# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
自动驾驶数据荒怎么破?
来自香港大学OpenDriveLab、中科院自动化所、小米汽车的联合团队提出了一种解决方案——SimScale。
该方案通过真实世界仿真生成关键场景,以及真实仿真协同训练策略,首次揭示了自动驾驶仿真数据的规模效应。
无需更多真实数据,只靠扩大仿真数量,一样能持续突破任何端到端驾驶模型的性能上限。

为什么要有SimScale?
因为让大模型屡创新高的Data Scaling,在自动驾驶场景中失灵了——
现实世界难以提供足够的关键与长尾场景,采集到的大多是价值有限的常态片段,导致数据越多、提升越难。
因此,自动驾驶的瓶颈不在规模,而在缺乏能系统生成关键场景并支撑大规模训练的新路径。
为此,SimScale应运而生。
SimScale是一个能“无限扩张世界”的仿真生成框架,通过高保真神经渲染,自动制造多样化反应式交通场景与伪专家示范。
它也是一套让仿真与真实“相互增益”的训练策略,使各种端到端模型都能越训越强,鲁棒性与泛化性全面提升。
它还是一份首次系统揭示自动驾驶仿真规模效益的“实践手册”,通过实验深度分析把仿真推向规模化的关键因素。
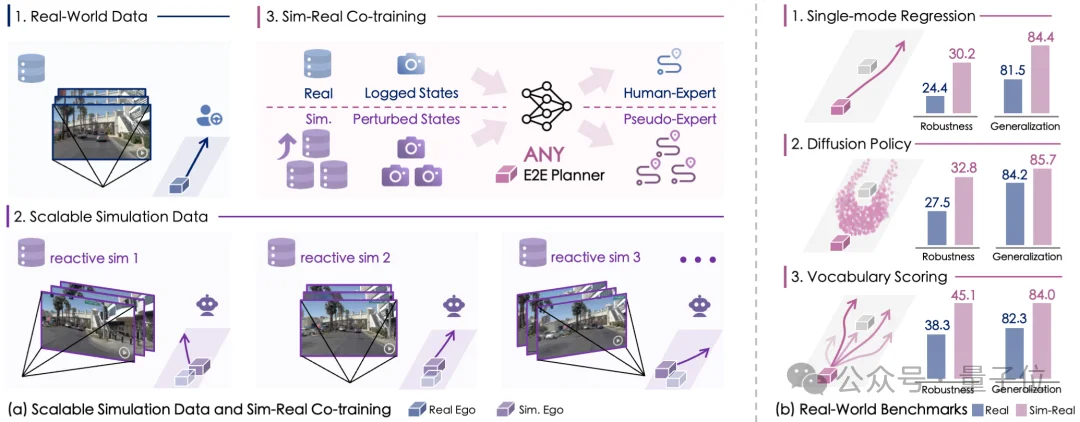
△SimScale系统架构和性能表现
可用于端到端模型训练的仿真数据需要同时包含合成图像和专家示范轨迹,以确保这些场景能“教得动模型”。
因此SimScale采用“干扰-规划”的策略,实现规模化的仿真数据生成。
基于3D高斯泼溅(3DGS)重建的真实场景资产,SimScale能将车辆在不同位置和朝向下的状态渲染成多视角RGB视频。
