# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
去年下半年,模型界最大的惊喜莫过于Sora 2和Veo 3,他们已经把视频生成推到了新高度:光影完美,纹理细腻,甚至有着很高的时空一致性。
但抽卡依然不可避免。因为很多原有的瑕疵,比如穿模、遮挡后跳跃、诡异的互动抽动依然难以避免。你仍然可以在其中看到衣物穿进身体、手指两帧之间换了交叉位置、物体边缘细微抽动、脚步在地面上滑一下又黏回去的情形。


它们不一定显眼,却足以破坏真实性。
这些瑕疵其实有共同的根源,模型能把每一帧画得越来越像,但对「同一个点在三维空间里如何随时间连续运动」的理解仍然有限。
今年1月Deepmind的一篇论文《Do generative video models understand physical principles?》考察了上一代SOTA视频模型,如Sora、Runway Gen3等后,认为视频生成模型在物理理解方面非常有限,而且高逼真并不保证高物理一致性。
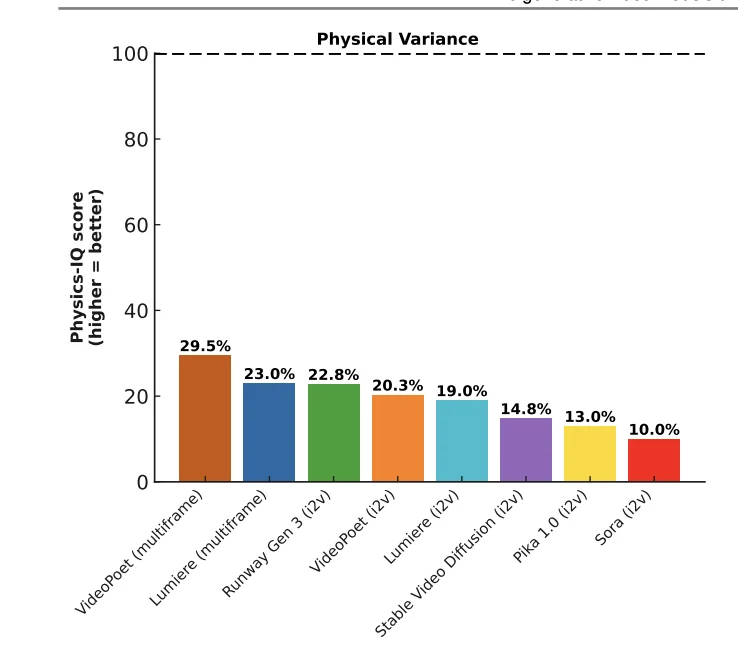
比如Sora,它生成的视频对于其他模型来讲最难分辨真假,但在物理理解测试(Physics-IQ Score)中,Sora 的得分却是最低的。
这至少说明,今天最先进的视频生成仍然在很大程度上做的是「逐帧合理化」,而不是在内部维护一个稳定的世界结构。
理解世界结构,本身是分几个层面的,对主体的认知、对运动的认知和对物理规则的认知。目前的模型对运动的认知很不完善,物理规则更是有很远差距。
要解决这个问题,其中最直接的方法之一,就是从扁平的 2D 视频中,强制提取出坚硬的 3D 骨架和时间维度。也就是可持续的 4D(3D + 时间)几何约束。之后,把这种约束以数据的形式教给模型。
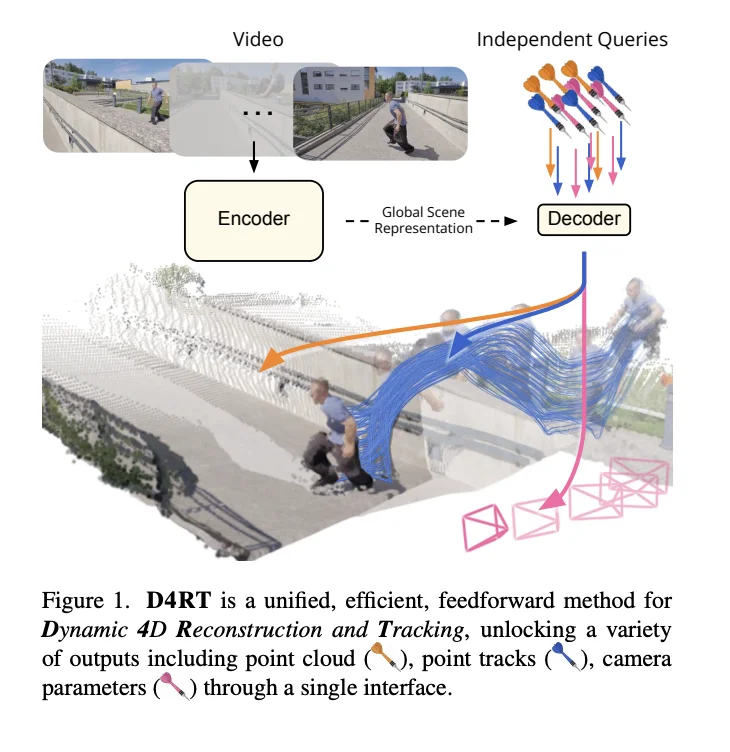
