# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
上下文分割(In-Context Segmentation)旨在通过参考示例指导模型实现对特定目标的自动化分割。尽管 SAM 凭借卓越的零样本泛化能力为此提供了强大的基础,但将其应用于此仍受限于提示(如点或框)构建,这样的需求不仅制约了批量推理的自动化效率,更使得模型在处理复杂的连续视频时,难以维持时空一致性。
北京邮电大学联合南洋理工大学等机构发表的 IEEE TPAMI 期刊论文《DC-SAM: In-Context Segment Anything in Images and Videos via Dual Consistency》,不仅为图像和视频的上下文分割建立了统一的高效框架 DC-SAM,还构建了首个视频上下文分割基准 IC-VOS。
研究团队巧妙地提出基于提示微调的 “循环一致性” 机制,通过正负双分支与循环一致性注意力的协同,配合 Mask-Tube 策略,实现了 SAM 与 SAM2 在图像及视频上下文分割任务上的统一与高效适配。
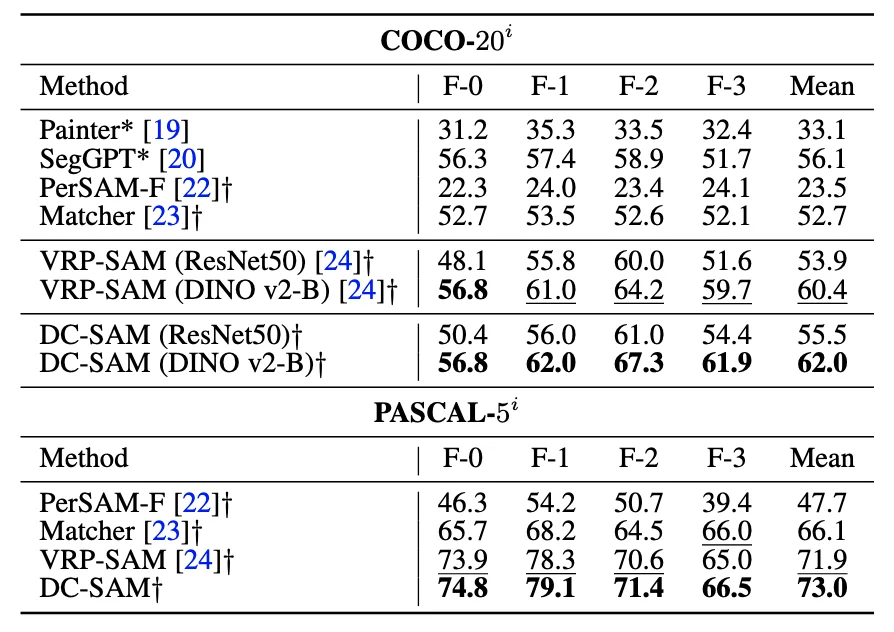
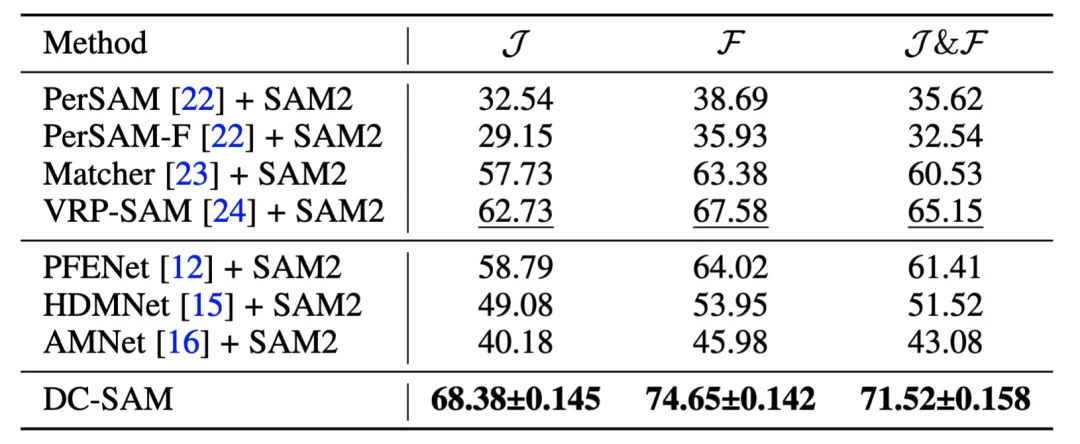
实验结果显示,DC-SAM 在多个基准测试中均取得了 SOTA 性能:在 COCO-20i 上达到 55.5 mIoU,在 Pascal-5i 上达到 73.0 mIoU;在新建的 IC-VOS 视频基准上,J&F 得分高达 71.52,显著优于现有方法。该篇论文已被 IEEE TPAMI 录用。

近年来,以 SAM 和 SAM2 为代表的视觉基础模型凭借海量训练数据,展现了卓越的交互式分割能力,已成为医学影像、开放词汇分割等下游任务的强大基石。然而,尽管 SAM 在 “分割一切” 上表现出色,却缺乏 “上下文分割”(In-Context Segmentation)的能力 —— 即无法仅凭一张参考示例(Support Image)及其掩码,自动在查询图像(Query Image)中分割出同类目标。
