
把人类驾驶员赶出机场,复旦大牛校友要港股IPO了
把人类驾驶员赶出机场,复旦大牛校友要港股IPO了4月19日,驭势科技通过港交所聆讯。吹响IPO号角,第二次。
来自主题: AI资讯
7493 点击 2026-04-21 09:24
 搜索
搜索
4月19日,驭势科技通过港交所聆讯。吹响IPO号角,第二次。
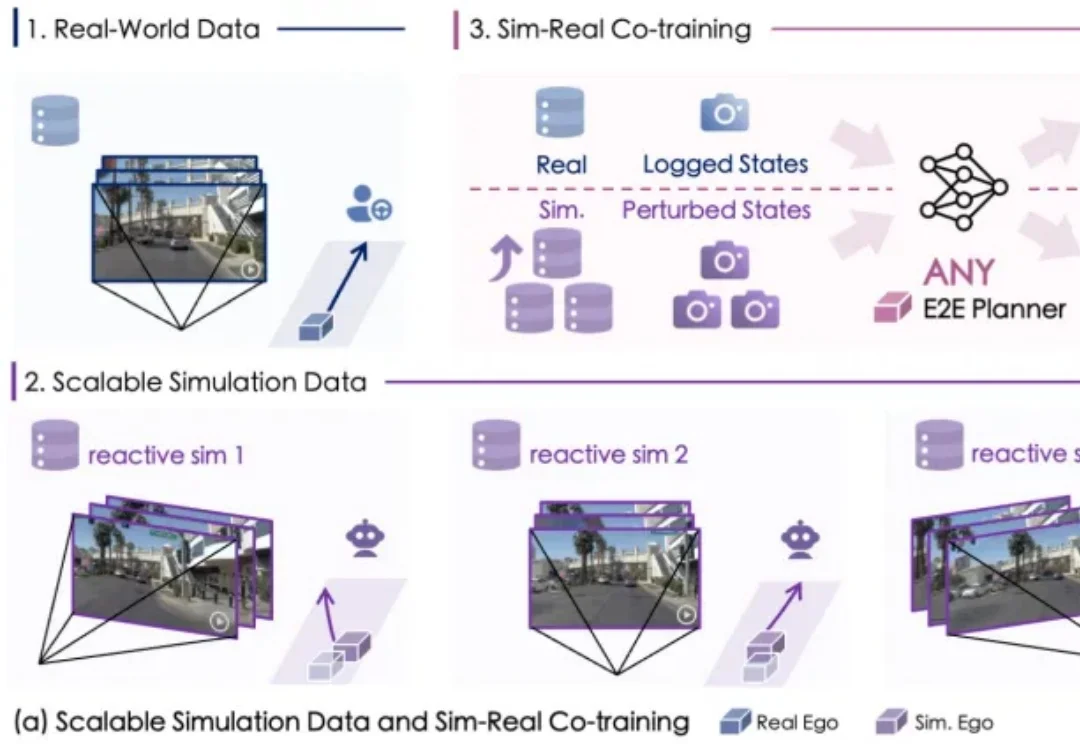
自动驾驶数据荒怎么破?
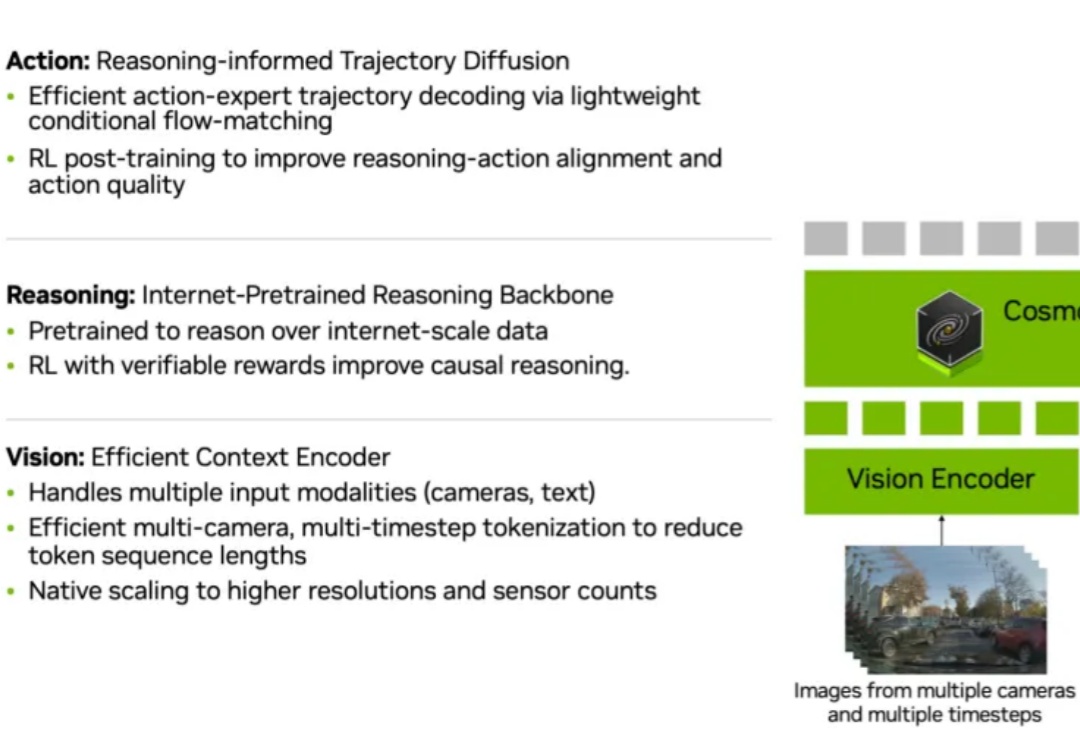
当今自动驾驶模型越来越强大,摄像头、雷达、Transformer 网络一齐上阵,似乎什么都「看得见」。但真正的挑战在于:模型能否像人一样「想明白」为什么要这么开?
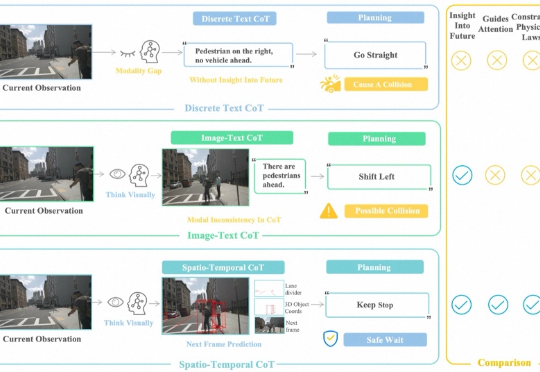
面向自动驾驶的多模态大模型在 “推理链” 上多以文字或符号为中介,易造成空间 - 时间关系模糊与细粒度信息丢失。FSDrive(FutureSightDrive)提出 “时空视觉 CoT”(Spatio-Temporal Chain-of-Thought),让模型直接 “以图思考”,用统一的未来图像帧作为中间推理步骤,联合未来场景与感知结果进行可视化推理。
从重庆魔幻山城到全球Robotaxi布局,千里科技展现出将AI融入物理世界的雄心。董事长印奇的「千里计划」——One Brain, One OS, One Agent——勾勒出跨场景智能生态,让汽车成为高效、安全的现实世界入口和未来的人类伙伴。