DeepMind 的新论文《Efficiently Reconstructing Dynamic Scenes One D4RT at a Time》正是为这一方法建立了一个地基。它让我们能从一段普通视频里,又快又统一地恢复一个动态场景的 4D 几何。

这样我们就可能把运动轨迹该怎么走、遮挡该怎么发生、点在 3D 里连续移动变成一种可以规模化生产的训练信号,让生成模型别再靠“看起来差不多”蒙混过关。
过去学界其实有两派做路径重建的方法。
第一个是重建派。他们的核心逻辑就是「只要把每一帧的 3D 世界都完美造出来,运动轨迹自然就有了」。
比如SfM/MVS(Structure-from-Motion / Multi-View Stereo),它们比较像老派的测绘员。它们依靠数据模型,通过对比不同角度的照片来算出点的大概3D位置。之后再通过多轮模块化去重建整个3D世界。
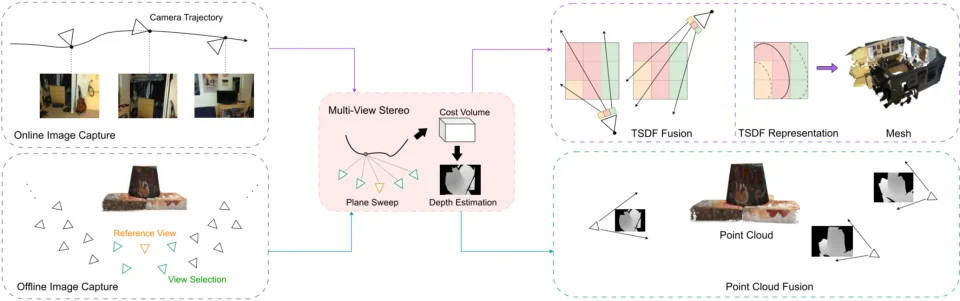
但他们极其依赖视角的移动。如果摄像机不动,只有画面里的人在动,经典假设下它们就彻底无解了,算不出深度。
还有现在最流行的NeRF,它是用神经网络去表示空间中每个点的密度与颜色,然后通过渲染让预测图像和真实图像一致。在构建4D场景时,动态 NeRF 会引入时间、形变场(warp field)。NeRF 的 KPI 是画得像,而不是位置准,几何一致性往往是间接目标,因此在动态场景上更容易出现身份漂移。只要渲染出来的图骗过人眼就行,至于这个点在上一秒和下一秒是不是同一个物理点,它并不关心。
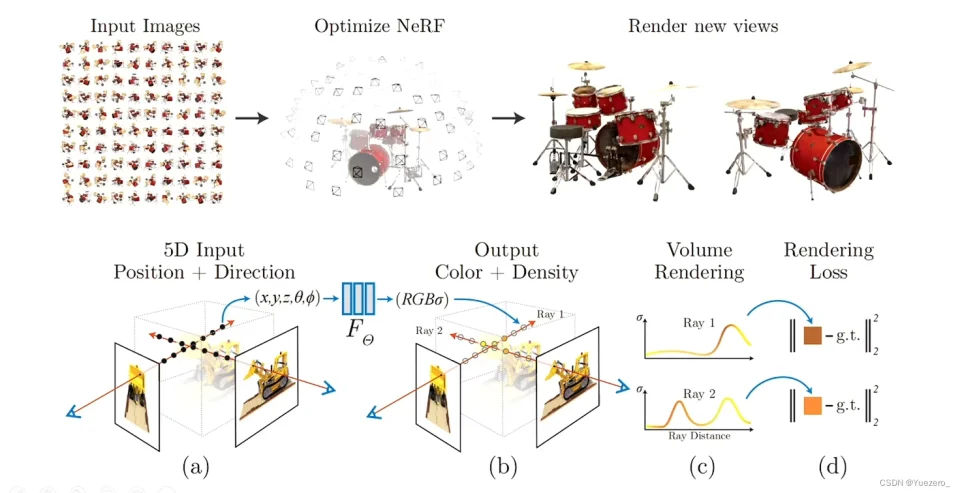

所以你经常发现,NeRF 重建的场景里,物体的运动轨迹是断裂或漂移的——看着像连上了,其实物理上没连上。
除此之外,这种重构方法还有一个巨大的BUG,就是想知道一个点在哪,NeRF 必须把整张图重新渲染一遍。你想知道某个路人甲在哪,却非要剧组把整场戏重新演一遍,这成本太离谱了。