为了弥补这一短板,早期的少样本学习方法多依赖度量学习,但泛化能力有限。虽然 SegGPT 等通用模型通过大规模图文对训练实现了上下文分割,但其计算资源消耗巨大。相比之下,提示微调(Prompt Tuning)提供了一条高效路径。然而,现有的 SAM 适配方法(如 VRP-SAM)主要依赖骨干网络提取的通用特征,忽略了 SAM 自身提示编码器(Prompt Encoder)的特征特性,且往往未能充分利用背景(负样本)信息来约束分割边界,导致生成的提示精度不足。
此外,视频领域的上下文分割研究尚处于空白阶段。现有的视频分割基准(如 DAVIS、MOSE)主要侧重于给定首帧掩码的半监督跟踪任务,缺乏评估 “基于参考示例进行视频分割” 能力的专用基准。
针对上述挑战,研究团队推出了首个视频上下文分割基准 IC-VOS,并同步提出了 DC-SAM 框架。该框架旨在通过提示微调技术,将 SAM 与 SAM2 的能力无缝迁移至这一新任务,实现了统一高效的图像与视频上下文分割。
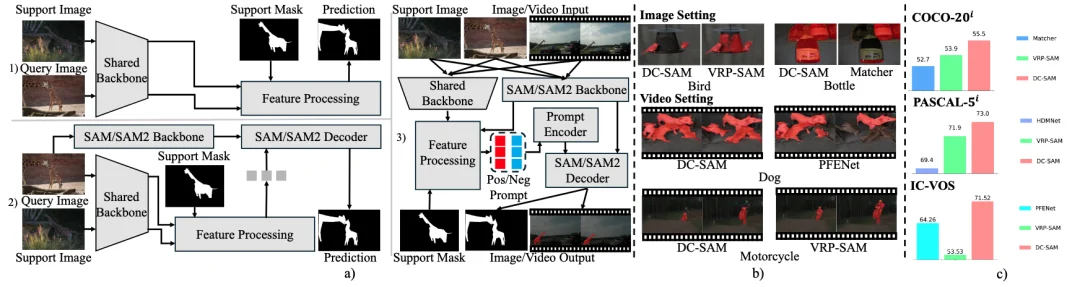
DC-SAM与现有方法的对比图。 a) 方法对比图,b) 预测可视化对比图,c)得分对比图。
在研究过程中,研究团队发现该领域缺乏一个专门用于评估 “上下文视频对象分割” 的统一基准。现有的 VOS 数据集大多侧重于第一帧掩码的追踪,而传统的 Few-shot 图像数据集则完全丢失了时间维度。
为了填补这一空白,研究团队推出了 IC-VOS (In-Context Video Object Segmentation) 数据集。这是首个旨在全面衡量模型在视频上下文中学习能力的数据集。IC-VOS 涵盖了极其丰富的场景,包括极小目标分割、快速运动变形以及复杂背景融合等。
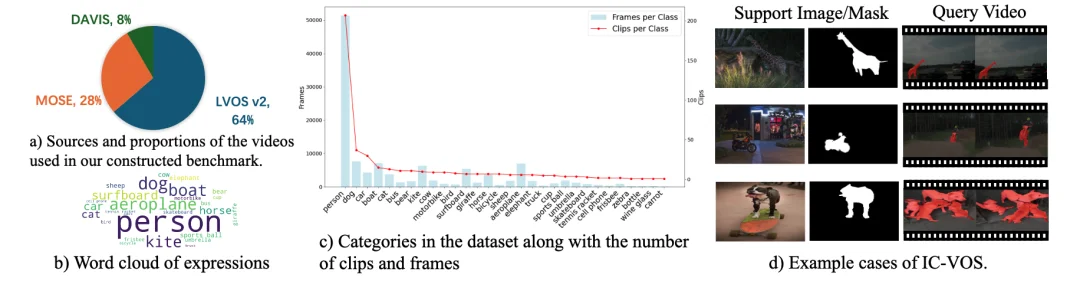
IC-VOS 分割基准:a) 数据来源,b) 词云图,c) 类别分布,d) 示例样本。