由华中科技大学与小米汽车提出了业内首个无需 OCC 引导的多模态的图像 - 点云联合生成框架 Genesis。该算法只需基于场景描述和布局(包括车道线和 3D 框),就可以生成逼真的图像和点云视频。

Wayve,一家总部位于英国的无人驾驶初创公司,有望凭一己之力拿到其中的五分之一。该公司日前宣布,已与英伟达签署意向书,后者将在其下一轮融资中“评估 5 亿美元的投资”。同时,Wayve 即将推出的 Gen 3 硬件平台,将完全基于英伟达的 DRIVE AGX Thor 车载计算平台打造。
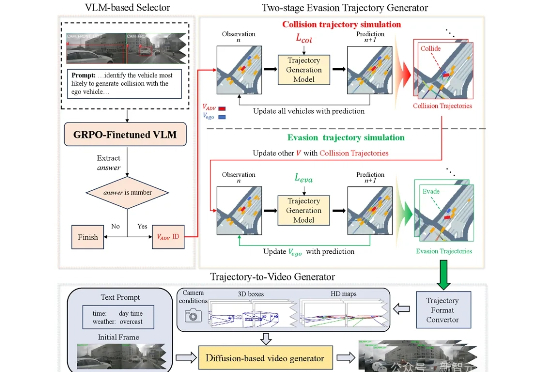
浙江大学与哈工大(深圳)联合推出SafeMVDrive,利用扩散模型结合VLM实现批量化多视角真实域的安全关键视频生成。该方法在保持画质与真实感的同时,显著增强了驾驶场景的危险性。生成的场景用于端到端自动驾驶系统的极限压测,可使得模型的碰撞率提升50倍。
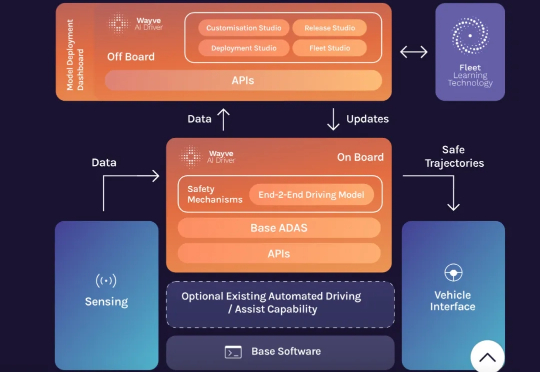
2024年5月,英国自动驾驶初创公司Wayve宣布完成10.5亿美元(约合人民币75亿元)的C轮融资,这不仅成为2024年全球自动驾驶领域最大规模的单笔融资,同时也是欧洲人工智能公司有史以来获得的最大投资之一。

CVPR 2025,自动驾驶传来重大进展: Scaling Law,首次在这条赛道被验证!