另一类是跟踪型,比如光流、点跟踪、scene flow。
这套方法最初是用来追踪2D点的,它们不关心背景怎么样,只盯着画面里的某一个像素点,看它下一帧移动到了哪里。而scene flow给2D加了一层深度坐标,因此可以大致判断这个点在不同时间的3D位置。
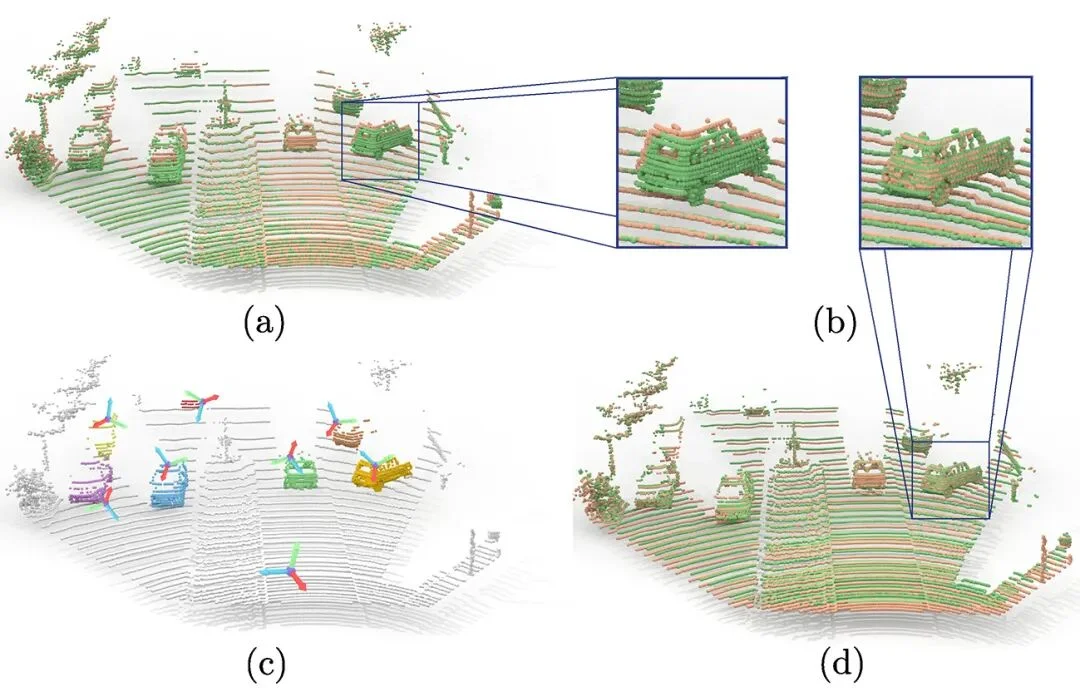
这套3D追踪方法天生是以镜头为中心的。它们测量的是这个点离镜头近了还是远了,而非构建一个统一的 3D 坐标系。一旦摄像机晃动,所有的轨迹数据都会乱成一锅粥。
造景派太重,且为了画得像牺牲了物理上的跟得准;跟踪派太轻,只盯着局部,一旦镜头晃动就容易迷失方向。对于「同一个点在某个时间上在哪里」这个问题,它们都缺乏一个跨时间、跨视角都一致的坐标系。
而DeepMind提出的 D4RT 用了一个非常简单、但非常关键的方法建立这个统一坐标系。它把 4D 几何重建改写成「在指定坐标系下回答点查询(query)」的问题。
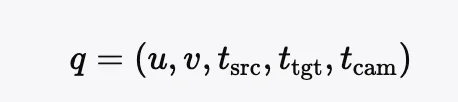
在 D4RT 的系统中,当你想要查询一个点时,必须向模型输入三个明确的指令:
1. 身份(Who): 我选定了第几帧里的哪个像素点? (u,v, tsrc)
2. 时间(When): 我想知道它在哪个时刻的位置? (ttgt)
3. 参照系(Where): 请用哪个时刻的相机坐标系来回答我? (tcam)
第三个参数 cam 是这个定位里的关键。
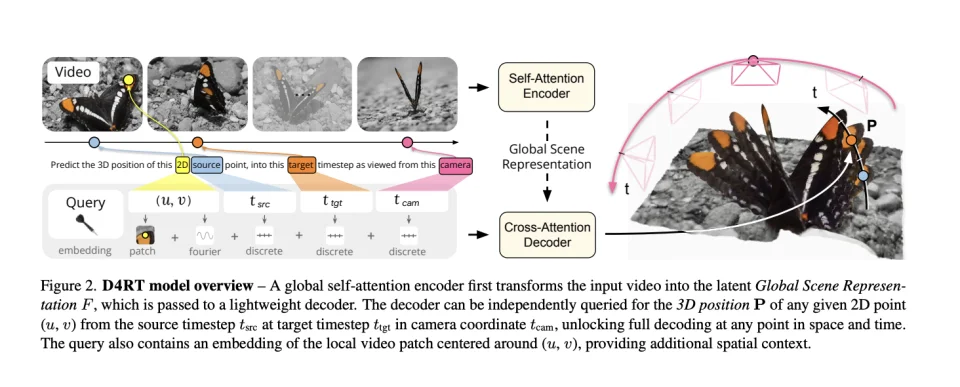
在传统的跟踪派方法中,坐标系是随着相机乱动的,导致轨迹很难统一。但在 D4RT 里,我们只需要把 tcam强制固定(比如永远设为第 0 帧),这就相当于给了这个不断晃动的世界一个稳定的锚点坐标系。