DC-SAM 框架由三个核心部分组成:基于 SAM 的特征融合、正负双分支循环一致性提示生成,以及面向视频的 Mask-tube 训练策略。该框架旨在充分利用 SAM 的特征空间,通过显式的正负样本约束和循环校验,生成高精度的视觉提示。
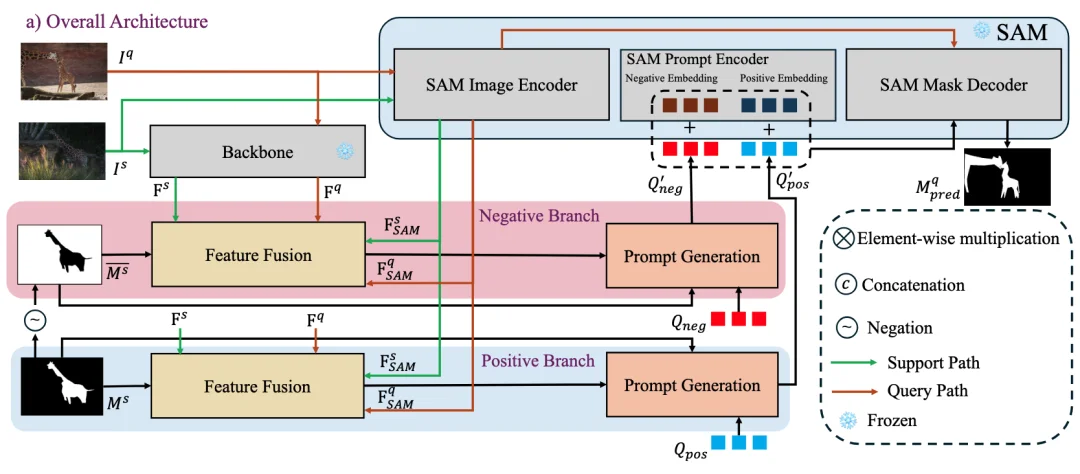
DC-SAM方法概览图。
基于 SAM 的特征融合
现有的上下文分割方法通常仅依赖于预训练骨干网络(如 ResNet 或 DINOv2)提取特征,这导致生成的 Prompt 与 SAM 内部的特征空间存在 “语义鸿沟”。

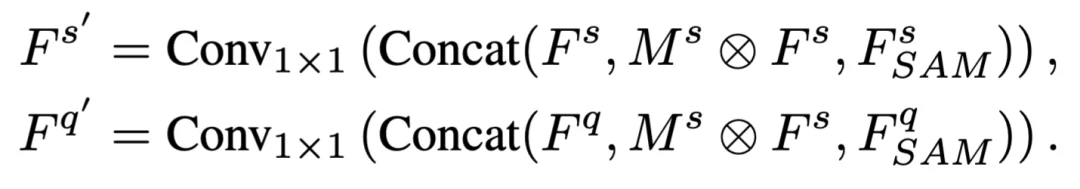

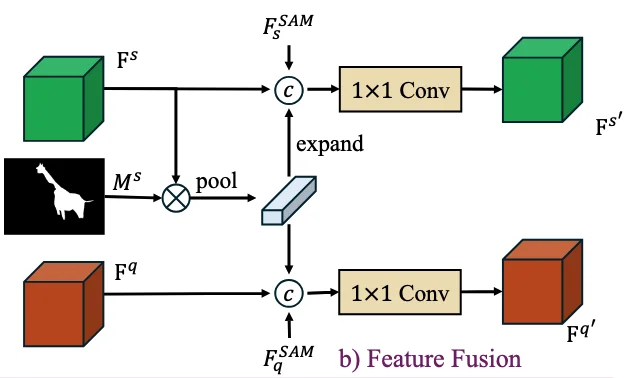
基于 SAM 的多源特征融合方法图
正负双分支循环一致性提示生成
正负双分支循环一致性提示生成是 DC-SAM 的核心模块。为了解决单一前景提示带来的边界模糊问题,研究团队设计了正负双分支(Dual-Branch)结构:

在每个分支内部,为了防止 “语义漂移”(即错误匹配非目标区域),研究团队引入了循环一致性交叉注意力(Cyclic Consistent Cross-Attention)。其核心思想是:只有当支持图像中的像素 j 与查询图像中的匹配像素 j* 满足语义类别一致时,才保留该注意力权重;否则,通过偏置项 B 将其屏蔽:
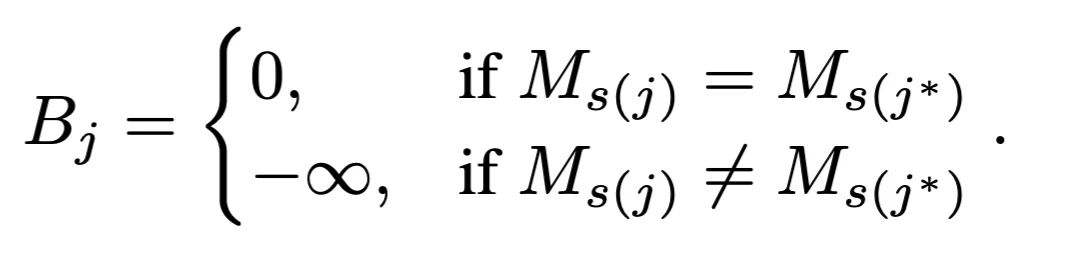
基于该偏置项,可以计算经过循环校验的注意力输出,确保生成的 Prompt 仅聚合高度可信的特征:
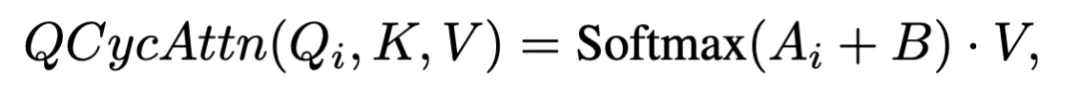
最终,正负分支生成的 Prompt 分别叠加 SAM 预训练的 Pos/Neg Embeddings,共同指导 Mask Decoder 生成精准掩码。
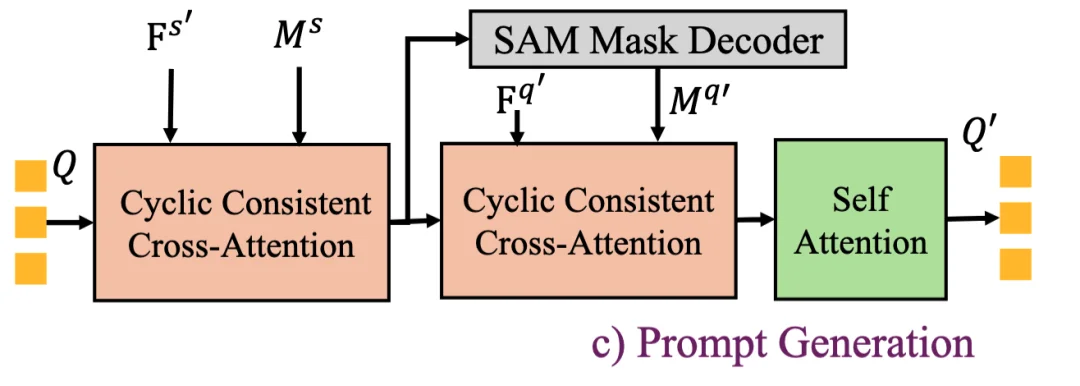
正负双分支循环一致性提示生成方法图
面向视频的 Mask-tube 训练策略及模型优化
