是一个第一次真正具备“跨时间持续学习结构”的大模型框架。
Hope 架构则是集大成的一个架构,它是一个
结合了自修改序列模型 和 CMS 的一个 POC。
def hope_update(x, theta, phi): # theta: 外层参数, phi: 内层CMS context_flow = compress_context(x, phi) # 内层: 高频压缩 grad = compute_grad(context_flow, theta) phi_new = inner_opt(phi, grad) # CMS 更新 theta_new = outer_opt(theta, phi_new) # 低频自修改 return theta_new, phi_new

在多组关键实验中,HOPE 展现出了与传统 Transformer 本质不同的能力曲线。
第一,语言建模与推理能力上,在 10 亿参数级别超过 Transformer 与原始 Titan。这说明引入连续记忆并没有牺牲基础建模能力。


第二,在超长上下文任务中,HOPE 在千万级 Token 上仍能稳定工作,而 Titan 在 200 万 Token 左右就出现明显性能崩溃。这意味着记忆不再依赖注意力,而是真正写入模型。

第三,在连续学习任务中,模型被要求不断学习新语言、新分类规则。传统 In-context Learning 很快失效,而 HOPE 能持续稳定提升。
这组结果释放了一个极其重要的信号:
大模型第一次在结构层面具备了“越用越聪明”的潜质。
ps:如果大家对于具体的数字感兴趣,小编也整理下来了。
实验整体给出的结论是:Hope 在参数效率上优于Transformer(相同规模下性能 +15%),并在计算成本上更低(O(n log n) vs. O(n²))。
当然,Hope目前还有局限性
:内层优化计算开销高(需并行化);在极大规模 (>1B 参数) 上需进一步缩放测试。
研究团队也非常克制地承认:
但他们同时给出了极其明确的判断:
这条路径是正交于当前主流大模型路线的“第二增长曲线”。
只要连续记忆成立,它可以被叠加到任何现有架构之上,而不是替代。
谷歌这项工作的价值量相当高,可以说是第一次系统性地回答了一个被长期回避的问题:
AI 的“记忆”究竟应该写在哪里?
不是只写在注意力里,也不只写在参数里,而是应该分布在不同时间尺度上,形成一个真正可进化的学习系统。
如果这条路线继续推进,未来的 AI 将不再只是:不停靠一次性训练来的得到新模型,不停靠上下文临时装聪明。
而是会逐渐走向:
从这个意义上说,自指 Titan、CMS 与 HOPE 早已不仅仅是一次模型结构创新,更是一次对“智能如何随时间自我进化”的正面回答。
如此,业界似乎大可不必每天为“参数规模”和“算力数量”焦虑了,一个好的模型架构真的可以改变AGI发展的走向。
不得不感叹,实力可怕的谷歌!
论文地址:
https://abehrouz.github.io/files/NL.pdf
参考链接:
https://x.com/PTrubey/status/1996442036925239510
https://www.youtube.com/watch?v=uX12aCdni9Q&t=1194s
文章来自于微信公众号 “51CTO技术栈”,作者 “51CTO技术栈”