这样,无论视频里的相机怎么晃,无论物体怎么跑,所有的计算结果都被强制拉回到这个「世界原点」进行表达。在这样一种强约束之下,跨时间、跨视角的一致性不再需要后期复杂的数学修补,而是变成了任务定义的一部分。不同时刻的轨迹天然就在同一个世界里,可以直接比较、积累。
这种查询模式还顺手解决了重建派(如 NeRF)的身份断裂问题。
这个模型的询问定义中,允许你去问「第 1 帧的这个像素,在第 100 帧在哪里?」这样的问题,为了回答这个问题,模型被强迫去维护一个稳定的身份逻辑。它必须理解,第 100 帧里的那个点,必须是第 1 帧那个点的物理延续,而不能是一个凭空出现的点。
这迫使模型在潜空间里学会真正的物体恒常性,而不是仅仅把两张图渲染得看起来像。
为了实现这个逻辑,D4RT 搭建了一套端到端的编解码 架构,把任务拆解为阅读和回答两步。
● 编码器(Encoder): 负责“读”。它把整段视频吃进去,通过 Vision Transformer (ViT) 进行处理,压缩成一个包含了时空信息的全局场景表征(Global Scene Representation) 。
● 解码器(Decoder): 负责“答”。这是一个轻量级的模块。你给它一个查询探针,包含你想查询的像素位置、时间以及相机视角,它就直接从全局表征里检索出对应的 3D 坐标 。
这种设计让 D4RT 绕过了传统方法中繁重的逐帧解码计算 。它不需要一次性算出所有像素,而是你需要哪里就算哪里。更重要的是,它统一了所有任务。点云、轨迹、相机姿态,在 D4RT 眼里,本质上都是同一个数学问题 。
我们现在有了一套能够定位时空统一的坐标查询系统。需要的就是训练这个模型,让它能够回答统一参考相机坐标系下的 (x,y,z),包含深度和3D 信息。
方法就是训练模型,让它能够把这套坐标和3D结构端到端的建立起对应关系。