系统通过将背景与动态车辆分别建模并剔除低质量区域,在保持高效渲染的同时最大程度保留真实世界的光照、几何和语义细节。
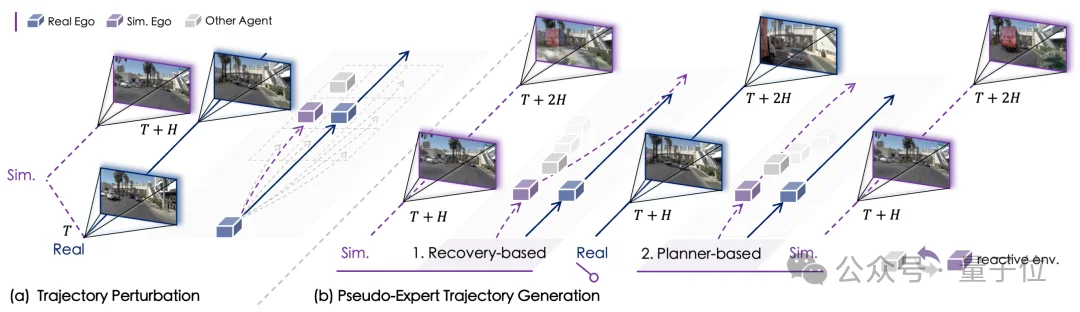
△基于伪专家的仿真场景生成
为了覆盖长尾关键场景,SimScale 在真实轨迹上施加合理范围的扰动,并借助空间下采样去除冗余,最后生成多样状态分布。
这些操作会让自车进入现实中难以遇见的危险情形,如偏离车道、逼近障碍物或激进交互,从而系统性扩展策略的可见状态空间,提供人驾数据中无法安全采集的数据。
在扰动合成出的复杂与失稳状态中,仿真需要为模型提供高质量的监督示范。
SimScale设计了两类互补的伪专家策略(Pseudo-Expert),便于后续能够在鲁棒恢复与策略探索之间进行探索:
SimScale不仅模拟自车,还让周围交通参与者具备反应能力,包括让其他车辆根据自车行为触发减速、避让、跟车、切入等真实道路中的互动策略。
这种反应式交通模型避免了“单向度”仿真,使场景能自然演化出更多复杂动态,从而形成更接近真实驾驶的可扩展场景分布。
SimScale不仅能大规模生成关键场景,还提供了一套仿真-真实数据协同训练的策略(Sim-Real Co-training),让端到端自动驾驶模型充分利用仿真数据,同时保持对人类驾驶行为的忠实拟合。
训练过程中,SimScale 从真实数据集和仿真生成数据集中随机抽样,使模型既保留真实驾驶分布,又避免因渲染细微差异、光照或动态抖动等仿真瑕疵导致性能下降。
借助完全自动化的可扩展仿真生成框架,SimScale 可以逐步增加新仿真样本,无需额外真实数据即可不断扩展训练数据规模。