得益于 SAM 与 SAM2 在 Prompt Encoder 上的架构一致性, DC-SAM 可以无缝迁移至视频领域。为了赋予模型处理时空动态的能力,研究团队设计了轻量级的 Mask-tube(掩码管道) 训练策略,通过数据增强将静态图像堆叠为伪视频序列,从而模拟连续帧之间的时序变化。
在优化阶段,无论是图像还是视频流的预测,均由二元交叉熵损失(BCE Loss)和相似度度量损失(Dice Loss) 共同约束。最终的总损失函数定义为两者的加权和,以平衡局部像素分类与整体区域重叠度的优化目标(超参数 λ 经验性地设置为 1):
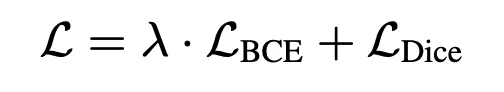
核心结果方面,DC-SAM 在图像上下文分割基准 COCO-20i 和 Pascal-5i 上取得显著性能优势。与基础视觉模型对比,即使面对使用了海量图文对训练的通用模型 SegGPT(56.1 mIoU),基于 DINOv2 的 DC-SAM 依然在 COCO-20i 上取得了 62.0 mIoU 的成绩,实现了近 6% 的性能反超,证明了所提出提示微调方法的泛化能力。与 基于 SAM 的方法对比,在同等骨干网络(ResNet50)下,DC-SAM 全面超越现有的 SAM 适配方法,即使对比最强的基准模型 VRP-SAM,也在COCO-20i 超越了 1.6%,证明 SAM 特征融合方法以及 Prompt 生成的有效性。
在团队首创的视频基准 IC-VOS 上,DC-SAM 取得了 71.52 的 J&F 得分,以 6.4% 的显著优势超越了 VRP-SAM,并大幅领先 PerSAM。这不仅充分验证了 Mask-tube 策略的有效性,更证明了循环一致性约束能有效抑制视频传播过程中的语义漂移,实现稳健的目标锁定。
为了直观评估模型性能,研究团队对 Pascal-5i 和 IC-VOS 上的分割结果进行了可视化分析。在图像任务中,DC-SAM 展现了对复杂结构和细粒度特征的强大捕捉能力。无论是 “瓶子” 的完整轮廓,还是 “鸟类” 的细微纹理,模型均能生成高精度的掩码;特别是在处理 “自行车” 和 “飞机” 等复杂物体时,DC-SAM 有效抑制了背景区域的误检(False Positives),边缘分割清晰锐利。