DeepMind 的团队采用了一种非常暴力的混合训练策略。训练集混合了公开数据集和Google内部数据,包括BlendedMVS、Co3Dv2、Dynamic Replica、Kubric、ScanNet、Waymo Open等等。这些数据集覆盖了静态场景、动态场景、室内、室外、真实数据、合成数据。
对于生成模型来说,真实视频是最好的。但对于重建模型来说,合成数据可能更好用。因为在里面能精确地知道每一个像素的深度、每一只兔子的运动轨迹、每一次相机的抖动幅度。这种完美的 Ground Trut,是训练 D4RT 理解复杂物理运动的基石。
为了让模型真正学会“物理”,DeepMind 设计了一套极其复杂的组合损失函数(Loss Function) 。模型不仅要算出答案,还要证明过程是合理的。
它需要保证3D 位置要准、经过2D算出来的3D点投影回画面,必须要能严丝合缝地落在原来的像素上。
模型还需要输出一个信心度。对于那些没有纹理的白墙或者模糊的运动边缘,模型被允许不自信,但在能算准的地方必须自信 。
除了宏观架构,论文还用一些小工程技巧解决了压缩问题。研究人员发现,如果只告诉解码器像素坐标,它算出来的深度图往往边缘模糊。于是,他们在查询向量里硬塞进去了以该点为中心的一个9X9的微小图像块,这被他们称为局部 RGB Patch(Local RGB Patch)。这些 RGB 像素提供了纹理和颜色信息,让模型能够瞬间识别出细微的纹理和框架,从而重建出极其锐利的 3D 细节 。
效果怎么样?论文里测了一堆benchmark,我挑了几个最能说明问题的。
作为重建派的代表,MegaSaM 试图重建一只游过水面的天鹅时,它在每一帧里都根据天鹅的位置建了一个静态雕像,最终的画面里出现了一排由天鹅残影组成的队列。另一种尝试π³的表现则极不稳定,面对结构复杂的动态物体(比如一朵风中的花),它有时候会选择直接躺平,导致重建结果里的物体离奇消失。而作为跟踪派代表的 SpatialTrackerV2 虽然理解天鹅在动,但它只能追踪第一帧里看得到的点,一旦天鹅向前游动露出了原本被遮挡的水面,或者火车开走露出了铁轨,它就束手无策了,导致场景中留下了大片的空洞和黑斑 。