SimScale的协同训练策略可适用于各类端到端规划模型,包括回归型(regression-based)、扩散型(diffusion-based)及轨迹评分型(scoring-based)规划器。
对于依赖专家示范轨迹的规划器,仿真伪专家轨迹可以提供可靠监督;而对于奖励驱动的规划器(如轨迹评分型),仿真数据可直接用于优化策略,无需单一路径示范,让模型探索最优策略,实现仿真数据利用效率最大化。
实际应用中,仿真中生成四类真实驾驶中最易触发模型失效的关键场景,包括偏离车道、近距离失碰、车道脱出与加塞切入,并为每个场景提供伪专家轨迹与扰动历史动作,帮助策略在高风险、短时决策条件下学习更强的纠偏与避险能力。
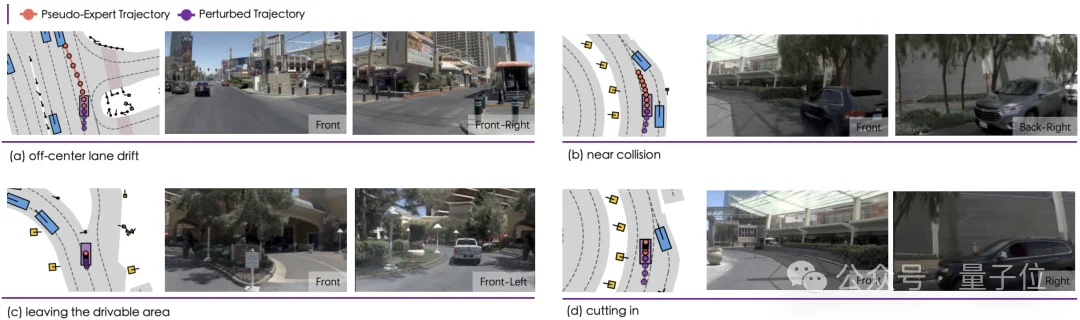
△高价值仿真场景可视化
模拟自车状态和轨迹,也呈现出了明显的差异和更多样化的分布。
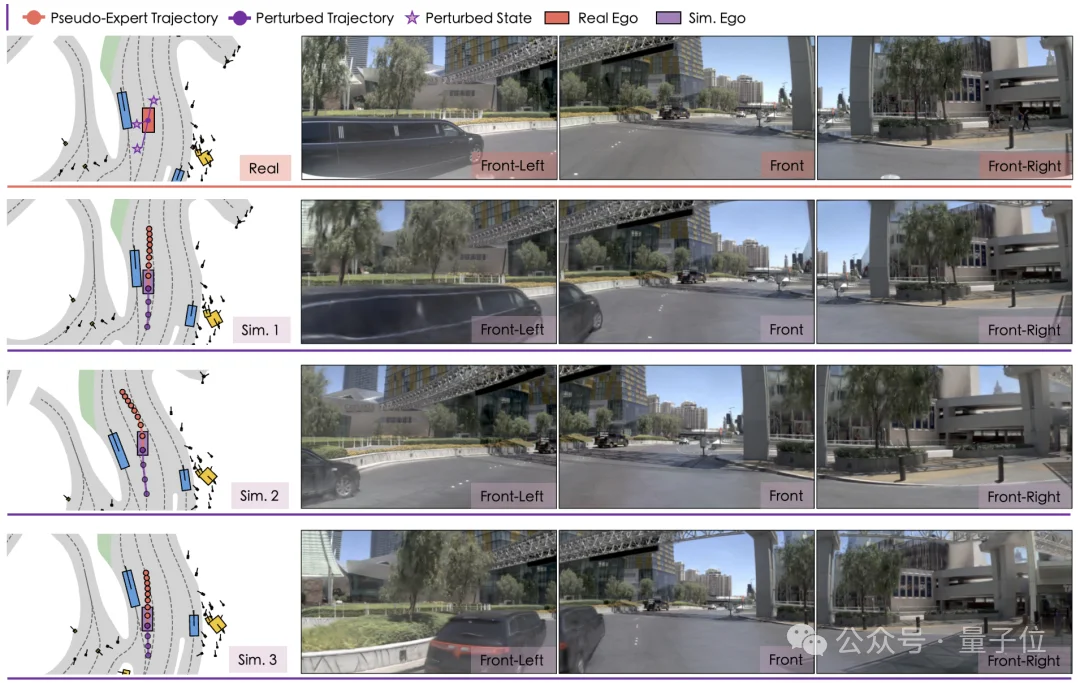
△伪专家仿真场景可视化
真实世界测评中的鲁棒性和泛化性是自动驾驶模型的关键能力,前者决定了模型的上限,反映了模型在未见的极端场景下的应对能力(navhard基准);
后者决定了模型的下限,反映了模型在多样化挑战性场景下的可靠性(navtest基准)。
然而传统训练范式很难在两者之间做到平衡,但经过全面的测试,SimScale仿真-真实协同训练在真实世界闭环测评中,实现了鲁棒性与泛化性的全面提升!
在navhard基准中,所有类型的端到端规划器的性能均有大幅增强,最多可提升6.8 EPDMS,其中基础性能较弱的规划器更增加了超过20%的性能!