图像上下文分割效果对比图,黄色的叉表示明显错误。
在更具挑战的视频任务中,DC-SAM 的优势进一步凸显。以 “摩托车” 视频序列为例,基线模型 PFENet 出现了明显的语义漂移现象,不仅漏检了车轮,还错误地将骑手包含在分割目标内。相比之下,DC-SAM 能够精准区分干扰对象(如骑手)与目标主体,在连续帧中实现了稳健的语义锁定与追踪。

视频上下文分割效果对比图。
我们相信,DC-SAM 的提出为视觉大模型的落地应用,尤其是在需要高效、自动处理海量视频数据的工业与科研领域,提供了极具竞争力的解决方案。
齐梦实,北京邮电大学计算机学院,教授、博导。博士毕业于北京航空航天大学,美国罗切斯特大学联合培养博士。曾工作于瑞士洛桑联邦理工学院CVLAB担任博士后研究员,百度研究院访问研究员等。入选2021年第七届中国科协青年人才托举工程(中国人工智能学会)、2024年小米青年学者、2025年ACM北京分会新星奖。主要研究方向为人工智能、计算机视觉和多媒体智能计算等。作为主要负责人承担国家自然科学基金(面上/青年)、北京市自然科学基金-小米创新联合基金、腾讯犀牛鸟课题、小米、阿里、微软合作项目等,并作为核心研发人员参与了国家自然科学基金重大/重点项目、科技部重点专项和港澳台科技专项等,发表国际高水平期刊会议论文50余篇,包括顶级学术会议CVPR/ICCV/ECCV/NeurIPS/ACM MM/AAAI和权威学术期刊TPAMI/TIP/TMM/TCSVT/TIFS等,担任顶级会议AAAI、IJCAI的领域主席和TMM的特邀编辑。
毕萧扬,北京邮电大学计算机学院,硕士研究生。主要研究方向为人工智能、计算机视觉和自动驾驶等。作为核心研究人员参与北京市自然科学基金-小米创新联合基金、腾讯犀牛鸟课题等重点科研项目。发表的国际高水平论文成果收录于权威学术期刊TPAMI和顶级学术会议UbiComp。
文章来自于“机器之心”,作者 “机器之心”。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