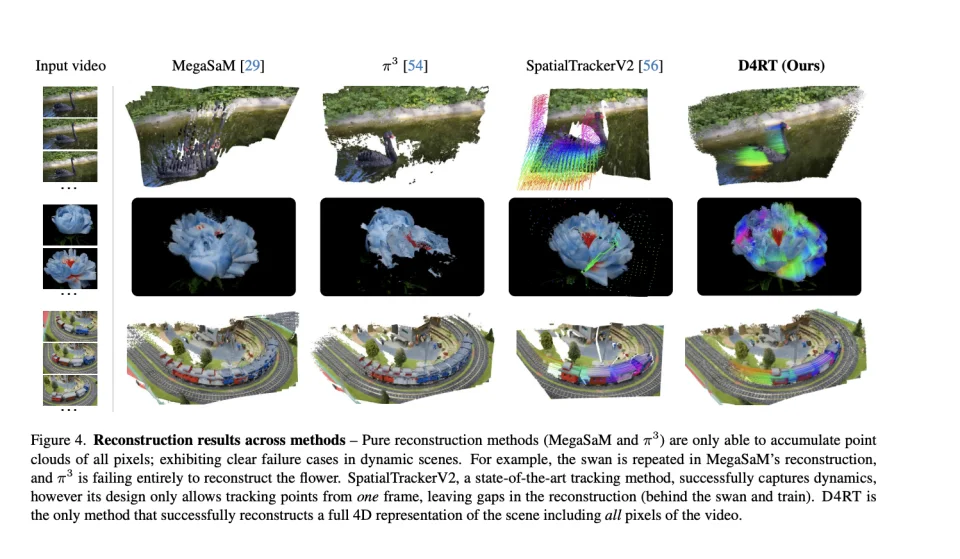
唯独 D4RT 交出了一份令人满意的答卷。它不仅完美还原了动态物体的运动轨迹,还自动补全了被遮挡的背景,没有鬼影,也没有空洞,呈现出一个完整、连续且逻辑自洽的 4D 场景 。
在权威的 TAPVid-3D 数据集上,D4RT 展现了代差级的优势 。在相机坐标系 3D 追踪任务中,D4RT 的平均 Jaccard 指数(AJ)高达 0.257,而之前的冠军 SpatialTrackerV2 仅为 0.064,这意味着追踪精度直接翻了四倍 。在更具挑战性的世界坐标系追踪任务中,D4RT 的准确率(APD3D)达到 0.373,几乎是第二名竞争对手(0.201)的两倍 。
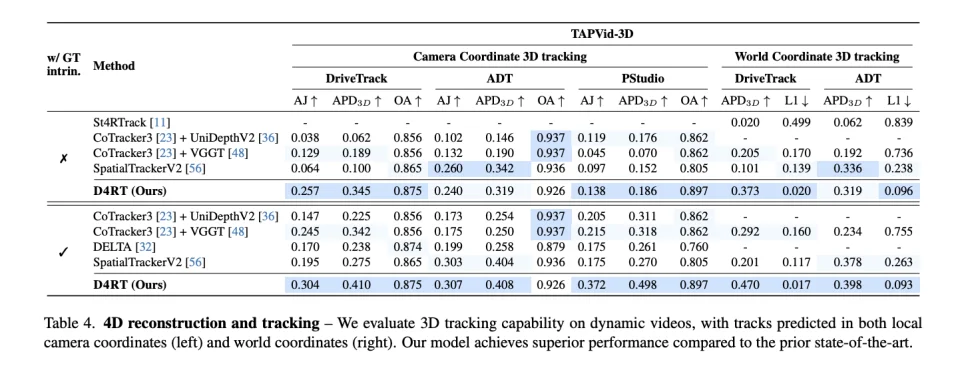
类似的优势也延续到了深度估计和相机姿态估计上。面对包含大量动态物体的 Sintel 数据集,D4RT 的深度估计误差(AbsRel)被压低到了 0.171,而 MegaSaM 的误差高达 0.342,相当于测距精度提升了一倍 。在相机姿态估计方面,D4RT 的绝对平移误差(ATE)仅为 0.065,也显著优于此前最好的竞品π³(0.086) 。
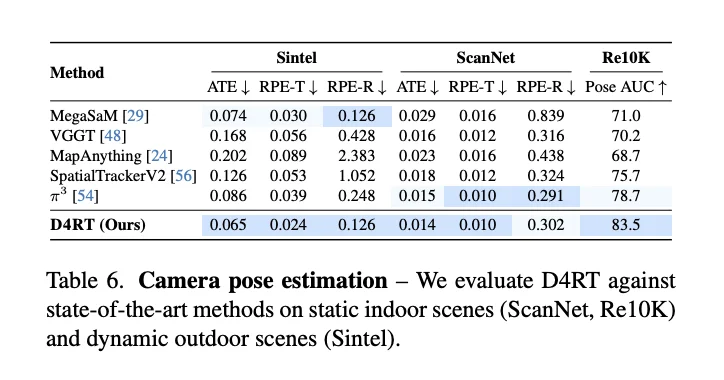
无论是凭肉眼看疗效,还是用数据跑分,D4RT 都无可争议地证明了一件事:在动态的 4D 世界重建中,它目前没有对手。
最重要的是速度上的碾压。在 A100 GPU 上,D4RT 的姿态估计速度飙升到了 200 FPS 。作为对比,之前的 SOTA 方法 MegaSaM 只有不到 1 FPS 。这不是快了一点点,这是两个数量级的碾压。
既然 D4RT 是用来“还原”的,它和用来“创造”的 Sora 有什么关系?