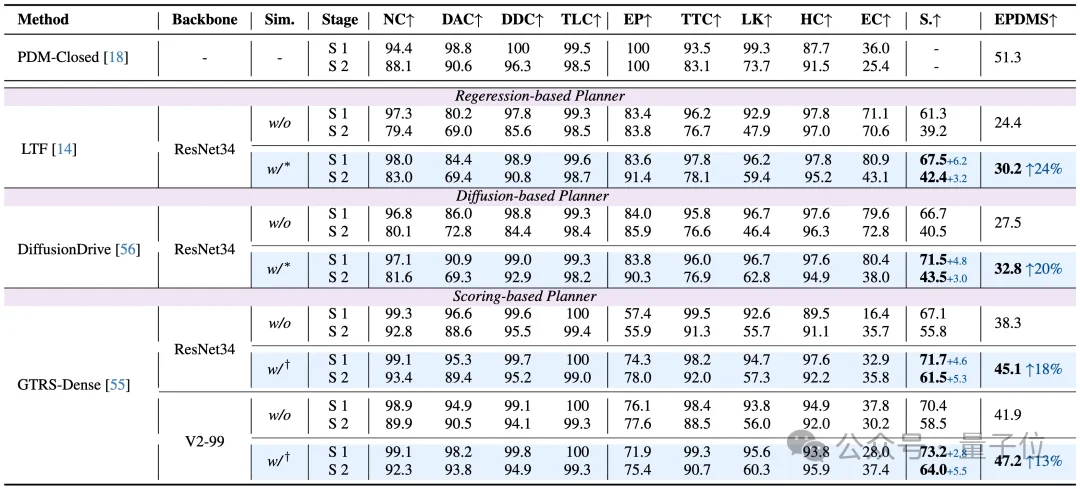
而在navtest基准中,所有类型的端到端规划器的性能也有明显增强,最多可提升2.9 EPDMS。
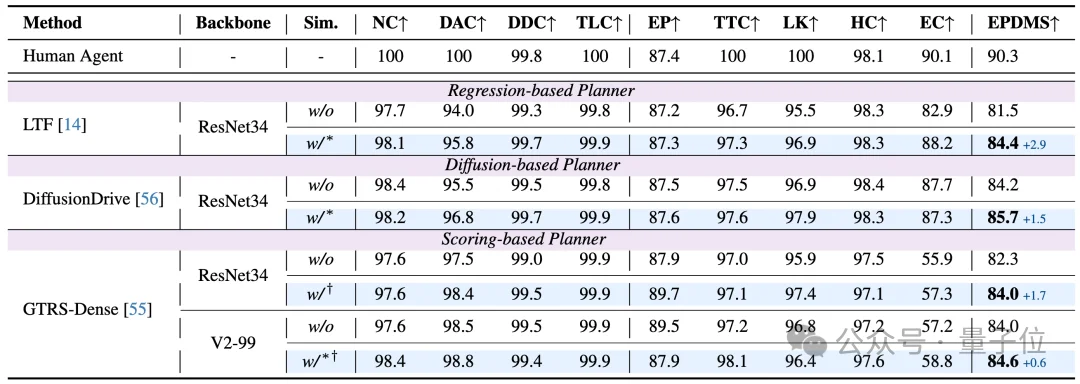
另外,通过对轨迹评分规划器进行多专家集成 (Multi-Expert Ensemble),SimScale实现了NAVSIMv2官方排行榜#1,这也揭示了不同伪专家训练的模型存在潜在的互补能力,可以实现彼此增益。

SimScale首次系统揭示了仿真数据对端到端规划模型性能的规模效应,通过拟合对数二次函数,建模总数据量(真实 + 仿真)与模型表现的关系,展示了在真实数据固定时,随着仿真数据量增加,模型在不同伪专家策略和规划器上的表现差异。
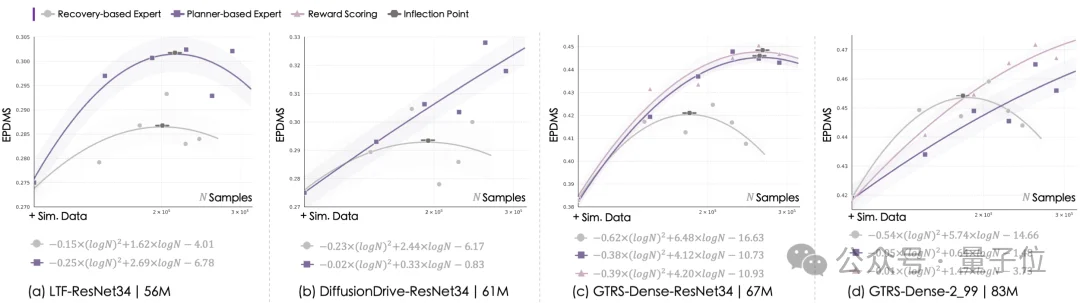
基于SimScale系统,作者得到了三个重要发现。
一是探索型伪专家更为高效。恢复型伪专家性能提升较早收敛,最终表现不如规划型。原因在于恢复型始终贴近人类轨迹,缺乏多样性;规划型可探索更广状态空间,生成更多可行解,从而充分发挥仿真数据价值。
二是多模态建模激发了数据扩展能力。多峰行为分布是自动驾驶的本质问题,回归型模型难以应对多样化仿真示范,而扩散型模型能捕捉多模态特性,随数据增加表现持续提升。
三是只要通过奖励驱动即可实现高效训练。对评分型规划器,仅使用奖励信号即可在仿真中取得优异表现,无需伪专家轨迹。这说明奖励引导能充分发挥仿真数据的价值,同时保持策略优化方向稳定。
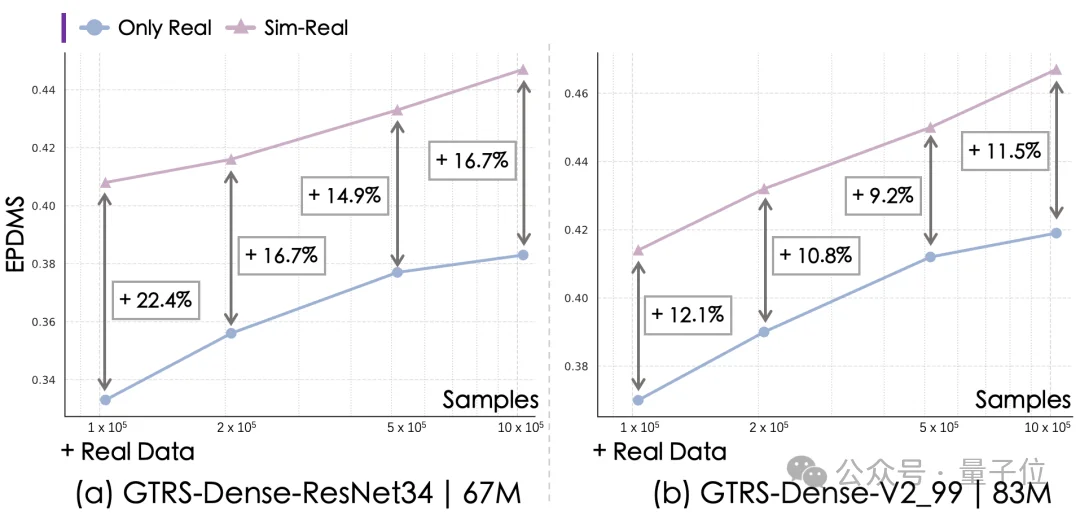
为了验证SimScale在实际端到端训练中的价值,研究团队固定真实-仿真数据比例,系统研究了当真实数据扩增,仿真数据是否还能持续带来收益。
结果,仿真增益随真实数据规模的变化呈现出了持续稳定的趋势,无论真实数据是稀缺还是丰富,仿真数据带来的性能提升始终显著且不减弱——
在小数据量下提升最为明显,而当真实数据扩增后,增益依旧保持稳定,没有出现常见的“收益饱和”。
这表明SimScale能在不同数据规模下持续放大端到端系统的性能。
SimScale通过创新性的真实世界仿真架构与虚实协同训练策略,全面提升任意端到端驾驶模型的鲁棒性和泛化性;首次揭示了自动驾驶仿真数据的规模效应。
无需更多真实数据,只靠扩大仿真数量,就能持续突破任何端到端驾驶模型的性能上限!
Home: https://opendrivelab.com/SimScale/
Github: https://github.com/OpenDriveLab/SimScale
ArXiv:https://arxiv.org/abs/2511.23369
文章来自于“量子位”,作者 “OpenDriveLab”。