关系很大。D4RT 很可能就是生成模型进化到下一阶段的关键拼图,因为它提供的是几何/运动一致性的可规模化信号。
目前生成模型非常擅长处理「面子上的事儿」。得益于对海量图像数据的暴力吞吐,它们非常擅长渲染复杂的纹理、材质反射和柔和的阴影。毕竟,光度和纹理在每一帧里都是显而易见的像素统计规律。
但一旦涉及运动、遮挡和物理轨迹,这些模型就有点拉垮。比如在Sora2这种顶尖模型里,人物的肢体还是会在转身时发生形变漂移,被遮挡的物体再出现时像是换了个样子,物体的运动轨迹常常违背惯性定律。
这是目前的模型缺乏一种跨时间的身份约束,它们不知道那个被树挡住的车,和三秒后钻出来的车,必须是同一个刚体。
而在这种“光影强、物理弱”的尴尬局面下,D4RT的价值就显现出来了。生成模型的弱点,正是它最擅长的部分。因此,用既便宜又准确的它来负责教模型「守规矩」非常合适。
在工程层面它至少有两种极具潜力的应用。
1. 伪标签生成器:以往我们要给视频打上 3D 标签,成本高到无法想象。但 D4RT 的推理速度极快,这意味着我们可以用它把数百万小时的 YouTube 视频刷一遍,生成出每一帧的点级 3D 轨迹、深度图和遮挡关系。 我们将这些 D4RT 生成的数据作为伪标签喂给视频生成模型。有了这些标注,模型就不再只是模仿像素的流动,而是被明确告知「这个点的轨迹必须是平滑的」、「那个点被遮挡时不要试图硬画」。这种监督信号直接对准了「抖动」和「穿模」的高发区。
2. 生成质量监督官:现在的视频生成模型很难评测。D4RT 可以变成一个自动化的评分模型(几何一致性评估器)。 当 Sora 生成一段视频后,我们可以把它扔给 D4RT。如果 D4RT 发现某个物体的轨迹出现了瞬间位移,或者重投影误差过大,就说明这段视频物理不自洽。这个反馈可以直接用于筛选采样,在训练中惩罚那些违背物理常识的生成结果,迫使模型去生成更符合现实逻辑的视频。
归根结底,D4RT 回应了视频生成领域当下的核心焦虑:我们已经把单帧的画质推到了极致,再往上堆纹理细节,边际效应已经递减。现在的破绽,更多来自跨帧的世界结构是否崩塌。
要补上这块短板,靠模型自己从像素里悟出物理规律太慢也太不稳定。D4RT把昂贵的 4D 几何重建变成了一种轻量级、可查询、可规模化的监督信号,在一定程度上可以帮助生成模型更快的领悟世界模型。
它并不保证你立刻得到物理仿真级的碰撞与反作用。那需要更强的动力学建模、接触约束甚至仿真数据。
但它可能带来一种更务实的改善。比如少一点抽动、少一点穿帮、少一点遮挡处的瞬移。
在今天视频生成的阶段,这类改善比纹理细节更重要,它决定了你会不会相信「这个世界真的连贯存在」。
文章来自于“腾讯科技”,作者 “郝博阳”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
